

Tensorflow之逻辑回归(基于MNIST数据集)
一、操作环境
tensorflow 1.13.0(建议使用1.几的版本 2.0很多地方都不兼容)
python 3.7.0(pycharm)
二、数据集的准备
将mnist数据集下载至指定目录位置
例:
无需解压。
Tensorflow导入mnist代码:
import tensorflow as tf import numpy as np from tensorflow.examples.tutorials.mnist import input_data import os import matplotlib.pyplot as plt os.environ["CUDA_VISIBLE_DEVICES"]="0" #导入mnist数据集 MINIST_data=r'D:\mnist' #数据集存放位置 mnist=input_data.read_data_sets(MINIST_data,one_hot=True) print("类型是 %s"%(type(mnist))) print (" 训练数据有 %d" % (mnist.train.num_examples)) print (" 测试数据有 %d" % (mnist.test.num_examples)) trainimg = mnist.train.images trainlabel = mnist.train.labels testimg = mnist.test.images testlabel = mnist.test.labels print (" 数据类型 is %s" % (type(trainimg))) print (" 标签类型 %s" % (type(trainlabel))) print (" 训练集的shape %s" % (trainimg.shape,)) print (" 训练集的标签的shape %s" % (trainlabel.shape,)) print (" 测试集的shape' is %s" % (testimg.shape,)) print (" 测试集的标签的shape %s" % (testlabel.shape,))
运行结果:
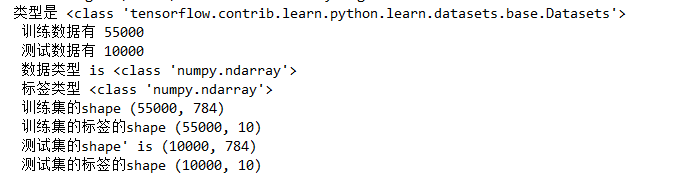
数据集解释
Mnist数据集是来自美国国家标准与技术研究所, National Institute of Standards and Technology (NIST). 训练集 (training set) 由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局 (the Census Bureau) 的工作人员. 测试集(test set) 也是同样比例的手写数字数据。
分为训练数据(train)和测试数据(test),训练集和测试集分别对应相应的lable(标签)
训练集的shape为(55000,784),55000是指有55000行图像,784=28*28理解为这些图像的长和宽,每张图由784个像素点组成。训练集的标签的shape是(55000, 10),55000还是指有55000张图像,10是指有10类标签,0到9一共是10个数据。每张图都会对应着这十类标签。
例如:这张图片为显示的数字为2 那么其对应的标签则是[0,0,1,0,0,0,0,0,0,0],同理若对应为8,则[0,0,0,0,0,0,0,0,1,0]
下面让我们来看一下图像具体样子
代码:
nsample=5 #随机挑选5张图 randidx = np.random.randint(trainimg.shape[0], size=nsample) #遍历 for i in randidx: curr_img=np.reshape(trainimg[i,:],(28,28)) curr_lable=np.argmax(trainlabel[i,:]) plt.matshow(curr_img,cmap=plt.get_cmap('gray')) print(""+str(i)+"th 训练数据"+"标签是"+str(curr_lable)) plt.show()
运行结果:

至此,对于MNIST数据集的理解也应该十分清楚了。
三、利用MNIST进行逻辑回归训练
完整代码如下:
import tensorflow as tf import numpy as np from tensorflow.examples.tutorials.mnist import input_data import os import matplotlib.pyplot as plt os.environ["CUDA_VISIBLE_DEVICES"]="0" #导入mnist数据集 MINIST_data=r'D:\mnist' #数据集存放位置 mnist=input_data.read_data_sets(MINIST_data,one_hot=True) #设置训练参数 learning_rate=0.01 #学习率 training_epochs=25 #跑完全部样本集的次数 batch_size=100 #定义批量梯度下降次数,每100张图计算一次 display_step=1 #构造计算图,使用占位符placeholder函数构造变量x,y, x=tf.placeholder(tf.float32,[None,784]) y=tf.placeholder(tf.float32,[None,10]) #使用Variable函数,设置模型的初始权重 W=tf.Variable(tf.zeros([784,10])) b=tf.Variable(tf.zeros([10])) #构造逻辑回归模型 #返回一个10维矩阵,[None,784]*[784,10]=[None,10] pred=tf.nn.softmax(tf.matmul(x,W)+b) #构造代价函数cost #-y*tf.log(pred):交叉熵代价函数 #reduce_sum() 求和 #reduce_mean() 求平均值,返回数字 cost=tf.reduce_mean(-tf.reduce_sum(y*tf.log(pred),reduction_indices=1)) #使用梯度下降法求最小值,即最优解 optimizer=tf.train.GradientDescentOptimizer(learning_rate).minimize(cost) #初始化全部变量 init=tf.global_variables_initializer() #使用tf.Session()创建Session会话对象,会话封装了Tensorflow运行时的状态和控制。 with tf.Session() as sess: sess.run(init) #跑总样本25次 for epochs in range(training_epochs): avg_cost=0 #记录训练集误差 total_batch=int(mnist.train.num_examples/batch_size)#一次训练一百,总数除以100 for i in range(total_batch): # 每次训练取100张图片(随机取一个batch_size) batch_xs,batch_ys=mnist.train.next_batch(batch_size) #返回一个[optimizer,cost]的list _,c=sess.run([optimizer,cost],feed_dict={x:batch_xs,y:batch_ys}) #返回训练100张图产生的训练误差 avg_cost+=c/total_batch #打印每次迭代产生的误差 if (epochs+1)%display_step==0: print("Epoch :", "%04d" % (epochs + 1), "Train_cost", "{:9f}".format(avg_cost)) print("Optimization finished!") #argmax返回数组中最大元素的位置 0代表按列算,1代表按行算 #tf.equal() 返回布尔值,判断对应元素是否相等,相等返回1,否则返回0 correct_prediction = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) print("Accuracy:", accuracy.eval({x: mnist.test.images[:3000], y: mnist.test.labels[:3000]}))
至于其中诸多函数用法,自行百度了解即可。
这里解释一下 我认为必要数据的含义
x(图片特征值):x=tf.placeholder(tf.float32,[None,784]) 此代码将图片表示为若干行,784列的数组。
w(特征值对应的权重):一开始这个值是随即设置,随着我们的不断训练得到最佳的权重
y(正确的结果):此结果来自MNIST标签训练集,此数据用于与我们机器学习预测的结果相比较,看是否预测正确,同时计算准确率
pred:机器学习预测的结果。
training_epochs:指的是遍历全部样本集的次数
batch_size:我们需要分好几次来遍历完全样本集,batch_size指的是每次分步提取出数据集的数量,例如样本集有5000个,batch_size=100时代表每次需分析100张图片,共迭代50次全部完成。
四、进一步分析预测结果
我们可以通过写代码来了解机器学习在哪出现了错误。
以下为代码:
print("VVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVV") for i in range(0, len(mnist.test.images)): result = sess.run(correct_prediction,feed_dict={x: np.array([mnist.test.images[i]]), y: np.array([mnist.test.labels[i]])}) if not result: print('预测的值是:', sess.run(pred, feed_dict={x: np.array([mnist.test.images[i]]), y: np.array([mnist.test.labels[i]])})) print('实际的值是:', sess.run(y, feed_dict={x: np.array([mnist.test.images[i]]), y: np.array([mnist.test.labels[i]])})) one_pic_arr = np.reshape(mnist.test.images[i], (28, 28)) pic_matrix = np.matrix(one_pic_arr, dtype="float") plt.imshow(pic_matrix) plt.show() break
我们来判断图片与测试是否正确,是通过比较pred(预测值)与y(真实数据)中最大数据(即为1)的位置来判断(参考argmax()函数用法),若位置相同,则返回true,位置不同,则返回false。利用这个原理可以写if语句,遇到错误,break循环,并打印出错的图片。
运行截图:

我们可以看到预测值中最大数值位置为6 预测图片数字为6 ,但真实数据为5.
打印图片为:
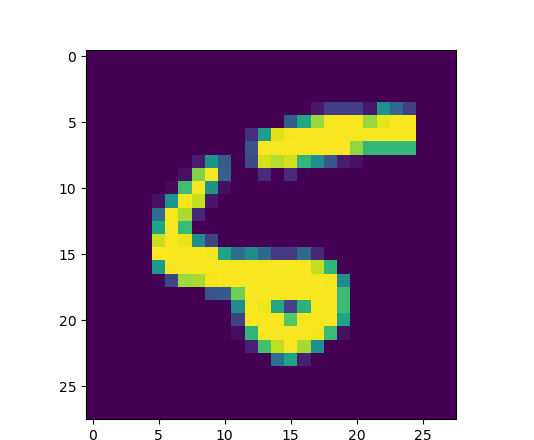
最后的最后附上全部完整代码:
import tensorflow as tf import numpy as np from tensorflow.examples.tutorials.mnist import input_data import os import matplotlib.pyplot as plt os.environ["CUDA_VISIBLE_DEVICES"]="0" #导入mnist数据集 MINIST_data=r'D:\mnist' #数据集存放位置 mnist=input_data.read_data_sets(MINIST_data,one_hot=True) #设置训练参数 learning_rate=0.01 #学习率 training_epochs=25 #跑完全部样本集的次数 batch_size=100 #定义批量梯度下降次数,每100张图计算一次 display_step=1 #构造计算图,使用占位符placeholder函数构造变量x,y, x=tf.placeholder(tf.float32,[None,784]) y=tf.placeholder(tf.float32,[None,10]) #使用Variable函数,设置模型的初始权重 W=tf.Variable(tf.zeros([784,10])) b=tf.Variable(tf.zeros([10])) #构造逻辑回归模型 #返回一个10维矩阵,[None,784]*[784,10]=[None,10] pred=tf.nn.softmax(tf.matmul(x,W)+b) #构造代价函数cost #-y*tf.log(pred):交叉熵代价函数 #reduce_sum() 求和 #reduce_mean() 求平均值,返回数字 cost=tf.reduce_mean(-tf.reduce_sum(y*tf.log(pred),reduction_indices=1)) #使用梯度下降法求最小值,即最优解 optimizer=tf.train.GradientDescentOptimizer(learning_rate).minimize(cost) #初始化全部变量 init=tf.global_variables_initializer() #使用tf.Session()创建Session会话对象,会话封装了Tensorflow运行时的状态和控制。 with tf.Session() as sess: sess.run(init) #跑总样本25次 for epochs in range(training_epochs): avg_cost=0 #记录训练集误差 total_batch=int(mnist.train.num_examples/batch_size)#一次训练一百,总数除以100 for i in range(total_batch): # 每次训练取100张图片(随机取一个batch_size) batch_xs,batch_ys=mnist.train.next_batch(batch_size) #返回一个[optimizer,cost]的list _,c=sess.run([optimizer,cost],feed_dict={x:batch_xs,y:batch_ys}) #返回训练100张图产生的训练误差 avg_cost+=c/total_batch #打印每次迭代产生的误差 if (epochs+1)%display_step==0: print("Epoch :", "%04d" % (epochs + 1), "Train_cost", "{:9f}".format(avg_cost)) print("Optimization finished!") #argmax返回数组中最大元素的位置 0代表按列算,1代表按行算 #tf.equal() 返回布尔值,判断对应元素是否相等,相等返回1,否则返回0 correct_prediction = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) print("Accuracy:", accuracy.eval({x: mnist.test.images[:3000], y: mnist.test.labels[:3000]})) print("VVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVV") for i in range(0, len(mnist.test.images)): result = sess.run(correct_prediction,feed_dict={x: np.array([mnist.test.images[i]]), y: np.array([mnist.test.labels[i]])}) if not result: print('预测的值是:', sess.run(pred, feed_dict={x: np.array([mnist.test.images[i]]), y: np.array([mnist.test.labels[i]])})) print('实际的值是:', sess.run(y, feed_dict={x: np.array([mnist.test.images[i]]), y: np.array([mnist.test.labels[i]])})) one_pic_arr = np.reshape(mnist.test.images[i], (28, 28)) pic_matrix = np.matrix(one_pic_arr, dtype="float") plt.imshow(pic_matrix) plt.show() break
五、感谢
https://www.cnblogs.com/lizheng114/p/7439556.html
https://www.lizenghai.com/archives/47834.html#121_tensorflow(解释十分全面)

