linux正则表达式1--grep
正则表达式含义
为处理大量的字符串及文本而定义的一套规则和方法。使得运维工作更加高效。
以行为单位处理,一次处理一行。
适用于三剑客命令
grep(egrep)、sed、awk
环境配置
alias egrep = 'egrep --color=auto' 过滤的内容用红色显示
export LC_ALL=C 配置后操作时不会出现异常匹配情况
cat >>/etc/profile<<EOF
> export LC_ALL=C
> EOF
正则表达式分类
基本正则表达式(BRE basic regular expression) 对应元字符:^$.[]* 使用grep命令
扩展正则表达式(ERE extended regular expression) 增加元字符:(){}?+| 使用egrep命令或grep -E
基本正则
^ 以什么开头(每一行),例 ^t 以字母t开头的每一行
$ 以什么结尾(每一行),例 t$ 以字母t结尾的每一行
^$ 空行
. 匹配任意一个且只有一个字符
\ 转义字符,让有意义的字符回归本义
* 匹配前面一个字符任意次数
.* 匹配所有内容,包含空行
^.* 以任意次数的任意字符开头的内容
.*$ 以任意次数的任意字符结尾的内容
[abc] 匹配中括号内任意一个字符,例 [a-z]
[^abc] 匹配不包含中括号内的任意一个字符
扩展正则
+ 匹配前一个字符1次或多次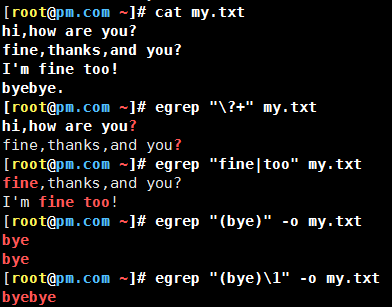
[:/]+ 匹配 : 或 / 一次或多次
? 匹配前一个字符0次或1次
| 或者,即同时过滤多个选项
{n,m} 匹配前一个字符至少n次,至多m次
{n,} 匹配前一个字符至少n次
{,m} 匹配前一个字符至多m次
{n} 匹配前一个字符n次
() 括号内的内容视为一个整体
\n (a)(b)\1\2 相当于 abab
注:在同一条命令中,\1代表第一个括号内的内容,一次类推。
元字符表达式
\b 空边界 \B 非空边界

\w 匹配任意一位字母或数字或下划线
\W 匹配任意一位 非 字母或数字或下划线
\d 匹配单个数字字符,必须结合grep -P使用
\D 匹配单个非数字字符,必须结合grep -P使用
\s 匹配任意空白字符
\S 匹配任意非空白字符
预定义正则表达式(很少用)