面向对象程序设计寒假作业1题解
| 这个作业属于哪个课程 | 2020面向对象程序设计 |
|---|---|
| 这个作业要求在哪里 | 面向对象程序设计寒假作业1 |
| 这个作业的目标 | 安装c++开发环境,完成问答题,实践题以及编程题,并发布博客 |
| 作业正文 | 面向对象程序设计寒假作业1题解 |
| 其他参考文献 | C语言二维字符详解 C语言scanf函数输入字符串详解 C语言编译过程 在Windows中用命令行编译运行C/C++程序 PowerShell的使用教程 |
| 问答题: | |
| 一.C语言的缺陷或不足 |
- C语言要定义各种变量,在C99之前想要添加变量甚至要到函数顶部添加。并且变量种类繁多,容易出错,例如int,float,double在进行除法运算时未注意添加小数点结果很容易出错,在编写较大型的程序出错时往往要在找这种地方的错误花上非常多的时间。
- C语言的编译器过多,在语法上有一些方面欠缺统一,导致了“方言”的出现。
- C语言编译不够严格,常常出现在一台机器上可以运行,到另一台机器上崩溃的情况(如指针)。
- 不安全:C的指针操作不做保护,这样的粗暴手段会把安全因素破坏掉从而获得本来不应该获得的东西。比如常见的溢出和越界错误,就是C程序侵犯操作系统的保护领域时被踢出的表现。同时C不能够自动做边界检查,这在一定程度上提高了效率,但同时带来了安全隐患。Strcpy()、strcat()、sprintf()、getchar()、gets()等就是典型的不安全库函数。
- 不严谨:C的数据类型支持不完整,字符型和整型混用,浮点型和整型直接进行计算不会报错,仅仅只是个warning,常常会因此丢失精度。这就导致程序产生漏洞,难以发现错误。这也在一定程度上导致了C的不安全。
其中,第四点和第五点我在思考题2提到过
https://www.cnblogs.com/111900811cocoa/p/12229184.html
二.C语言编译过程
编译过程包括预处理、编译、汇编、链接四个环节。
预处理进行展开头文件、宏替换、去掉注释、条件编译。(test.i main .i)
编译进行检查语法,生成汇编。(test.s main .s)
汇编进行将汇编代码转换成机器代码。(test.o main.o)
链接,链接到一起生成可执行程序。a.out
实践题:
思考过程:刚开始做实践题的时候完全不知道从哪里下手,到处查资料到处问人,得到的回答也都是自己完全看不懂的内容(也有可能是自己的查询方法有问题),后面在群里看到助教提示可以用power shell和cmd查看,于是查了power shell的使用方法
一.查看自己的C++编译器版本

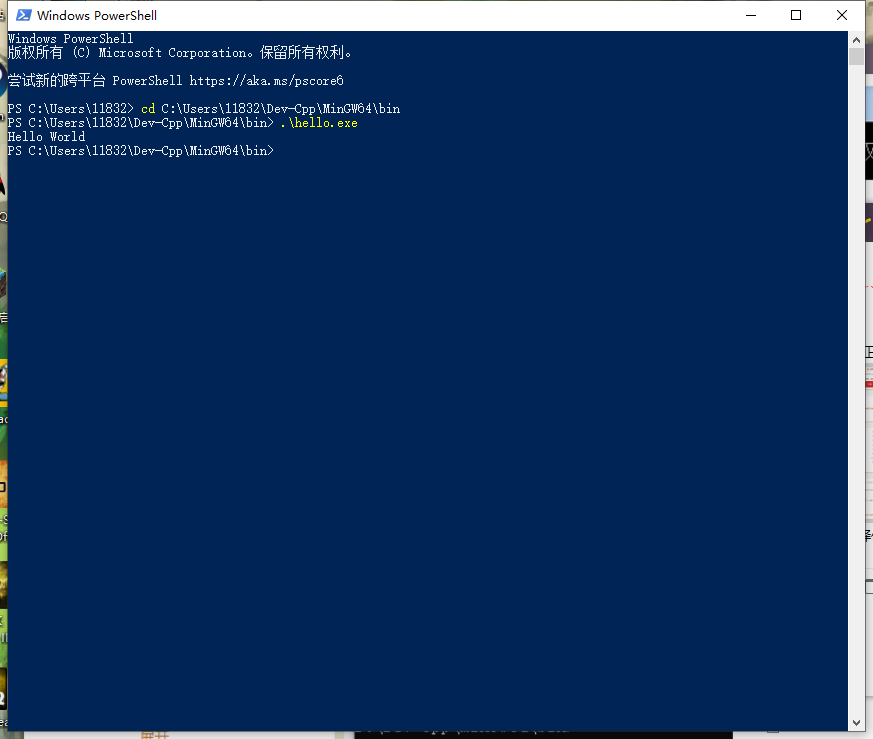
二.使用命令行编译一份C语言/C++代码
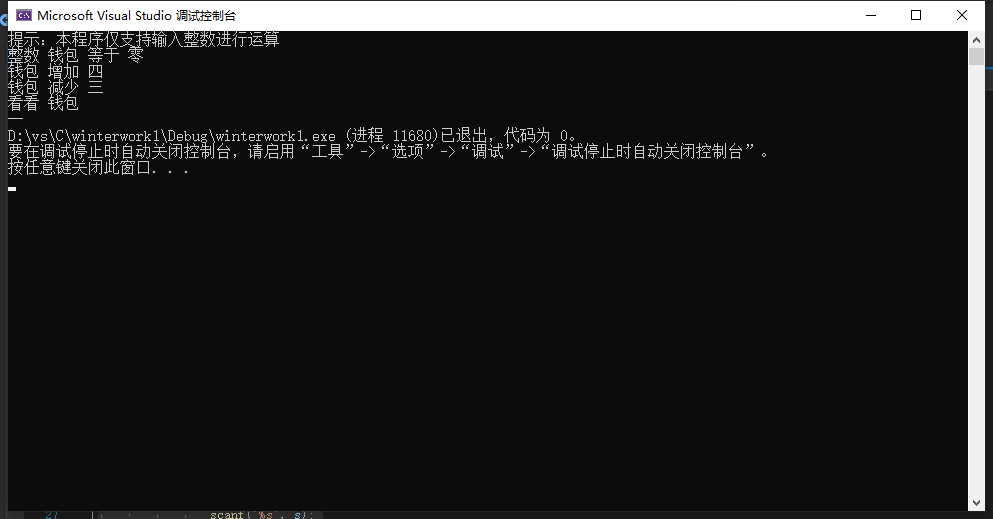
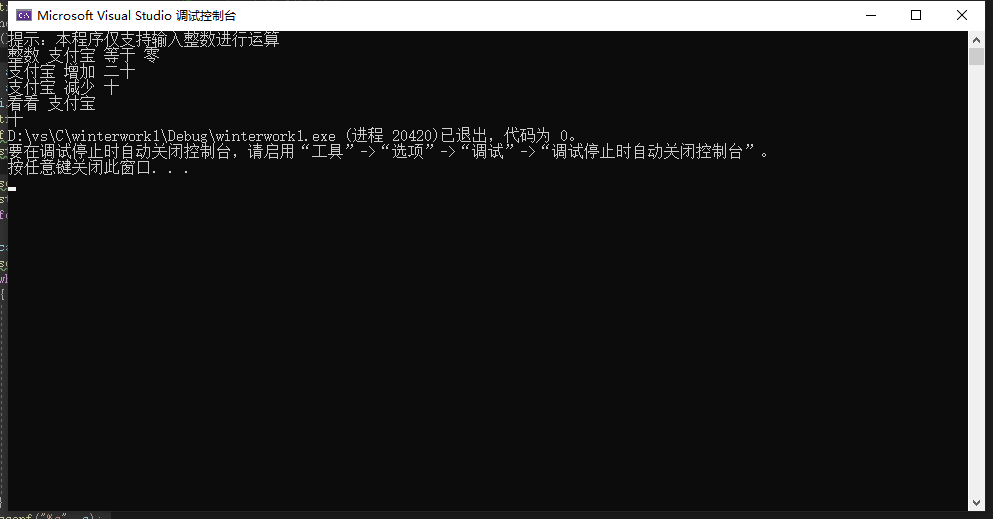
编程题:
思考过程:题目关键就是如何把汉字转换为整型再转换为汉字输出
根据题意“零”至“九十九”的汉字都有可能被输入,根据GBK编码可以知道一个汉字占两个字节,所以可以根据字符串的长度来判断用户输入的汉字类型,因此可以将汉字分为“零”至“十”、“十一”至“十九”和“十的倍数”、“几十几”三种类型来处理
我们可以写一个提取函数(我命名为"extract"),将“十”前后的汉字提取出来,然后将提取出来的汉字交给转换单个汉字的的函数(我命名为"change")处理,这样就可以实现三种类型本质上都由change函数处理
汉字转换函数("num")的代码如下
int num(char* s)
{
int i,j;
int n;
char buffer[5] = "";
if (strlen(s) == 2)//处理0-9的汉字
{
j=change(s);
}
else if (strlen(s) == 4)//处理10-19以及十的倍数的汉字
{
strcpy(buffer,extract(buffer, s));
if (strcmp(buffer, "十") == 0)//处理10-19的汉字
{
j = 10 + change(extract(buffer,s+2));
}
else//处理十的倍数
{
j = change(buffer) * 10;
}
}
else//处理几十几的汉字
{
j = change(extract(buffer, s)) * 10 + change(extract(buffer, s + 4));
}
return j;
}
单个汉字转换函数("change")代码如下
int change(char* s)
{
int i;
for (i = 0; i < 11; i++)
{
if (strcmp(s, chinese[i]) == 0)
return i;
}
}
提取函数("extract")如下
char *extract(char* a, char* b)
{
a[0] = b[0];
a[1] = b[1];
return a;
}
接下来是main函数
在考虑如何输入的时候我着实头疼了一把,字符串内容遗忘的比较多(或者说学习的时候没有好好掌握),同时字符串又作为一个非常重要的内容,所以在写main函数如何输入之前先去查找资料补习回忆了一把,因此有了上方参考资料中“C语言二维数组详解”和“C语言scanf函数输入字符串详解”
通过复(yu)习,我了解到用scanf输入字符串后,一个空格代表着一个字符串的输入结束,所以就用多个scanf函数来多次输入,这样虽然不太简洁,但是可以十分方便的检测输入是否应该结束,同时可以做到不只是“看看钱包”
所有代码如下
#include<stdio.h>
#include<string.h>
int num(char* s);//将汉字转为数字
int change(char* s);//将单个汉字转换为数字
char *extract(char* a, char* b);//提取“十”字前后的数字
char chinese[11][3] = { "零","一","二","三","四","五","六","七","八","九","十" };
int main()
{
char s[10];
char sp[10];
int i,caibu;
printf("提示:本程序仅支持输入整数进行运算\n");
scanf("%s", s);
if (strcmp(s, "整数") == 0)
{
scanf("%s", s);
strcpy(sp, s);
for (i = 0; i < 2; i++)
scanf("%s", s);
caibu = num(s);
scanf("%s", s);
while (strcmp(s, sp) == 0)
{
scanf("%s", s);
if (strcmp(s, "增加") == 0)
{
scanf("%s", s);
caibu += num(s);
}
else if (strcmp(s, "减少") == 0)
{
scanf("%s", s);
caibu -= num(s);
}
scanf("%s", s);
}
scanf("%s", s);
if (caibu <= 10)
printf("%s", chinese[caibu]);
else if (caibu > 10 && caibu < 20)
printf("十%s", chinese[caibu - 10]);
else if (caibu % 10 == 0)
printf("%s十", chinese[caibu / 10]);
else
printf("%s十%s", chinese[caibu / 10], chinese[caibu % 10]);
}
else
printf("错误!请输入整数!");
return 0;
}
int num(char* s)
{
int i,j;
int n;
char buffer[5] = "";
if (strlen(s) == 2)//处理0-9的汉字
{
j=change(s);
}
else if (strlen(s) == 4)//处理10-19以及十的倍数的汉字
{
strcpy(buffer,extract(buffer, s));
if (strcmp(buffer, "十") == 0)//处理10-19的汉字
{
j = 10 + change(extract(buffer,s+2));
}
else//处理十的倍数
{
j = change(buffer) * 10;
}
}
else//处理几十几的汉字
{
j = change(extract(buffer, s)) * 10 + change(extract(buffer, s + 4));
}
return j;
}
int change(char* s)
{
int i;
for (i = 0; i < 11; i++)
{
if (strcmp(s, chinese[i]) == 0)
return i;
}
}
char *extract(char* a, char* b)
{
a[0] = b[0];
a[1] = b[1];
return a;
}
输出图如下