
关于C++中的大小端、位段(惑位域)和内存对齐(转)
听到好几个朋友说到去一些公司做面试,总是遇到关于大小端、位段(或者叫位域)和内存对齐的考题,然后就不知所措了。虽然我认为很多开发根本就用不到这个,但是我认为很有必要学习理解这些知识点,因为它可以让你更了解C++的,了解程序在内存的运行情况,也能加深对计算机系统的理解。
声明:由于本文的代码会受到计算机环境的影响,故在此说明本篇博文中的程序的运行环境。
1、Microsoft Windows 7 Ultimate Edition Service Pack 1 (64bit 6.1.7601)
2、Microsoft Visual Studio 2010 Version 10.0.40219.1 SP1Rel(Ultimate--ENU)。
3、Microsoft .NET Framework Version 4.0.30319 SP1Rel
4、Microsoft Visual C++ 2010
注:虽然系统是64位的,但是我是使用VC++ 2010默认配置,也即是x86平台。所以下面所有示例和文字表述都是基于32位编译平台。
一、大小端
在现代“冯.诺依曼体系结构”计算机中,它的数制都是采用二进制来存储,并且是以8位,一个字节为单位,产生内存地址系统。数据在内存中有如下三种存在方式:
1、从静态存储区分配:此时的内存在程序编译的时候已经分配好,并且在程序的整个运行期间都存在。全局变量,static变量等在此存储。
2、在栈区分配:在程序的相关代码执行时创建,执行结束时被自动释放。局部变量在此存储。栈内存分配运算内置于处理器的指令集中,效率
高,但容量有限。
3、在堆区分配:动态分配内存。用new/malloc时开辟,delete/free时释放。变量的生存期由用户指定,灵活,但会有内存泄露等问题。
对于像C++中的char这样的数据类型,它本身就是占用一个字节的大小,不会产生什么问题。但是当数制类型为int,在32bit的系统中,它需要占用4个字节(32bit),这个时候就会产生这4个字节在寄存器中的存放顺序的问题。比如int maxHeight = 0x12345678,&maxHeight = 0x0042ffc4。具体的该怎么存放呢?这个时候就需要理解计算机的大小端的原理了。
大端:(Big-Endian)就是把数值的高位字节放在内存的地位地址上,把数值的地位字节放在内存的地位地址上。
小端:(Little-Endian)就是把数字的高位字节放在高位的地址上,地位字节放在地位地址上。
我们常用的x86结构都是小端模式,而大部分DSP,ARM也是小端模式,不过有些ARM是可以选择大小端模式。所以对于上面的maxHeight是应该以小端模式来存放,具体情况请看下面两表。
| 地址 | 0x0042ffc4 | 0x0042ffc5 | 0x0042ffc6 | 0x0042ffc7 |
|
数值 |
0x78 |
0x56 |
0x34 |
0x12 |
上图为小端模式
| 地址 | 0x0042ffc4 | 0x0042ffc5 | 0x0042ffc6 | 0x0042ffc7 |
| 数值 |
0x12 |
0x34 |
0x56 |
0x78 |
上图为大端模式
通过上面的表格,可以看出来大小端的不同,在这里无法讨论那种方式更好,个人觉得似乎大端模式更符合我的习惯。(注:在这里我还要说一句,其实在计算机内存中并不存在所谓的数据类型,比如char,int等的。这个类型在代码中的作用就是让编译器知道每次应该从那个地址起始读取多少位的数据,赋值给相应的变量。)
二、位段或位域
在前面已经提起过,在计算机中是采用二进制0和1来表示数据的,每一个0或者1占用1位(bit)存储空间,8位组成一个字节(byte),为计算机中数据类型的最小单位,如char在32bit系统中占用一个字节。但是正如我们知道的,有时候程序中的数据可能并不需要这么的字节,比如一个开关的状态,只有开和关,用1和0分别替代就可以表示。此时开关的状态只需要一位存储空间就可以满足要求。如果用一个字节来存储,显然浪费了另外的7位存储空间。所以在C语言中就有了位段(有的也叫位域,其实是一个东西)这个概念。具体的语法就是在变量名字后面,加上冒号(:)和指定的存储空间的位数。具体的定义语法如下:
1: struct 位段名称 2: { 3: 位段数据类型 位段变量名称 : 位段长度, 4: ....... 5: } 6: 7: 实例 8: 9: struct Node 10: { 11: char a:2; 12: double i; 13: int c:4; 14: }node;
其实定义很简单,上面示例的意义是,定义一个char变量a,占用2位存储空间,一个double变量i,以及一个占用4位存储的int变量c。请注意这里改变了变量本来占用字节的大小,并不是我们常规定义的一个int变量占用4个字节,一个char变量占用1一个字节。但是sizeof(node) = ?呢,在实际的运行环境中运行,得到sizeof(node) = 24;为什么呢?说起来其实也很简单,字节对齐,什么是字节对齐,待会下一个段落会具体讲解。先来看一个面试示例,代码如下:
1: #include <iostream> 2: 3: using namespace std; 4: 5: union 6: { 7: struct 8: { 9: char i:1; 10: char j:2; 11:char m:3; 12: }s; 13: 14: char ch; 15: }r; 16: 17: int _tmain(int argc, _TCHAR* argv[]) 18: { 19: r.s.i = 1; 20:r.s.j = 2; 21: r.s.m = 3; 22: 23: cout<<" r.ch = "<<(int)r.ch<<" = 0x"<<hex<<(int)r.ch<<endl 24: <<" sizeof(r) = "<<sizeof(r)<<endl; 25: 26: return 0; 27: }
好了,具体结果是怎么样的呢?
r.ch = 29 = 0x1d
sizeof(r) = 1
为什么是这个结果?说起来其实也很简单,结合前面的大小端,可以具体来分析下,先看下表:
|
|
m:3 |
j:2 |
i:1
|
||||
|
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
|
0 |
0 |
0 |
1 |
1 |
1 |
0 |
1 |
|
1 |
D |
||||||
上面的表格,解释了为什么这里等于29=0x1D。首先i、j、m分别占用1、2、3位,分布在一个字节中。故根据赋值语句可知,在内存的相应的字节上首先存储i=1,然后存储j=2,也即10,而后是m=3,也即011。可看上表的不同颜色所示,然后不足的位,补0来填充。所以整个字节就是0x1D=29,顾r.ch = 29 = 0x1D。
关于位段,补充以下规则:
三、内存对齐
内存地址对齐,是一种在计算机内存中排列数据(表现为变量的地址)、访问数据(表现为CPU读取数据)的一种方式,包含了两种相互独立又相互关联的部分:基本数据对齐和结构体数据对齐 。
为什么需要内存对齐?对齐有什么好处?是我们程序员来手动做内存对齐呢?还是编译器在进行自动优化的时候完成这项工作?
在现代计算机体系中,每次读写内存中数据,都是按字(word,4个字节,对于X86架构,系统是32位,数据总线和地址总线的宽度都是32位,所以最大的寻址空间为232 = 4GB(也许有人会问,我的32位XP用不了4GB内存,关于这个不在本篇博文讨论范围),按A[31,30…2,1,0]这样排列,但是请注意为了CPU每次读写4个字节寻址,A[0]和A[1]两位是不参与寻址计算的。)为一个快(chunks)来操作(而对于X64则是8个字节为一个快)。注意,这里说的CPU每次读取的规则,并不是变量在内存中地址对齐规则。既然是这样的,如果变量在内存中存储的时候也按照这样的对齐规则,就可以加快CPU读写内存的速度,当然也就提高了整个程序的性能,并且性能提升是客观,虽然当今的CPU的处理数据速度(是指逻辑运算等,不包括取址)远比内存访问的速度快,程序的执行速度的瓶颈往往不是CPU的处理速度不够,而是内存访问的延迟,虽然当今CPU中加入了高速缓存用来掩盖内存访问的延迟,但是如果高密集的内存访问,一种延迟是无可避免的,内存地址对齐会给程序带来了很大的性能提升。
内存地址对齐是计算机语言自动进行的,也即是编译器所做的工作。但这不意味着我们程序员不需要做任何事情,因为如果我们能够遵循某些规则,可以让编译器做得更好,比较编译器不是万能的。
为了更好理解上面的意思,这里给出一个示例。在32位系统中,假如一个int变量在内存中的地址是0x00ff42c3,因为int是占用4个字节,所以它的尾地址应该是0x00ff42c6,这个时候CPU为了读取这个int变量的值,就需要先后读取两个word大小的块,分别是0x00ff42c0~0x00ff42c3和0x00ff42c4~0x00ff42c7,然后通过移位等一系列的操作来得到,在这个计算的过程中还有可能引起一些总线数据错误的。但是如果编译器对变量地址进行了对齐,比如放在0x00ff42c0,CPU就只需要一次就可以读取到,这样的话就加快读取效率。
在这里给出三个个人认为讲解比较好的网址,供大家参考,英语比较好的朋友,推荐阅读。
a、Data structure alignment(http://en.wikipedia.org/wiki/Data_structure_alignment)
b、Data alignment: Straighten up and fly right(http://www.ibm.com/developerworks/library/pa-dalign/)
c、About Data Alignment(http://msdn.microsoft.com/zh-cn/library/ms253949.aspx)
1、基本数据对齐
在X86,32位系统下基于Microsoft、Borland和GNU的编译器,有如下数据对齐规则:
a、一个char(占用1-byte)变量以1-byte对齐。
b、一个short(占用2-byte)变量以2-byte对齐。
c、一个int(占用4-byte)变量以4-byte对齐。
d、一个long(占用4-byte)变量以4-byte对齐。
e、一个float(占用4-byte)变量以4-byte对齐。
f、一个double(占用8-byte)变量以8-byte对齐(注:在Linux平台下是4-byte对齐,超过4-byte都是以4-byte对齐)。
g、一个long double(占用12-byte)变量以4-byte对齐。
h、任何pointer(占用4-byte)变量以4-byte对齐。
而在64位系统下,与上面规则对比有如下不同:
a、一个long(占用8-byte)变量以8-byte对齐。
b、一个double(占用8-byte)变量以8-byte对齐。
c、一个long double(占用16-byte)变量以16-byte对齐。
d、任何pointer(占用8-byte)变量以8-byte对齐。
2、结构体数据对齐
结构体数据对齐,是指结构体内的各个数据对齐。在结构体中的第一个成员的首地址等于整个结构体的变量的首地址,而后的成员的地址随着它声明的顺序和实际占用的字节数递增。为了总的结构体大小对齐,会在结构体中插入一些没有实际意思的字符来填充(padding)结构体。
1: #include <iostream> 2: 3: using namespace std; 4: 5: union 6: { 7: struct 8: { 9: char i:1; 10: char j:2; 11:char m:3; 12: }s; 13: 14: char ch; 15: }r; 16: 17: struct 18: { 19: char i; 20: double j; 21: int m; 22: }node; 23: 24: int _tmain(int argc, _TCHAR* argv[]) 25: { 26: r.s.i = 1; 27: r.s.j = 2; 28: r.s.m = 3; 29: 30: node.i = 'm'; 31: node.j = 3.1415926; 32: node.m = 100; 33: 34: cout<<" r.ch = "<<(int)r.ch<<" = 0x"<<hex<<(int)r.ch<<endl 35: <<" sizeof(r) = "<<sizeof(r)<<endl; 36: 37: cout.unsetf(ios::hex); 38: 39: cout<<" sizeof(node) = "<<sizeof(node)<<endl; 40: 41: system("PAUSE"); 42: 43: return 0; 44: } 45:
运行结果截图如下:
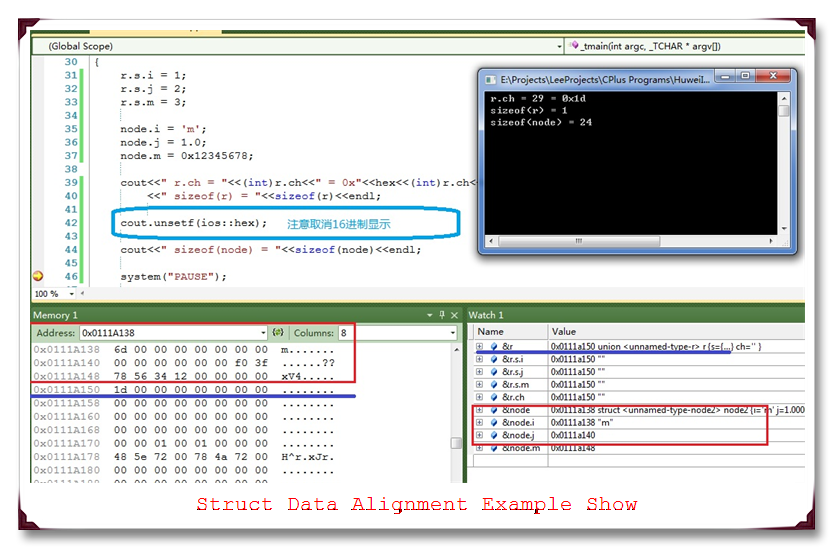
通过上面的运行截图,可以得知,sizeof(r) = 1,sizeof(node)=24;首先看r存储在首地址0x0111a150,node的首地址 为0x0111a138,这个符合先定义先分配空间,并且是从内存地址大到小的顺序来分配空间。它们之间相差(0x0111a150-0x0111a138)=0x18=24byte(注意这里是16进制计算,借1当16,不是习惯性的当10)。而且通过每个成员的地址也知道,m和j之间隔8字节,double是占用8字节,j和i之间也是8字节,但是char只占用了一个字节,其余相差的7个字节使用0来填充。同样int成员在后面的4个高字节中也填充了0,以满足8字节对齐(前面4个字节按小端高字节高地址低字节低地址存放)。同样r只占用0x0111a150这个字节,值为0x1d=29。
在结构体中,成员数据对齐满足以下规则:
a、结构体中的第一个成员的首地址也即是结构体变量的首地址。
b、结构体中的每一个成员的首地址相对于结构体的首地址的偏移量(offset)是该成员数据类型大小的整数倍。
c、结构体的总大小是对齐模数(对齐模数等于#pragma pack(n)所指定的n与结构体中最大数据类型的成员大小的最小值)的整数倍。
在看另外一个示例,来理解以上规则。
1: #include "stdafx.h" 2: 3: #include <iostream> 4: 5: using namespace std; 6: 7: struct 8: { 9: char a; 10: int b; 11: short c; 12: char d; 13: }dataAlign; 14: 15: struct 16: { 17: char a; 18: char d; 19: short c; 20: int b;21: 22: }dataAlign2; 23: 24: int _tmain(int argc, _TCHAR* argv[]) 25: { 26: dataAlign.a = 'A'; 27: dataAlign.b = 0x12345678; 28: dataAlign.c = 0xABCD; 29: dataAlign.d = 'B'; 30: 31: dataAlign2.a = 'A'; 32: dataAlign2.b = 0x12345678; 33: dataAlign2.c = 0xABCD; 34: dataAlign2.d = 'B'; 35: 36: cout<<" sizeof(dataAlign) = "<<sizeof(dataAlign)<<endl; 37: cout<<" sizeof(dataAlign2) = "<<sizeof(dataAlign2)<<endl; 38: 39: system("PAUSE"); 40: 41: return 0; 42: }
运行结果截图如下:
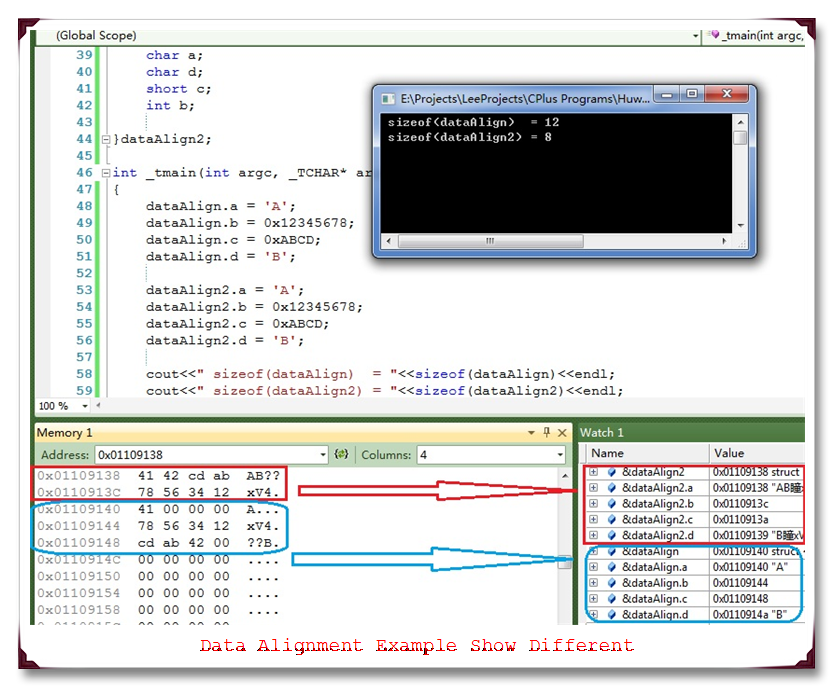
仔细观察,会发现虽然是一样的数据类型的成员,只不过声明的顺序不同,结构体占用的大小也不同,一个8-byte一个12-byte。为什么这样,下面进行具体分析。
首先来看dataAlign2,第一个成员的地址等于结构体变量的首地址,第二个成员char类型,为了满足规则b,它相对于结构体的首地址的偏移量必须是char=1的倍数,由于前面也是char,故不需要在第一个和第一个成员之间填充,直接满足条件。第三个成员short=2如果要满足规则b,也不需要填充,因为它的偏移量已经是2。同样第四个也因为偏移量int=4,不需要填充,这样结构体总共大小为8-byte。最后来验证规则c,在VC中默认的#pragma pack(n)中的n=8,而结构体中数据类型大小最大的为第四个成员int=4,故对齐模数为4,并且8 mode 4 = 0,所以满足规则c。这样整个结构体的总大小为8。结合上面运行结果截图的红色框,可以验证。
对于dataAlign,第一个成员等于结构体变量首地址,偏移量为0,第二个成员为int=4,为了满足规则b,需要在第一个成员之后填充3-byte,让它相对于结构体首地址偏移量为4,结合运行结果截图,可知&dataAlign.a = 0x01109140,而&dataAlign.b = 0x01109144,它们之间相隔4-byte,0x01109141~0x01109143三个字节被0填充。第三个成员short=2,无需填充满足规则b。第四个成员char=1,也不需要填充。OK,结构体总大小相加4 + 4 + 2 + 1 = 11。同样最后需要验证规则c,结构体中数据类型大小最大为第二个成员int=4,比VC默认对齐模数8小,故这个结构体的对齐模数仍然为4,显然11 mode 4 != 0,故为了满足规则c,需要在char后面填充一个字节,这样结构体变量dataAlign的总大小为4 + 4 + 2 + 2 = 12。
好了,再来看看位段(也叫位域)这种数据类型在内存中的对齐。一个位域必须存储在同一个字节中,不能跨字节,比如跨两个字节。如果一个字节所剩空间不够存储另一位位域时,应该从下一个字节存放该位域。在满足成员数据对齐的规则下,还满足如下规则:
d、如果相邻位域类型相同,并且它俩位域宽度之和小于它的数据类型大小,则后面的字段紧邻前面的字段存储。
e、如果相邻位域类型相同,但是它俩位域宽度之和大于它的数据类型大小,则后面的字段将从新的存储单元开始,其偏移量为其类型的整数倍。
f、如果相邻位域类型不同,在VC中是不采取压缩方式,但是GCC会采取压缩方式。
具体的结合下面示例来理解,具体代码为:
1: #include <iostream> 2: 3: using namespace std; 4: 5: struct 6: { 7: char a:4; 8: int b:6; 9: }bitChar2; 10: 11: struct 12: { 13: char a:3; 14: char b:3; 15: char c:7; 16: double d; 17: int e:4; 18: int f:30; 19: }bitChar; 20: 21: int _tmain(int argc, _TCHAR* argv[]) 22: { 23: bitChar2.a = 7; 24: bitChar2.b = 32; 25: cout<<" sizeof(bitChar2) = "<<sizeof(bitChar2)<<endl; 26: 27: bitChar.a = 6; 28: bitChar.b = 4; 29: bitChar.c = 45; 30: bitChar.d = 100.0; 31: bitChar.e = 7; 32: bitChar.f = 0x12345678; 33: cout<<"sizeof(bitChar) = "<<sizeof(bitChar)<<endl; 34: 35: system("PAUSE"); 36: return 0; 37: }
运行结果截图如下:
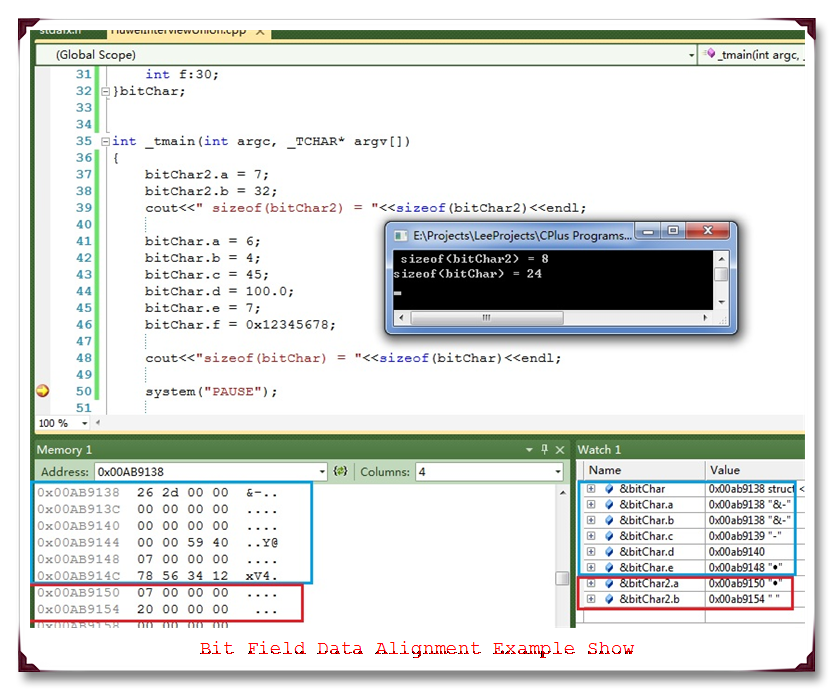
首先来分析bitChar2,因为满足规则f,在VC下不压缩,同时要满足规则a、b、c。所以第二个成员需要最低偏移量为4,第一个成员后需要填充3-byte。再看第二个bitChar,首先成员a、b满足规则d,故需要填充在0x00ab9138这个字节内,具体存储顺序见下图:
|
b:3 |
a:3 |
||||||
|
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
|
0 |
0 |
1 |
0 |
0 |
1 |
1 |
0 |
|
2 |
6 |
||||||
而第二个成员和第三个成员满足规则e,位域之和大于sizeof(char)=1的大小,所以需要一个偏移量。而第四个成员double=8为了满足规则b,必须在第三个成员之后填充6-byte,满足最小偏移量8。第五个成员不需要偏移,故无需填充。而第六个成员和第五个成员满足规则e,所以需要从新的存储单元开始存储,偏移量为int=4的整数倍,然后存储最后的成员e,中间需要填充3-byte。
由此可以得出总的大小为1 + 1 + 6 + 8 + 4 + 4 = 24,满足规则c,即是24 mode 8 = 0。
四,关于#pragma pack(n)
#pragma pack(push) //保存对齐状态
#pragma pack(n) /设置对齐模数(选择n和一般情况下选出来的模数的较小者做对齐模数)
#pragma pack(pop) //恢复对齐状态

