


Hadoop学习笔记—7.计数器与自定义计数器
Hadoop学习笔记—7.计数器与自定义计数器
一、Hadoop中的计数器
计数器:计数器是用来记录job的执行进度和状态的。它的作用可以理解为日志。我们通常可以在程序的某个位置插入计数器,用来记录数据或者进度的变化情况,它比日志更便利进行分析。
例如,我们有一个文件,其中包含如下内容:
hello you
hello me
它被WordCount程序执行后显示如下日志:
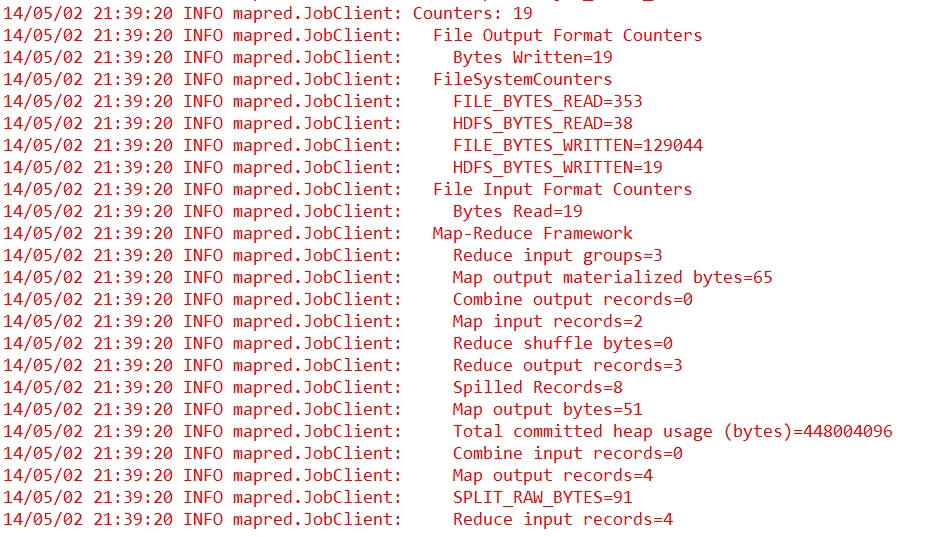
在上图所示中,计数器有19个,分为四个组:File Output Format Counters、FileSystemCounters、File Input Format Counters和Map-Reduce Framkework。
分组File Input Format Counters包括一个计数器Bytes Read,表示job执行结束后输出文件的内容包括19个字节(空格、换行都是字符),如下所示。
hello 2
me 1
you 1
分组File Output Format Counters包括一个计数器Bytes Written,表示job执行时读取的文件内容包括19个字节(空格、换行都是字符),如下所示。
hello you
hello me
关于以上这段计数器日志中详细的说明请见下面的注释:

1 Counters: 19 // Counter表示计数器,19表示有19个计数器(下面一共4计数器组)
2 File Output Format Counters // 文件输出格式化计数器组
3 Bytes Written=19 // reduce输出到hdfs的字节数,一共19个字节
4 FileSystemCounters// 文件系统计数器组
5 FILE_BYTES_READ=481
6 HDFS_BYTES_READ=38
7 FILE_BYTES_WRITTEN=81316
8 HDFS_BYTES_WRITTEN=19
9 File Input Format Counters // 文件输入格式化计数器组
10 Bytes Read=19 // map从hdfs读取的字节数
11 Map-Reduce Framework // MapReduce框架
12 Map output materialized bytes=49
13 Map input records=2 // map读入的记录行数,读取两行记录,”hello you”,”hello me”
14 Reduce shuffle bytes=0 // 规约分区的字节数
15 Spilled Records=8
16 Map output bytes=35
17 Total committed heap usage (bytes)=266469376
18 SPLIT_RAW_BYTES=105
19 Combine input records=0 // 合并输入的记录数
20 Reduce input records=4 // reduce从map端接收的记录行数
21 Reduce input groups=3 // reduce函数接收的key数量,即归并后的k2数量
22 Combine output records=0 // 合并输出的记录数
23 Reduce output records=3 // reduce输出的记录行数。<helllo,{1,1}>,<you,{1}>,<me,{1}>
24 Map output records=4 // map输出的记录行数,输出4行记录
二、用户自定义计数器
以上是在Hadoop中系统内置的标准计数器。除此之外,由于不同的场景有不同的计数器应用需求,因此我们也可以自己定义计数器使用。
2.1 敏感词记录-准备
现在假设我们需要对文件中的敏感词做一个统计,即对敏感词在文件中出现的次数做一个记录。这里,我们还是以下面这个文件为例:
Hello World!
Hello Hadoop!
文本内容很简单,这里我们指定Hello是一个敏感词,显而易见这里出现了两次Hello,即两次敏感词需要记录下来。
2.2 敏感词记录-程序
在WordCount程序的基础之上,改写Mapper类中的map方法,统计Hello出现的次数,如下代码所示:
public static class MyMapper extends
Mapper<LongWritable, Text, Text, LongWritable> {
/*
* @param KEYIN →k1 表示每一行的起始位置(偏移量offset)
*
* @param VALUEIN →v1 表示每一行的文本内容
*
* @param KEYOUT →k2 表示每一行中的每个单词
*
* @param VALUEOUT →v2表示每一行中的每个单词的出现次数,固定值为1
*/
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws java.io.IOException, InterruptedException {
Counter sensitiveCounter = context.getCounter("Sensitive Words:", "Hello");
String line = value.toString();
// 这里假定Hello是一个敏感词
if(line.contains("Hello")){
sensitiveCounter.increment(1L);
}
String[] spilted = line.split(" ");
for (String word : spilted) {
context.write(new Text(word), new LongWritable(1L));
}
};
}
我们首先通过Mapper.Context类直接获得计数器对象。这里有两个形参,第一个是计数器组的名称,第二是计数器的名称。
然后通过String类的contains方法判断是否存在Hello敏感词。如果有,进入条件判断语句块,调用计数器对象的increment方法。
2.3 敏感词记录-结果
通过查看控制台日志信息,可以看到如下图所示的信息: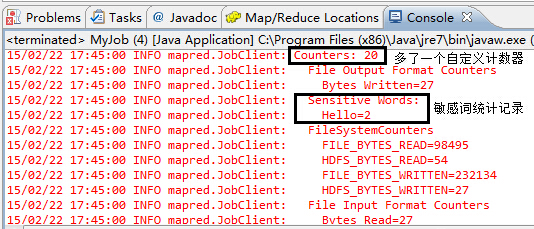
我们可以清楚地看到计数器由原来的19个变为20个,多出来的这个计数器正是我们自定义的敏感词计数器,由于文件中只有两个Hello,因此这里显示Hello=2。
参考资料
(1)Suddenly,《Hadoop日记17-计数器、Map规约与分区》:http://www.cnblogs.com/sunddenly/p/4009568.html
(2)吴超,《Hadoop中的计数器》:http://www.superwu.cn/2013/08/14/460
(3)dajuezhao,《Hadoop中自定义计数器》:http://blog.csdn.net/dajuezhao/article/details/5788705
(4)万川梅、谢正兰,《Hadoop应用开发实战详解(修订版)》:http://item.jd.com/11508248.html
posted on 2015-11-18 16:57 1130136248 阅读(291) 评论(0) 编辑 收藏 举报


