XPath定位方法,chrome浏览器中查看html元素的方法
经常用火车头采集器的站长朋友,可能会遇到需要需要使用Xpath方式获取地址的方法来采集网址。今天品自行说一下如何用Chrome浏览器查看html元素,进行XPath定位,找到XPath路径。
1、下载并安装Chrome浏览器(就是Google浏览器),打开目标网页;
2、使用快捷键ctrl+shift+i或者f12,或者直接网页上面右键单击,选择“检查”即可弹出DevTools开发者工具。
Chrome DevTools是内置在Google Chrome浏览器中的一个网页调试工具,也叫作开发者工具,不管是小白还是大神用这款软件能够极大提高网页调试效率。
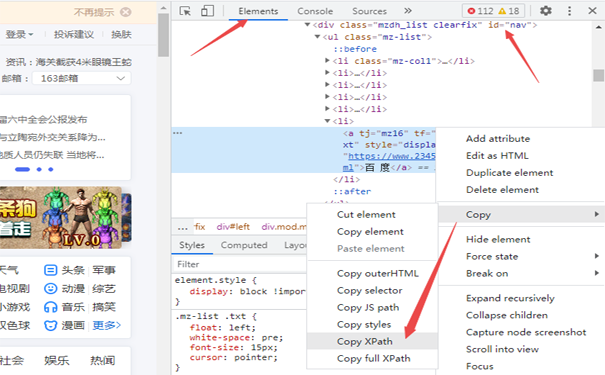
默认选择element面板,Elements 面板中可以通过 DOM 树的形式查看所有页面元素,同时也能对这些页面元素进行所见即所得的编辑。
找到需要定位的元素所在的位置,鼠标放在右侧元素所在位置的代码所在处,代码会高亮显示,右键“Copy”》“Copy XPath”(也可以选择Copy Xpath,前者是相对路径,后者是绝对路径),下面是复制下来的XPath路径。
//*[@id="nav"]/ul[1]/li[6]/a 这里简单说明一下,这句XPath代码的意思是,定位到id="nav"的div标签下面第一个ul标签下的第六个li标签下的a标签,具体看截图所示代码理解这句话。
具体定位到的就是a标签中间的文字“百度”(看上图)。
另外:貌似目前好多浏览器都有这个功能,比如搜狗浏览器就是在高速模式下打开网页》右键,选择“审查元素”,也可以打开搜狗浏览器的类似开发者工具,然后定位好元素,右键“Copy”》“Copy XPath”也可以搞定这个问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号