2020软件工程0908个人编程练习
| 这个作业属于哪个课程 | http://dwz.date/cts4 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/SE2020/homework/11167 |
| 这个作业的目标 | 个人编程练习 |
| 学号 | 111800527 |
目录
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 60 |
| Estimate | 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 60 | 70 |
| Analysis | 需求分析 (包括学习新技术) | 300 | 360 |
| Design Spec | 生成设计文档 | 20 | 20 |
| Design Review | 设计复审 | 30 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| Design | 具体设计 | 60 | 60 |
| Coding | 具体编码 | 100 | 120 |
| Code Review | 代码复审 | 60 | 120 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | 60 | 60 |
| Test Report | 测试报告 | 30 | 30 |
| Size Measurement | 计算工作量 | 20 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 890 | 1080 |
解题思路描述
刚看到题的时候不知道 json 是什么,我还以为只有我不知道这是什么文件……
于是在百度和 CSDN 上查了资料才知道 json 文件是一种存储形式
而我们需要做的工作就是从 json 文件中提取有用信息并进行统计
理解之后这次的作业就可以看作提取文件并统计信息了
这样看来这次作业也就没有一开始想象的恐怖了
最开始我首先着手考虑任务一和任务二的实现(因为任务三不知道怎么下手)
任务一和二相对来说还是比较好实现的,最开始我的大致思路如下:
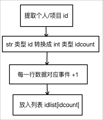
然后和室友讨论了两节课后发现对于任务一和任务二,可以直接提取json文件后将有效信息存入字典,然后把字典存入用户/项目列表
效果如下所示:
idlist[{用户名="",PushEvent="",…}]
当时只想到用这种方法能解决任务一和任务二,对于任务三该怎么这样使用字典并没有想到
所以对这次作业的解题思路也就变成了下面这种:
- 先把样例文件中内容提取出来后,对任务一和任务二针对个人名或项目名统计四种四件数量
- 对任务三,如果个人名、项目名都匹配的情况下,如果符合目标事件,则数量加一并输出
有了思路以后如何实现又陷入了窘境……
看了助教给的示例代码后发现要设置命令行参数才能进行调试、单元测试
于是又开始面向大佬、面向 CSDN 开始学习如何设置命令行参数……
还好在示例代码和同学的指点下搞定了怎么设置命令行
结果怎么进行单元测试又摆在了我面前……您看我还有机会吗
又在面向大佬、面向 CSDN 了许久后学会了单元测试就是对程序里的各个函数进行测试(其实还是写一段测试代码)
最后在快要到截止日期之前总算把单元测试代码完成
并安装了Coverage统计了覆盖率
总的实现过程因为自己不懂的太多花费了太多时间……
设计实现过程
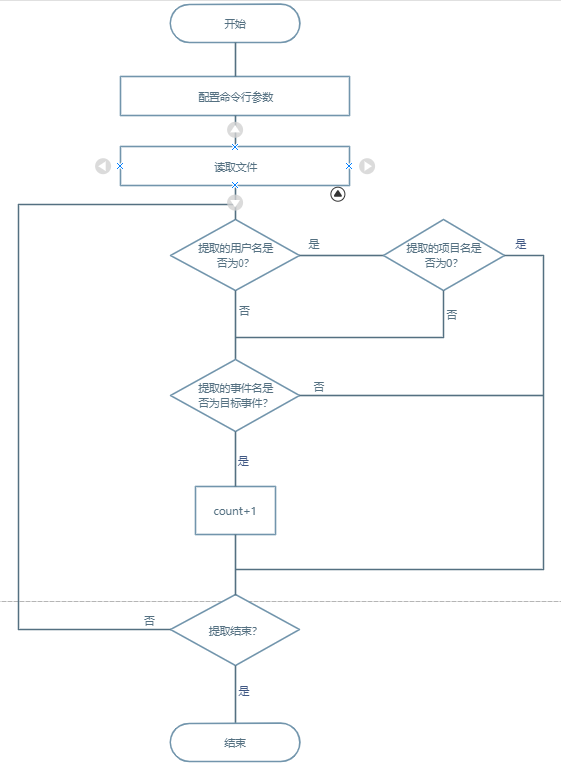
设计函数 readjson 提取文件,calculate_result 获取各种情况下相应数量,都是单线程
代码说明
命令行设置
parser.add_argument('-i', '--init', default='')
parser.add_argument('-u', '--user', default='')
parser.add_argument('-r', '--repo', default='')
parser.add_argument('-e', '--event', default='')
readjson 函数
def readjson(addr):
filelist = os.listdir(addr)
f2 = open('data.json', 'w', encoding='utf-8')
for file in filelist:
pathname = addr + '\\' + file
f = open(pathname, 'r', encoding='utf-8')
for line in f:
data = json.loads(line)
f2.write(line)
f2.close()
f.close()
return
calculate_result 函数
def calculate_result(datalist, username, reponame, eventname):
count = 0
for da in datalist:
if len(username) != 0 and len(reponame) == 0:
if username == da['actor']['login'] and da['type'] == eventname:
count += 1
else:
pass
elif len(username) == 0 and len(reponame) != 0:
if reponame == da['repo']['name'] and da['type'] == eventname:
count += 1
else:
pass
elif len(username) != 0 and len(reponame) != 0:
if username == da['actor']['login'] and reponame == da['repo']['name'] and eventname == da['type']:
count += 1
else:
pass
print(count)
return
GitHub 运行结果
单元测试截图和描述
单元测试代码
def test_readjson():
data = open("data.json", 'r', encoding='utf-8')
i = 0
for da in data:
if i == 0:
assert json.loads(da)['actor']['login'] == 'cdupuis'
i += 1
def test_calculate_result():
l = []
data = open("data.json",'r',encoding='utf-8')
for da in data:
l.append(json.loads(da))
assert calculate_result(l,'cdupuis','PushEvent','atomist/automation-client') == None
测试截图

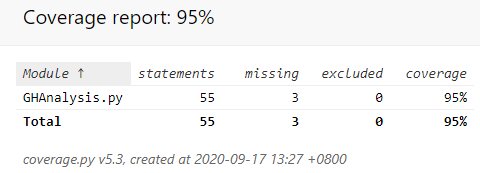
单元测试覆盖率优化和性能测试
首先安装 coverage,之后逐步测试并生成覆盖率 html 文件
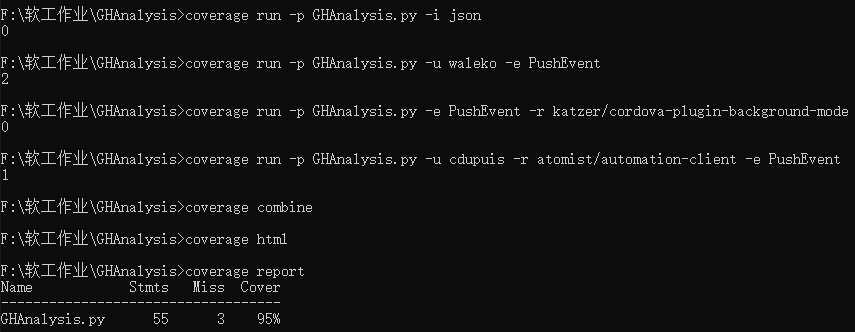
html 覆盖率文件

代码规范链接
遇到的困难
- python 学完之后不经常使用,所以写代码的时候基本是边查边用,效率比较低
- 对于任务三的实现卡了好久没有思路,普通的实现觉得开销太大,但是优化方法也想不出来……
- 运行格式的命令行参数不知道是什么,在室友的帮助下才马马虎虎写了出来
总结
- 这次作业本身来说不是很难,但是由于自己实力太弱,学习新知识和新工具耗费时间太多,到最后呈现代码效果也并不理想 orz
- 在开始任务之前一定要缕清思路之后再下手,不然会浪费自己很多时间
- 没有想法的时候多和室友、同学沟通,不要自己一直钻牛角尖,本来一个小时就能完成的任务自己死磕能耗费一晚上……
- 代码完成度、优化方面还是没有做好,只是简单的完成了任务,空间、时间开销应该会很大……日后再慢慢学习优化吧
- 虽然对自己来说实现难度比较大,但是这次作业也让我学到了很多东西,比如怎么解析 json 文件,怎么设置命令行参数,怎么使用 git 进行代码测试等等
- 虽然做作业很多次崩溃,但是提交完作业还是很爽的 😄
(痛并快乐着)
