机器学习--BP算法
机器学习
一、选题背景
原因:本项目使用BP算法,对 iris 数据集(手写数字集)进行二分类,BP算法可以看做成一个浅层的神经网络,希望以后对学习深度学习有一个初步的探索。
数据来源: sklearn中自带数据集
二、设计方案:
1.来源描述:使用sklearn中的自带数据集,手写数字数据集。
- 框架描述:
BP算法主要是由前向传播和反向传播两个主要过程组成,正向传播时,输入样本从输入层进入网络,经隐层逐层传递至输出层,如果输出层的实际输出与期望输出不同,则转至误差反向传播;如果输出层的实际输出与期望输出相同,结束学习算法。
反向传播时,将输出误差(期望输出与实际输出之差)按原通路反传计算,通过隐层反向,直至输入层,在反传过程中将误差分摊给各层的各个单元,获得各层各单元的误差信号,并将其作为修正各单元权值的根据。这一计算过程使用梯度下降法完成,在不停地调整各层神经元的权值和阈值后,使误差信号减小到最低限度。权值和阈值不断调整的过程,就是网络的学习与训练过程,经过信号正向传播与误差反向播,权值和阈值的调整反复进行,一直进行到预先设定的学习训练次数,或输出误差减小到允许的程度。
- 涉及到的技术难点解决方案:
技术难点:反向传播,以及训练模块的编写。
解决方案:参照吴恩达是视频以及其课后作业,经琢磨后,反向传播的基本原理其实不难,基本理论就是大学高等数学当中的导数计算。我们需要了解的就是链式法则。
三、实现步骤:
特征分析:
手写数字集是 sklearn中自带的数据集,它是一个三维数组(1797, 8, 8), 即
有 1797 个手写数字,每个数字由 8*8 的像素矩阵组成。矩阵中每个元素都是 0-16 范围内的整数。分类标签为 0-9的数字
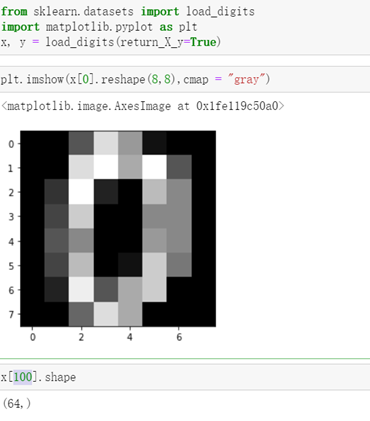
对于切分数据集,本次就选择了sklearn中的模块train_test_split来划分测试集与训练集。
模型选择:
选择BP模型,使用sigmoid函数作为激活函数,低价函数使用均方差误差,通过控制不同的学习率,来观测该模型的结果的差异。
之后就可以进行训练了:
图一为最高训练轮数为10轮(学习率为0.05),未达到预设精度。(之后将最大训练轮数设为100)
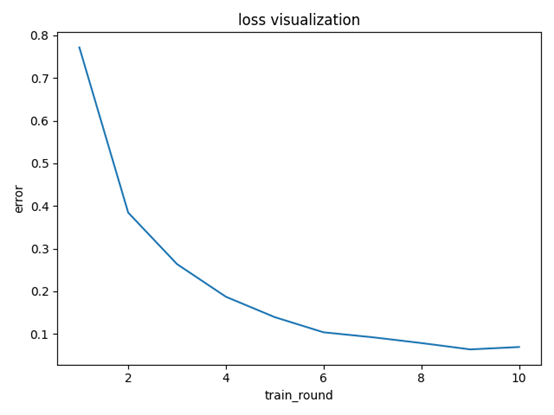
图一
图二学习率为0.05,训练轮数为经过30轮后达到预设精度。
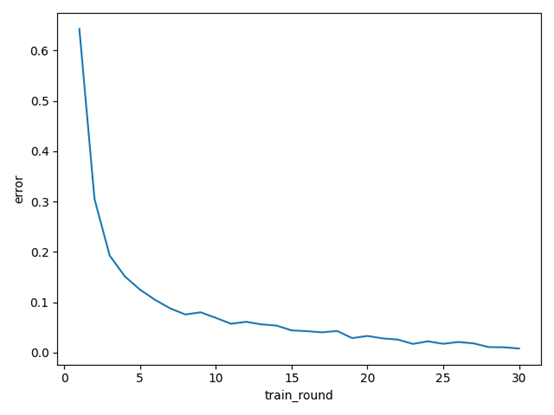
图二
图三学习率为0.09,而训练轮数已经达到了100轮,而其精度却一直为达到预设精度
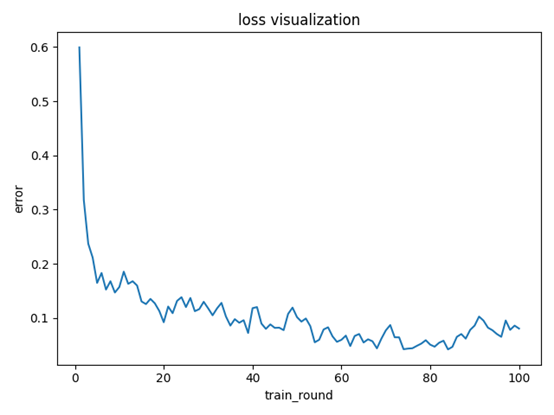
图三
图三学习率为0.02,而训练轮数达到了51轮才达到预设精度。
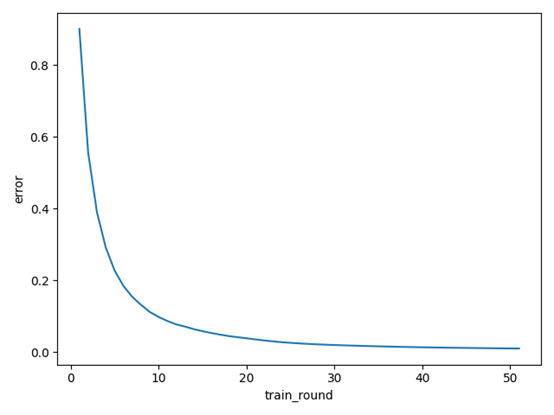
图四
四、总结
1.结论:由上述对比可以发现,学习率不宜过大,否则的话最后的error会产生波动无法稳定,最终导致无法收敛,一直在最优解间摆动。而学习率过小的话尽管最终会达到预设精度,找到最优解,但明显其训练轮数增多。所以,学习率是训练过程中的重要参数。
2.收获:对python语法更加熟悉,对类的使用更为熟练,对BP算法有了更深入的了解,对深度学习有了一个初步的认知。
改进建议:可以尝试使用tanh函数作为激活函数,探究不同的激活函数对模型训练的效率以及准确率的影响;初始化参数时候,可以采用随机初始化。
源码:
def sigmoid(x):
return 1 / (1 + np.exp(-1 * x))
class layerbuild:
def __init__(
self, units, activation=None, learning_rate=None, is_input_layer=False
):
self.units = units
self.weight = None
self.bias = None
self.activation = activation
if learning_rate is None:
learning_rate = 1
self.learn_rate = learning_rate
self.is_input_layer = is_input_layer
def initializer(self, back_units):
self.weight = np.asmatrix(np.random.normal(0, 0.5, (self.units, back_units)))
self.bias = np.asmatrix(np.random.normal(0, 0.5, self.units)).T
if self.activation is None:
self.activation = sigmoid
def cal_gradient(self):
if self.activation == sigmoid:
gradient_mat = np.dot(self.output, (1 - self.output).T)
gradient_activation = np.diag(np.diag(gradient_mat))
else:
gradient_activation = 1
return gradient_activation
def forward_propagation(self, xdata):
self.xdata = xdata
if self.is_input_layer:
self.wx_plus_b = xdata
self.output = xdata
return xdata
else:
self.wx_plus_b = np.dot(self.weight, self.xdata) - self.bias
self.output = self.activation(self.wx_plus_b)
return self.output
def backpropagation(self, gradient):
gradient_activation = self.cal_gradient() # i * i 维
gradient = np.asmatrix(np.dot(gradient.T, gradient_activation))
self._gradient_weight = np.asmatrix(self.xdata)
self._gradient_bias = -1
self._gradient_x = self.weight
self.gradient_weight = np.dot(gradient.T, self._gradient_weight.T)
self.gradient_bias = gradient * self._gradient_bias
self.gradient = np.dot(gradient, self._gradient_x).T
self.weight = self.weight - self.learn_rate * self.gradient_weight
self.bias = self.bias - self.learn_rate * self.gradient_bias.T
return self.gradient,self.weight,self.bias
class BPNN():
def __init__(self,x_test,y_test):
self.layers = []
self.train_mse = []
self.y_test = y_test
self.x_test = x_test
self.bias = None
self.weight = None
def add_layer(self, layer):
self.layers.append(layer)
def build(self):
for i, layer in enumerate(self.layers[:]):
if i < 1:
layer.is_input_layer = True
else:
layer.initializer(self.layers[i - 1].units)
def train(self, xdata, ydata, max_train_round, accuracy):
self.max_train_round = max_train_round
self.accuracy = accuracy
x_shape = np.shape(xdata)
k = 0
for round_i in range(max_train_round):
all_loss = 0
k += 1
for row in range(x_shape[0]):
_xdata = np.asmatrix(xdata[row, :]).T
_ydata = np.asmatrix(ydata[row, :]).T
for layer in self.layers:
_xdata = layer.forward_propagation(_xdata)
loss, gradient = self.cal_loss(_ydata, _xdata)
all_loss = all_loss + loss
for layer in self.layers[:0:-1]:
gradient,weight,bias = layer.backpropagation(gradient)
mse = all_loss / x_shape[0]
self.train_mse.append(mse)
# print(self.train_mse)
if mse < self.accuracy:
print("测试集准确率",self.predict(xdata, ydata, max_train_round))
print("达到预设精度,所用训练轮数为:{}轮".format(k))
# print(self.train_mse)
xx = np.arange(1, k + 1)
yy = self.train_mse
plt.plot(xx, yy)
plt.xlabel("train_round")
plt.ylabel("error")
plt.show()
return print("分类准确率为", 1 - mse)
if k == self.max_train_round:
print("测试集准确率",self.predict(xdata, ydata, max_train_round))
print("未达到预设精度,所用训练轮数为:{}轮".format(k))
xx = np.arange(1, k + 1)
yy = self.train_mse
plt.plot(xx, yy)
plt.xlabel("train_round")
plt.ylabel("error")
plt.title("loss visualization")
plt.show()
return print("分类准确率为", 1 - mse)
def cal_loss(self, ydata, ydata_):
self.loss = np.sum(np.power((ydata - ydata_), 2))
self.loss_gradient = 2 * (ydata_ - ydata)
return self.loss, self.loss_gradient
def predict(self, xdata, ydata, max_train_round):
self.max_train_round = max_train_round
x_shape = np.shape(xdata)
k = 0
for round_i in range(max_train_round):
all_loss = 0
k += 1
for row in range(x_shape[0]):
_xdata = np.asmatrix(xdata[row, :]).T
_ydata = np.asmatrix(ydata[row, :]).T
for layer in self.layers:
_xdata = layer.forward_propagation(_xdata)
loss, gradient = self.cal_loss(_ydata, _xdata)
all_loss = all_loss + loss
for layer in self.layers[:0:-1]:
gradient, weight, bias = layer.backpropagation(gradient)
mse = all_loss / x_shape[0]
# print(self.train_mse)
return (1-mse)
from sklearn.datasets import load_digits
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
x, y = load_digits(return_X_y=True)
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state=666)
y_train = y_train.reshape(-1, 1)
y_train = pd.DataFrame(y_train)
y_train.columns = ['type']
y_train = pd.get_dummies(y_train.type, prefix='type')
y_train = np.array(y_train)
y_test = y_test.reshape(450,-1)
print("y",y_test.shape)
model = BPNN(x_test,y_test)
for i in (64, 70, 70, 10):
model.add_layer(layerbuild(i, learning_rate=0.05))
model.build()
model.train(xdata=x_train, ydata=y_train, max_train_round=10, accuracy=0.01)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号