数据库sql优化总结之2-百万级数据库优化方案+案例分析
2019-07-16 22:48 清风软件测试开发 阅读(458) 评论(1) 收藏 举报有三张百万级数据表
知识点表(ex_subject_point)9,316条数据
试题表(ex_question_junior)2,159,519条数据 有45个字段
知识点试题关系表(ex_question_r_knowledge)3,156,155条数据
测试数据库为:mysql (5.7)
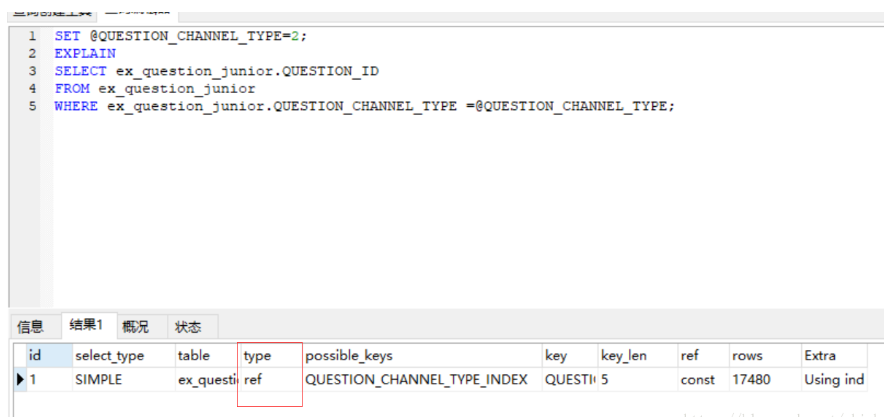
7、在 where 子句中使用参数,是不会导致全表扫描。
案例分析
8、在 where 子句中对字段进行表达式操作,是不会导致全表扫描。不过查询速度会变慢,所以尽量避免使用。
案例分析

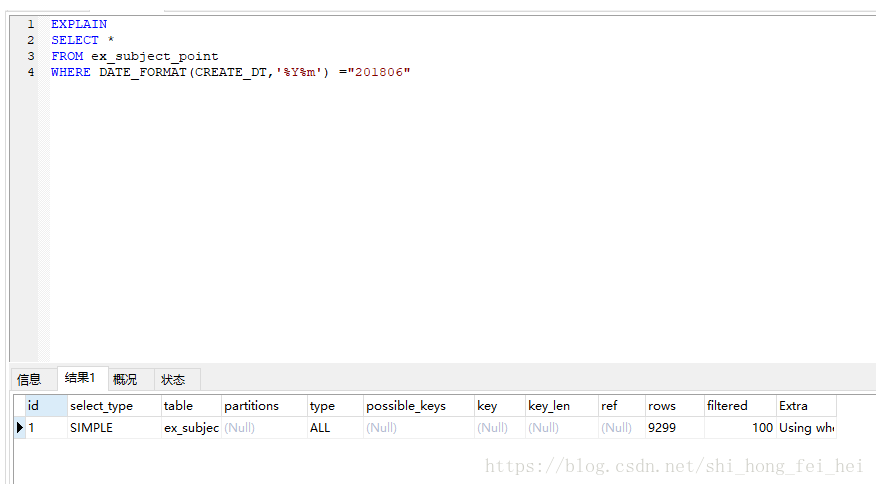
9、应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。
案例分析

难道是因为日期字段索引没有效果吗?还是因为用了>=和<运算符号?
来验证一下
缩小查询范围,发现索引是有效果的。所以不是日期字段的问题。

后来去网上查找了资料,原因是查询数量是超过表的一部分,mysql30%,oracle 20%(这个数据可能不准确,不是官方说明,仅供参考),导致索引失效。
10.不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
例子请看第8点和第9点。
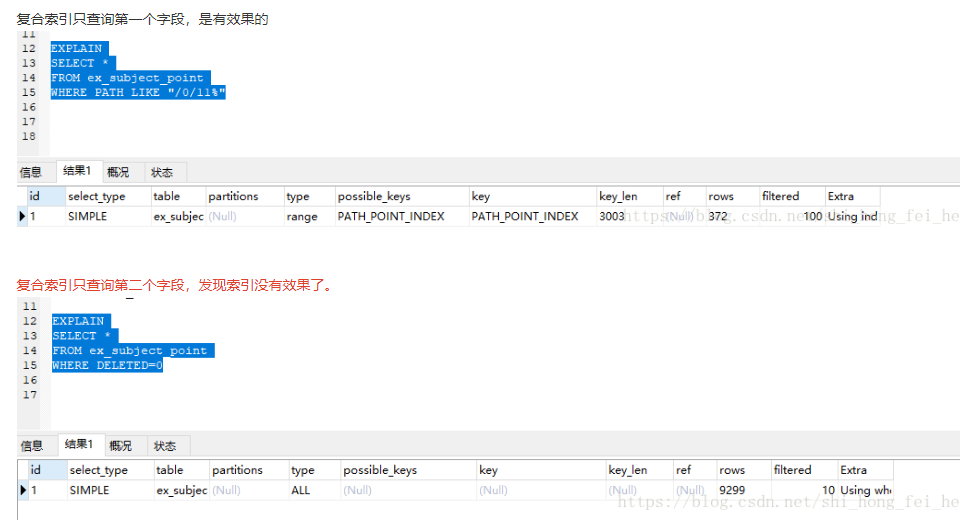
11.在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使用(这个在mysql中不对),并且应尽可能的让字段顺序与索引顺序相一致。
案例分析
复合索引字段:PATH,PARENT_POINT_ID
12.不要写一些没有意义的查询,如需要生成一个空表结构:(一般开发也不会这么无聊啦,在正式的项目上写这种玩意)
select col1,col2 into #t from t where 1=0
这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样:
create table #t(…)
原文地址https://blog.csdn.net/shi_hong_fei_hei/article/details/81046471

 浙公网安备 33010602011771号
浙公网安备 33010602011771号