
CUDA ---- Constant Memory
CONSTANT MEMORY
constant Memory对于device来说只读但是对于host是可读可写。constant Memory和global Memory一样都位于DRAM,并且有一个独立的on-chip cache,比直接从constant Memory读取要快得多。每个SM上constant Memory cache大小限制为64KB。
constant Memory的获取方式不同于其它的GPU内存,对于constant Memory来说,最佳获取方式是warp中的32个thread获取constant Memory中的同一个地址。如果获取的地址不同的话,只能串行的服务这些获取请求了。
constant Memory使用__constant__限定符修饰变量。
constantMemory的生命周期伴随整个应用程序,并且可以被同一个grid中的thread和host中调用的API获取。因为constant Memory对device来说是可读的,所以只能在host初始化,使用下面的API:
cudaError_t cudaMemcpyToSymbol(const void *symbol, const void * src, size_t count, size_t offset, cudaMemcpyKind kind)
Implementing a 1D Stencil with Constant Memory
实现一个1维Stencil(数值分析领域的东,卷积神经网络处理图像的时候那个stencil),简单说就是计算一个多项式,系数放到constant Memory中,即y=f(x)这种东西,输入是九个点,如下:
{x − 4h, x − 3h, x − 2h, x − h, x, x + h, x + 2h, x + 3h, x + 4h}
在内存中的过程如下:

公式如下:

那么要放到constant Memory中的便是其中的c0、c1、c2 ……
因为每个thread使用九个点来计算一个点,所以可以使用shared memory来降低延迟。
__shared__ float smem[BDIM + 2 * RADIUS];
RADIUS定义了x两边点的个数,对于本例,RADIUS就是4。如下图所示,每个block需要RADIUS=4个halo(晕)左右边界:

#pragma unroll用来告诉编译器,自动展开循环。


__global__ void stencil_1d(float *in, float *out) { // shared memory __shared__ float smem[BDIM + 2*RADIUS]; // index to global memory int idx = threadIdx.x + blockIdx.x * blockDim.x; // index to shared memory for stencil calculatioin int sidx = threadIdx.x + RADIUS; // Read data from global memory into shared memory smem[sidx] = in[idx]; // read halo part to shared memory if (threadIdx.x < RADIUS) { smem[sidx - RADIUS] = in[idx - RADIUS]; smem[sidx + BDIM] = in[idx + BDIM]; } // Synchronize (ensure all the data is available) __syncthreads(); // Apply the stencil float tmp = 0.0f; #pragma unroll for (int i = 1; i <= RADIUS; i++) { tmp += coef[i] * (smem[sidx+i] - smem[sidx-i]); } // Store the result out[idx] = tmp; }
Comparing with the Read-only Cache
Kepler系列的GPU允许使用texture pipeline作为一个global Memory只读缓存。因为这是一个独立的使用单独带宽的只读缓存,所以对带宽限制的kernel性能有很大的提升。
Kepler的每个SM有48KB大小的只读缓存,一般来说,在读地址比较分散的情况下,这个只读缓存比L1表现要好,但是在读同一个地址的时候,一般不适用这个只读缓存,只读缓存的读取粒度为32比特。
有两种方式来使用只读缓存:
- 使用__ldg限定
- 指定特定global Memory称为只读缓存
下面代码片段对于第一种情况:
__global__ void kernel(float* output, float* input) { ... output[idx] += __ldg(&input[idx]); ... }
下面代码对应第二种情况,使用__restrict__来指定该数据的要从只读缓存中获取:
void kernel(float* output, const float* __restrict__ input) { ... output[idx] += input[idx]; }
一般使用__ldg是更好的选择。通过constant缓存存储的数据必须相对较小而且必须获取同一个地址以便获取最佳性能,相反,只读缓存则可以存放较大的数据,且不必地址一致。
下面的代码是之前stencil的翻版,使用过了只读缓存来存储系数,二者唯一的不同就是函数的声明:
__global__ void stencil_1d_read_only (float* in, float* out, const float *__restrict__ dcoef) { // shared memory __shared__ float smem[BDIM + 2*RADIUS]; // index to global memory int idx = threadIdx.x + blockIdx.x * blockDim.x; // index to shared memory for stencil calculatioin int sidx = threadIdx.x + RADIUS; // Read data from global memory into shared memory smem[sidx] = in[idx]; // read halo part to shared memory if (threadIdx.x < RADIUS) { smem[sidx - RADIUS] = in[idx - RADIUS]; smem[sidx + BDIM] = in[idx + BDIM]; } // Synchronize (ensure all the data is available) __syncthreads(); // Apply the stencil float tmp = 0.0f; #pragma unroll for (int i=1; i<=RADIUS; i++) { tmp += dcoef[i]*(smem[sidx+i]-smem[sidx-i]); } // Store the result out[idx] = tmp; }
由于系数原本是存放在global Memory中的,然后读进缓存,所以在调用kernel之前,我们必须分配和初始化global Memory来存储系数,代码如下:
const float h_coef[] = {a0, a1, a2, a3, a4}; cudaMalloc((float**)&d_coef, (RADIUS + 1) * sizeof(float)); cudaMemcpy(d_coef, h_coef, (RADIUS + 1) * sizeof(float), cudaMemcpyHostToDevice);
下面是运行在TeslaK40上的结果,从中可知,使用只读缓存性能较差。
Tesla K40c array size: 16777216 (grid, block) 524288,32 3.4517ms stencil_1d(float*, float*) 3.6816ms stencil_1d_read_only(float*, float*, float const *)
总的来说,constant缓存和只读缓存对于device来说,都是只读的。二者都有大小限制,前者每个SM只能有64KB,后者则是48KB。对于读同一个地址,constant缓存表现好,只读缓存则对地址较分散的情况表现好。
The Warp Shuffle Instruction
之前我们有介绍shared Memory对于提高性能的好处,在CC3.0以上,支持了shuffle指令,允许thread直接读其他thread的寄存器值,只要两个thread在 同一个warp中,这种比通过shared Memory进行thread间的通讯效果更好,latency更低,同时也不消耗额外的内存资源来执行数据交换。
这里介绍warp中的一个概念lane,一个lane就是一个warp中的一个thread,每个lane在同一个warp中由lane索引唯一确定,因此其范围为[0,31]。在一个一维的block中,可以通过下面两个公式计算索引:
laneID = threadIdx.x % 32
warpID = threadIdx.x / 32
例如,在同一个block中的thread1和33拥有相同的lane索引1。
Variants of the Warp Shuffle Instruction
有两种设置shuffle的指令:一种针对整型变量,另一种针对浮点型变量。每种设置都包含四种shuffle指令变量。为了交换整型变量,使用过如下函数:
int __shfl(int var, int srcLane, int width=warpSize);
该函数的作用是将var的值返回给同一个warp中lane索引为srcLane的thread。可选参数width可以设置为2的n次幂,n属于[1,5]。
eg:如果shuffle指令如下:
int y = shfl(x, 3, 16);
则,thread0到thread15会获取thread3的数据x,thread16到thread31会从thread19获取数据x。
当传送到shfl的lane索引相同时,该指令会执行一次广播操作,如下所示:

另一种使用shuffle的形式如下:
int __shfl_up(int var, unsigned int delta, int width=warpSize)
该函数通过使用调用方的thread的lane索引减去delta来计算源thread的lane索引。这样源thread的相应数据就会返回给调用方,这样,warp中最开始delta个的thread不会改变,如下所示:

第三种shuffle指令形式如下:
int __shfl_down(int var, unsigned int delta, int width=warpSize)
该格式是相对__shfl_down来说的,具体形式如下图所示:

最后一种shuffle指令格式如下:
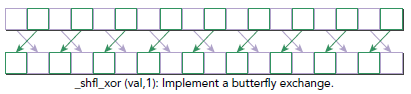
int __shfl_xor(int var, int laneMask, int width=warpSize)
这次不是加减操作,而是同laneMask做抑或操作,具体形式如下图所示:
所有这些提及的shuffle函数也都支持单精度浮点值,只需要将int换成float就行,除此外,和整型的使用方法完全一样。
转载请注明来源:博客园-吉祥
参考书:《professional cuda c programming》
NVIDIA CUDA板块:https://developer.nvidia.com/cuda-zone

 浙公网安备 33010602011771号
浙公网安备 33010602011771号