


Hadoop学习笔记—14.ZooKeeper环境搭建
Hadoop学习笔记—14.ZooKeeper环境搭建
从字面上来看,ZooKeeper表示动物园管理员,这是一个十分奇妙的名字,我们又想起了Hadoop生态系统中,许多项目的Logo都采用了动物,比如Hadoop采用了大象的形象,所以我们可以猜测ZooKeeper就是对这些动物进行一些管理工作的。
一、ZooKeeper基础介绍
1.1 动物园也要保障安全

zookeeper是hadoop下面的一个子项目,用来协调跟hadoop相关的一些分布式的框架,如hadoop, hive, pig等, 其实他们都是动物,所以叫zookeeper ——“动物园管理员”。 动物园里当然有好多的动物,游客可以根据动物园提供的向导图到不同的场馆观赏各种类型的动物,而不是像走在原始丛林里,心惊胆颤的被动物所观赏。为了让各 种不同的动物呆在它们应该呆的地方,而不是相互串门,或是相互厮杀,就需要动物园管理员按照动物的各种习性加以分类和管理,这样我们才能更加放心安全的观 赏动物。
1.2 进程内的协调方法
在实际应用中,Zookeeper主要是针对大型分布式系统进行高可靠的协调。由这个定义我们知道zookeeper是个协调系统,作用的对象是分布式系统。 说到协调,我们可以联想到的现实生活中很多十字路口的交通协管,他们手握着小红旗,指挥车辆和行人是不是可以通行。如果我们把车辆和行人比喻成运行在计算 机中的单元(线程),那么这个协管是干什么的?很多人都会想到,这不就是锁么?对,在一个并发的环境里,我们为了避免多个运行单元对共享数据同时进行修 改,造成数据损坏的情况出现,我们就必须依赖像锁这样的协调机制,让有的线程可以先操作这些资源,然后其他线程等待。对于进程内的锁来讲,我们使用的各种 语言平台都已经给我们准备很多种选择。例如在C#中,最常用的莫过于借助语法糖lock构造同步块:

int Withdraw(int amount)
{
if (balance < 0)
{
throw new Exception("Negative Balance");
}
lock(thisLock)
{
if (balance >= amount)
{
Console.WriteLine("Balance before Withdrawal : " + balance);
Console.WriteLine("Amount to Withdraw : -" + amount);
balance = balance - amount;
Console.WriteLine("Balance after Withdrawal : " + balance);
return amount;
}
else
{
return 0;
}
}
}
1.3 分布式环境中的协调
在进程内进行协调我们可以使用语言,平台,操作系统等为我们提供的机制。那么如果我们在一个分布式环境中呢?也就是我们的程序运行在不同的机器 上,这些机器可能位于同一个机架,同一个机房又或不同的数据中心。在这样的环境中,我们要实现协调该怎么办?那么这就是分布式协调服务要干的事情。
于是,Google创造了Chubby,而ZooKeeper则是对于Chubby的一个开源实现。


Definition:ZooKeeper是一种为分布式应用所设计的高可用、高性能且一致的开源协调服务,它提供了一项基本服务:分布式锁服务。由于ZooKeeper的开源特性,后来我们的开发者在分布式锁的基础上,摸索了出了其他的使用方法:配置维护、组服务、分布式消息队列、分布式通知/协调等。
1.4 ZooKeeper的应用场景
(1)统一命名服务
有一组服务器向客户端提供某种服务(例如:使用LVS技术构建的Web网站集群,就是由N台服务器组成的集群,为用户提供Web服务),我们希 望客户端每次请求服务端都可以找到服务端集群中某一台服务器,这样服务端就可以向客户端提供客户端所需的服务。对于这种场景,我们的程序中一定有一份这组 服务器的列表,每次客户端请求时候,都是从这份列表里读取这份服务器列表。那么这分列表显然不能存储在一台单节点的服务器上,否则这个节点挂掉了,整个集 群都会发生故障,我们希望这份列表时高可用的。高可用的解决方案是:这份列表是分布式存储的,它是由存储这份列表的服务器共同管理的,如果存储列表里的某 台服务器坏掉了,其他服务器马上可以替代坏掉的服务器,并且可以把坏掉的服务器从列表里删除掉,让故障服务器退出整个集群的运行,而这一切的操作又不会由 故障的服务器来操作,而是集群里正常的服务器来完成。这是一种主动的分布式数据结构,能够在外部情况发生变化时候主动修改数据项状态的数据机构。 Zookeeper框架提供了这种服务。这种服务名字就是:统一命名服务,它和javaEE里的JNDI服务很像。
(2)分布式锁服务
当分布式系统操作数据,例如:读取数据、分析数据、最后修改数据。在分布式系统里这些操作可能会分散到集群里不同的节点上,那么这时候就存在数 据操作过程中一致性的问题,如果不一致,我们将会得到一个错误的运算结果,在单一进程的程序里,一致性的问题很好解决,但是到了分布式系统就比较困难,因 为分布式系统里不同服务器的运算都是在独立的进程里,运算的中间结果和过程还要通过网络进行传递,那么想做到数据操作一致性要困难的多。 Zookeeper提供了一个锁服务解决了这样的问题,能让我们在做分布式数据运算时候,保证数据操作的一致性。
(3)配置管理
在分布式系统里,我们会把一个服务应用分别部署到n台服务器上,这些服务器的配置文件是相同的(例如:我设计的分布式网站框架里,服务端就有4 台服务器,4台服务器上的程序都是一样,配置文件都是一样),如果配置文件的配置选项发生变化,那么我们就得一个个去改这些配置文件,如果我们需要改的服 务器比较少,这些操作还不是太麻烦,如果我们分布式的服务器特别多,比如某些大型互联网公司的hadoop集群有数千台服务器,那么更改配置选项就是一件 麻烦而且危险的事情。这时候zookeeper就可以派上用场了,我们可以把zookeeper当成一个高可用的配置存储器,把这样的事情交给 zookeeper进行管理,我们将集群的配置文件拷贝到zookeeper的文件系统的某个节点上,然后用zookeeper监控所有分布式系统里配置 文件的状态,一旦发现有配置文件发生了变化,每台服务器都会收到zookeeper的通知,让每台服务器同步zookeeper里的配置文 件,zookeeper服务也会保证同步操作原子性,确保每个服务器的配置文件都能被正确的更新。
可以看出,zookeeper是一个典型的观察者模式的应用。
(4)集群管理
集群管理是很困难的,在分布式系统里加入了zookeeper服务,能让我们很容易的对集群进行管理。集群管理最麻烦的事情就是节点故障管理,zookeeper 可以让集群选出一个健康的节点作为master,master节点会知道当前集群的每台服务器的运行状况,一旦某个节点发生故障,master会把这个情 况通知给集群其他服务器,从而重新分配不同节点的计算任务。Zookeeper不仅可以发现故障,也会对有故障的服务器进行甄别,看故障服务器是什么样的 故障,如果该故障可以修复,zookeeper可以自动修复或者告诉系统管理员错误的原因让管理员迅速定位问题,修复节点的故障。大家也许还会有个疑 问,master故障了,那怎么办了?zookeeper也考虑到了这点,zookeeper内部有一个“选举领导者的算法”,master可以动态选 择,当master故障时候,zookeeper能马上选出新的master对集群进行管理。
PS:关于Master的选举,可以浏览Suddenly的这篇:http://www.cnblogs.com/sunddenly/p/4033574.html,其文章有一部分叫做分布式锁应用场景,对于Master选举有一个详细的介绍。
二、ZooKeeper集群模式环境搭建
2.1 ZooKeeper集群模式典型架构
(1)典型架构图如下所示:
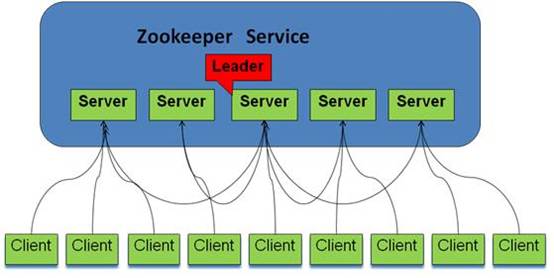
(2)本次试验架构图如下所示:
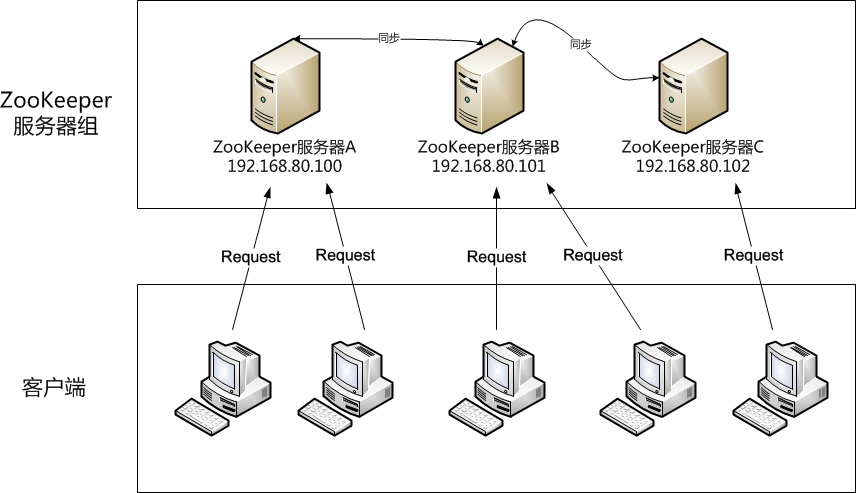
2.2 ZooKeeper集群模式搭建步凑
注意:ZooKeeper服务器集群规模不小于3个节点,要求各服务器之间系统时间要保持一致;
(1)通过FTP工具上传ZooKeeper安装包,我这里使用的是3.4.5版本:
下载地址:http://pan.baidu.com/s/1qWyoFhU
(2)解压ZooKeeper安装包,并将解压后的文件夹名称改为zookeeper:
①tar -zvxf zookeeper-3.4.5.tar.gz
②mv zookeeper-3.4.5 zookeeper
(3)修改环境变量:vim /etc/profile
①增加一行:export ZOOKEEPER_HOME=/usr/local/zookeeper
②修改PATH:export PATH=.:$HADOOP_HOME/bin:$ZOOKEEPER_HOME/bin:$JAVA_HOME/bin:$PATH
③使配置生效:source /etc/profile
(4)进入zookeeper的conf目录下,修改文件名:mv zoo_sample.cfg zoo.cfg
(5)编辑zoo.cfg:vim zoo.cfg
①修改dataDir=/usr/local/zookeeper/data
②新增server.0=hadoop-master:2888:3888
server.1=hadoop-slave1:2888:3888
server.2=hadoop-slave2:2888:3888
(6)创建data文件夹,并创建myid文件:
①新建data文件夹:mkdir /usr/local/zookeeper/data
②新建myid文件:vim myid,并设置第一台server为0。
(7)复制zookeeper目录至其余两台服务器中:
①scp /usr/local/zookeeper hadoop-slave1:/usr/local/
②scp /usr/local/zookeeper hadoop-slave2:/usr/local/
(8)复制环境变量配置文件至其余两台服务器中:
①scp /etc/profile hadoop-slave1:/etc
②scp /etc/profile hadoop-slave2:/etc
(9)在其余两台服务器中修改myid文件:设置为1和2;
(10)启动ZooKeeper,分别在三个节点中执行命令:zkServer.sh start



(11)检验ZooKeeper集群节点角色状态,分别在三个节点中执行命令:zkServer.sh status



Role:ZooKeeper中包含以下角色:
①领导者(leader),负责进行投票的发起和决议,更新系统状态;②学 习者(learner),包括跟随者(follower)和观察者(observer),follower用于接受客户端请求并想客户端返回结果,在选主 过程中参与投票;observer可以接受客户端连接,将写请求转发给leader,但observer不参加投票过程,只同步leader的状 态,observer的目的是为了扩展系统,提高读取速度;
三、ZooKeeper简单测试
搭建好集群环境后,就可以进行简单的读写一致性测试了,这里我们通过进入zookeeper的bin目录下的zkCli.sh来完成下面的操作:
(1)在其中一个节点192.168.80.100上执行一个写操作:create /MyTest test
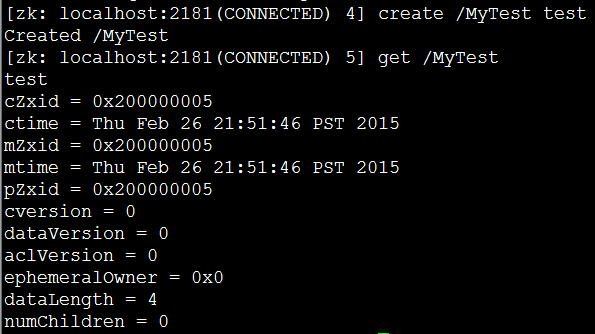
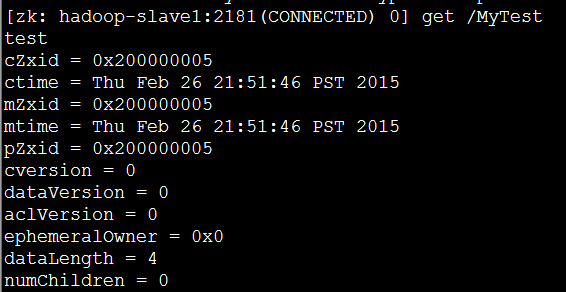
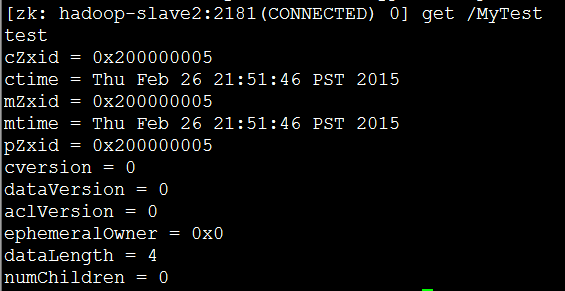
(2)在其他两个节点上执行读操作:get /MyTest
TIP:可以在一个节点中通过zkCli.sh -server hadoop-slave1:2181来远程登录
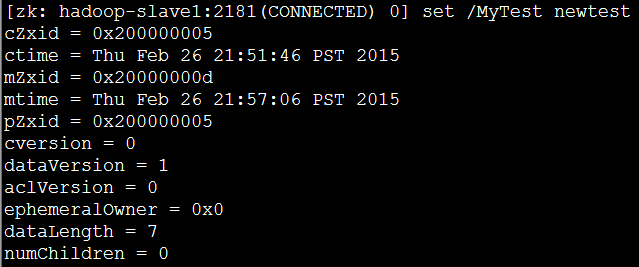
(3)在其中一个节点192.168.80.101上执行一个修改操作:
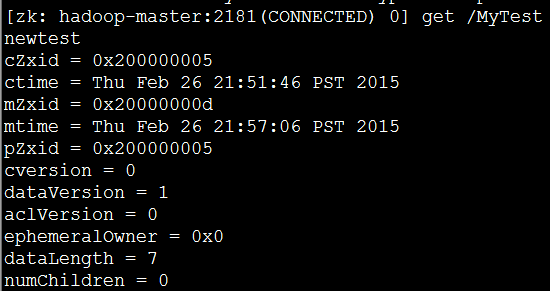
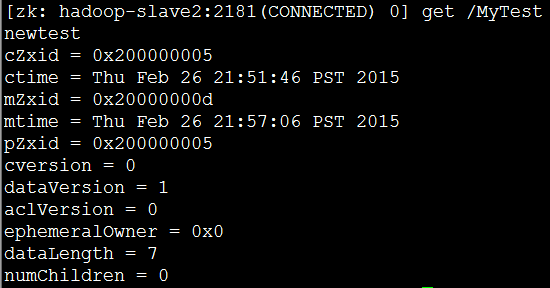
(4)在其他两个节点上执行读操作:
参考资料
(1)张善友,《zookeeper分布式锁服务》:http://www.cnblogs.com/shanyou/archive/2012/09/22/2697818.html
(2)夏天的森林,《分布式网站架构后续:zookeeper技术浅析》:http://www.cnblogs.com/sharpxiajun/archive/2013/06/02/3113923.html
(3)横刀天笑,《Zookeeper—Zookeeper是什么?》:http://www.cnblogs.com/yuyijq/p/3391945.html
(4)Suddenly,《Hadoop日志Day20—ZooKeeper》:http://www.cnblogs.com/sunddenly/p/4033574.html
posted on 2015-11-18 17:02 1130136248 阅读(219) 评论(0) 编辑 收藏 举报


