大数据基础复习
(概要)第一章
- 信息科技需要处理的三大核心问题
- 第一次浪潮:信息处理
- 第二次浪潮:信息传输
- 第三次浪潮:信息爆炸
- 数据产生方式的变革
- 运营式系统阶段:数据往往伴随着一定的运营活动而产生并记录在数据库中
- 用户原创内容阶段:Web2.0时代的到来,而其最重要的标志就是用户原创内容
- 感知式系统阶段:人类社会数据量的飞跃导致大数据的产生
- 大数据4V的概念
- 数据量大(信息爆炸,web2.0)
- 数据类型繁多
- 是由结构化和非结构化数据组成
- 处理速度快
- 价值密度低(一大堆数据真正有用的数据不多)
- 大数据对思维方式的影响(选择题)
- 全样而非抽样
- 效率而非精确(采用的方法)
- 相关而非因果
- 大数据应用四大层面的关键技术
- 数据采集和预处理(大量的数据是非结构化的,就需要经过清洗和转换)
- 数据存储和管理(比如利用分布式文件系统、NoSQL数据库)
- 数据处理和分析(利用分布式计算,不同数据分布到不同的结点)
- 数据隐私和安全
- 大数据四大计算模式:除图计算外详细了解
- 批处理计算:针对大规模数据的批量处理(Mapreduce,Spark)
- 流计算:针对流数据的实时计算(突然冒出的数据,比如淘宝买东西),数据的价值随时间流逝的而降低
- 图计算 Pregel
- 查询分析计算:从一堆数据找出我要的数据
- 云计算关键技术
- 虚拟化(将一台实际计算机虚拟成多台逻辑计算机)
- 分布式存储
- 分布式计算(MapReduce)
- 多租户(使得大量用户能够共享同一堆栈的软硬件资源)
- 物联网关键技术
- 识别和感知技术(二维码、传感器)
- 网络与通信技术
- 数据挖掘和融合技术
(hdfs)第二章、第三章
- 分布式文件系统的概念
是一种通过网络实现文件在多台主机上进行分布式存储的文件系统。
- HDFS文件块
- 将一个文件分成若干块,分散到多个节点。
- 注意:HDFS无法高效的存储小文件
- HDFS设计的块大小要大于传统的文件系统
- 最小化寻址开销
- 优点
- 支持大规模文件存储,切成小块容易存放东西
- 简化系统设计(文件块大小是固定的,容易计算一个节点可以存储多少个文件块)
- 适合数据备份(可以冗余存储,提高容错性)
- 将一个文件分成若干块,分散到多个节点。
- 名称节点、数据节点的功能和工作原理
- 主节点
- 功能:存储元数据,保存在内存中
- 工作原理:名称节点启动,将FsImage(文件系统视图)的内容加载到内存中,然后执行EditLog文件的各个操作,使得内存元数据保持最新。名称节点正常启动,HDFS的更新操作会写入到Editlog。
- 从节点
- 功能:负责数据的存储(存在磁盘)和读取
- 主节点
- 第二名称节点的意义与功能(简答题)
- 可以完成EditLog与FsImage的合并操作,减少EditLog文件大小,缩短名称节点重启时间
- 工作流程
- 名称节点使用新的日志
- 第二名称节点从名称节点获得FsImage和EditLog
- 合并
- 把检查点回传给名称节点(FsImage)
- 将名称节点的FsImage和EditLog替换
- 工作流程
- 作为名称节点的“检查点”,保存名称节点元数据信息
- 名称节点发生故障时,可以用第二节点的FSImage和EditLog替换
- 但是,如果在上面5的时候发生错误也有数据更新,就还是会丢失数据。
- 可以完成EditLog与FsImage的合并操作,减少EditLog文件大小,缩短名称节点重启时间
- HDFS冗余存储的定义和意义
- 定义:一个数据块的多个副本会被分布到不同的数据节点上
- 意义:
- 加快数据传输速度
- 容易检查数据错误
- 保证数据的可靠性(某一个节点发生故障,也不会造成数据丢失)
- HDFS数据存放策略、读取策略
- 存放策略
- HDFS默认的冗余复制因子3
- 两份副本放在同一个机架的不同机器上
- 第三个放在不同机架的机器上面
- 读取策略
- 客户端可以调用HDFS提供的确定一个数据节点所属的机架ID的API
- 从名称节点获得数据块不同副本的存放位置
- 发现某个数据块副本对应的机架ID和客户端对应的机架ID相同,优先选择改副本读取
- 否则随机选一个
- HDFS三种数据错误及其恢复方法
- namenode出错:首先到远程挂载的网络文件系统中获取备份的数据信息,放到第二名称节点上进行恢复,并把第二名称节点作为名称节点来使用
- datanode出错:datanode会向namenode发送“心跳信息”,如果namenode收不到“心跳信息”,namenode不会发送任何IO请求,datanode会标记成"宕机",当副本数量小于冗余因子,就会启动数据冗余复制
- data出错:读取文件,数据块校验出错,客户端请求到另外一个数据节点读取文件块
- 存放策略
(hbase)第四章
-
Hbase生态系统
- 利用Hadoop MapReduce来处理Hbase的海量数据
- 利用Zookeeper作为协同服务,实现稳定服务和失败恢复
- 使用HDFS作为高可靠的底层存储
-
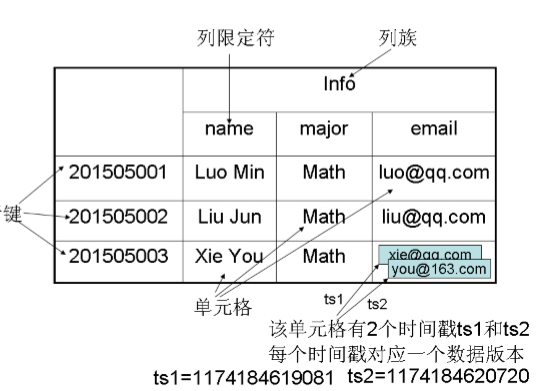
Hbase的数据模型相关概念
- 列族是存储的基本单位
-
数据坐标的含义
- [行键,列族,列限定符,时间戳]
-
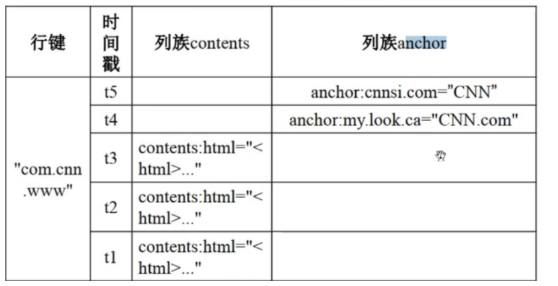
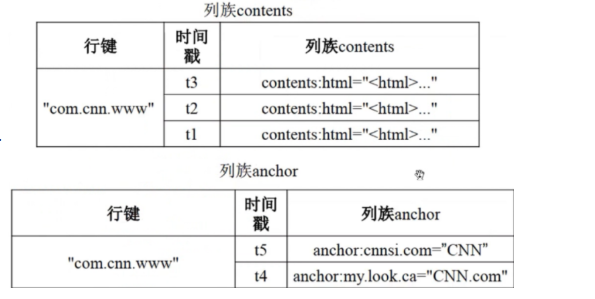
概念视图和物理视图
-
-
-
从概念视图看:Hbase由许多行组成,但是在物理视图上,它采用了基于列的存储方式
-
Hbase的三层结构
-
层次 名称 作用 第一层 Zookeeper文件 记录了-ROOT-表的位置信息 第二层 -Root-表 记录了.META.表的Region信息;通过-ROOT-表,就可以访问.META表中的数据 第三层 .META.表 记录用户数据表的Region位置信息,保存了Hbase中所有的用户数据表的Region位置信息
-
(NoSQL)第五章
-
NoSQL数据库的含义与特点
-
含义:是对非关系型数据库的统称
-
特点:
- 灵活的扩展性
- 灵活的数据模型
- 与云计算紧密融合
-
-
关系数据库在WEB 2.0时代的局限 与WEB 2.0不适用关系型数据库的原因
- 局限
- 无法满足海量数据的管理需求
- 无法满足数据高并发的需求
- 无法满足高扩展性和高可用性的需求
- 原因
- web2.0网站系统通常不要求严格的数据库事务
- web2.0并不要求严格的读写实时性
- web2.0通常不包括大量复杂的SQL查询
- 四大类型NoSQL数据库的定义,特点,代表性产品
- 键值数据库
- 使用特定的哈希表
- 键值放在内存,可以直接存,直接取
- Redis,Memcached
- 列族数据库
- 数据库由多个行构成,每行数据包含多个列族
- 可扩展性强
- Hbase,BigTable
- 文档数据库
- 文档数据库通过键来定义一个文档
- 性能好,数据结构灵活
- MongDB
- 图数据库
- 使用图作为数据模型来存储数据,高效存储不同顶点之间的关系
- 适合图结构场景
- Neo4J
- NOSQL的三大基石, 理解三大要点的准确意义和内容,要求全部掌握,并能用自己语言说明
- CAP
- C一致性:多点的数据是一致的
- A可用性:在确定时间返回操作结果,保证每个请求成功失败都有响应
- P分区容忍性:系统任意信息丢失、失败不会系统继续运行
- CAP理论告诉我们一个分布式系统不可能满足三个,最多只有2个
- CA 把所有事物相关的内容放在同一台机器上,比如传统数据库MySQL
- 当出现网络分区,受影响的服务需要等待数据一致,等待期间无法对外服务,比如NoSQL
- 允许写回的数据不一致,比如NoSQL
- BASE
- 基本可用
- 一个分布式系统一部分发生问题不可以用,其他部分仍然可用
- 软状态
- 有一段时间数据不同步,具有一定的滞后性
- 最终一致性
- 基本可用
- 最终一致性
- 因果一致性:进程A改了数据,通知进程B.B后续访问的一定是A的最新值
- ”读己之所写“一致性:自己改的数据,自己读的一定是最新值
- 单调读一致性:进程已经看到过数据对象的某个值,那么后续访问都不会返回在那个值之前的值
- CAP
- 键值数据库
- 局限
(云数据库) 第六章
-
云数据库的概念:部署和虚拟化在云计算环境中的数据库(简答)
-
云数据库的特性:(选择题)
- 动态可扩展
- 高可用性
- 较低的使用代价
- 易用性
- 高性能
- 免维护
- 安全
(MapReduce)第七章、第八章
MapReduce基本概念与计算向数据靠拢
- MapReduce是一个分布式并行编程框架,将大规模数据集切分成很多独立小数据块,被多个Map任务并行处理,完成的结果由Reduce合并,写入分布式文件系统
- 理念:计算向数据靠拢
- 数据放在不同服务器,根据服务器已有的数据算一部分再传到需要的服务器上,从而减少网络开销
MapReduce工作流程与各个执行阶段工作
- 分而治之;将大规模数据集切分成很多独立小数据块,被多个Map任务并行处理,完成的结果由Reduce合并,写入分布式文件系统
- 阶段工作
- 使用InputFormat模块做Map前的预处理,将输入文件切分成逻辑上多个InputSplit
- 需要通过RR处理InputSplit的具体内容,输入给Map任务
- Map根据用户自定义的映射规则,输出一系列中间结果<key,value>
- 经过Shuffle,从无序的<key,value>转成<key,value-list>
- 将中间结果<key,value-list>输入到Reduce,之后输出给OutputFormat
- OutputFormat验证成功后,输出Reduce结果到分布式文件系统
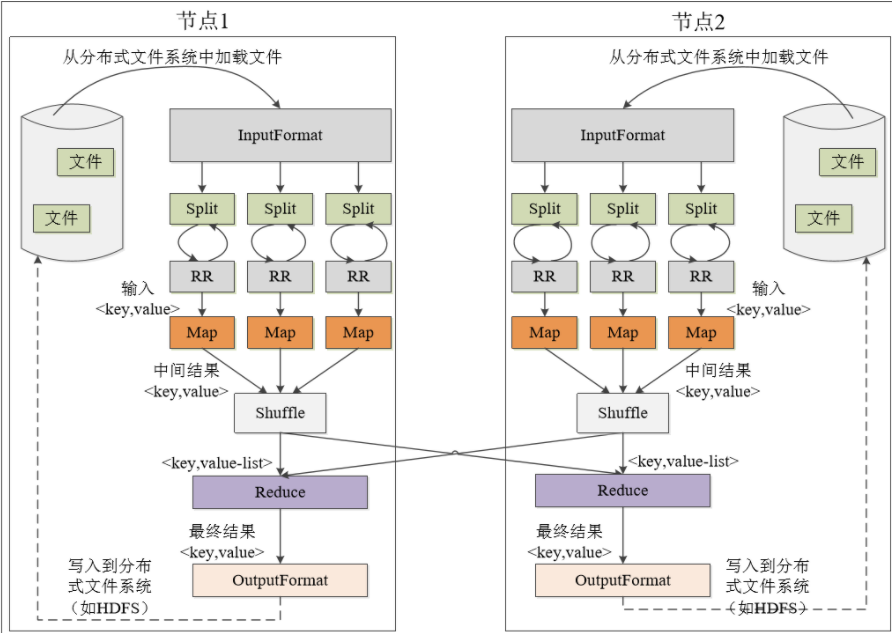
MapReduce的WORKCOUNT执行实例计算过程
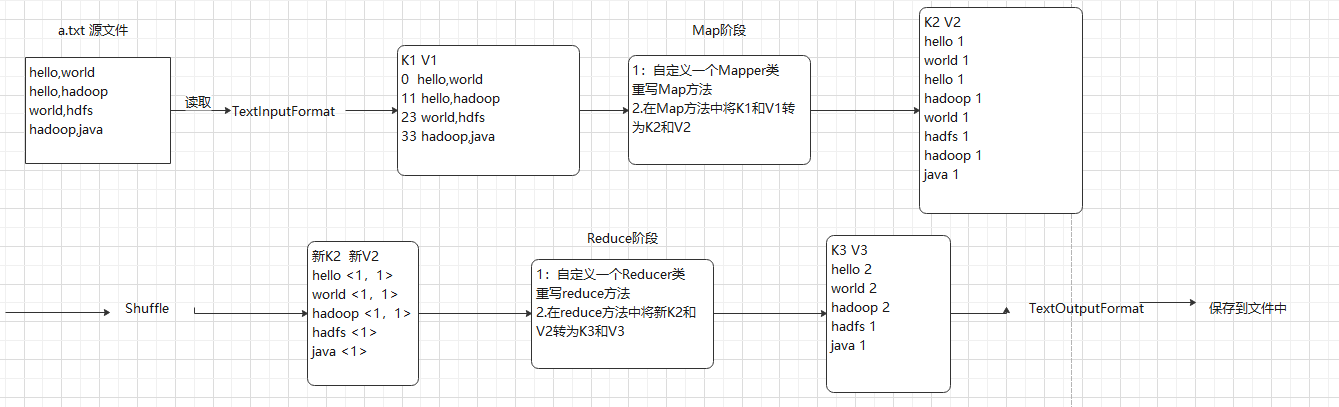
MapReduce实现关系运算
主要了解自然连接
(Spark)第九章
-
Spark与Hadoop对比,Spark高性能的原因
- Spark的计算模式也是属于MapReduce,但不局限于Map和Reduce操作,还提供了多种数据集操作类型
- Spark提供了内存计算,中间结果放在内存 中,带来更高的迭代运算效率
- Spark基于DAG的任务调度执行机制,优于MapReduce的迭代执行机制
-
大数据处理的三种类型与其适用的Spark技术栈(选择题)
-
类型 Spark技术栈 复杂的批量数据处理 Spark Core 基于历史数据的交互式查询 Spark SQL 基于实时数据流的数据处理 Spark Streaming
-
-
RDD的设计与运行原理
- 概念:RDD(弹性分布式数据集)是只读的记录分区的集合
- 数据运算:收集(Collection)和转换(Transfomation)
- 依赖关系:
- 窄依赖:一个RDD对应一个父RDD
- 宽依赖:一个RDD对应多个父RDD
- 执行过程
- 创建一个RDD对象
- SparkContext负责计算RDD之间的依赖关系,构造DAG
- DAGScheduler负责把DAG图分解成多个阶段,每个阶段包含多个任务,每个任务分发给各个工作节点上的Executor去执行
(流计算)第十章
- 流数据的特征
- 数据快速持续到达
- 数据众多
- 数据量大
- 注重数据的整体价值
- 数据顺序颠倒或不完整
- 批量计算与实时计算的含义
- 批量计算以“静态数据”为对象,可以在充裕的时间内对海量数据进行批量处理,计算得到有 价值的信息
- 实时计算最重要的一个需求是能够实时得到计算结果,一般要求响应时间为秒级
- 流计算的要求,Hadoop不合适流计算的原因
- 需求
- 高性能:每秒处理几万条数据
- 海量式:数据规模
- 实时性:秒级
- 分布式
- 易用性
- 可靠性
- Hadoop不合适流计算的原因
- MapReduce切成小的片段增加了任务处理的开销,还需要处理片段之前的关系
- 如果一定要使用MapReduce,需要改造以支持流式处理
- 降低用户程序的可伸缩性,因为用户必须使用MapReduce接口来定义流式作业
- 需求
- 流计算处理流程
- 数据实时采集
- 数据采集系统的基本架构包括 Agent、Collector、Store
- 数据实时计算
- 实时查询服务
- 数据实时采集
