(二)SQL语句
语法规则
- 不区分大小写,但是建议关键字大写,表名、列名小写
SELECT * FROM user;
- 支持多行编写sql语言(在SQLyog中可以用F12来快速格式化语句)
# 查询cno=20201/20202 sno=2020004的值
SELECT
grade as grade1,
(SELECT
grade
FROM
sc
WHERE sno = "2020004"
AND cno = "20201") AS grade2
FROM
sc
WHERE sno = "2020004"
AND cno = "20202"
执行顺序
sql语句的编写顺序
SQL语句的编写顺序:select ----from---- where---- group by ----having ----order by
sql语句的执行顺序
SQL语句的执行顺序:from-----where------group by------having ----select-----order by
DQL语言
数据库查询语言
基础查询
#1. 查询常量值
select 100;
#2. 查询表达式
select 100%9;
#3. 查询函数
select version();
#4. 去重
SELECT DISTINCT sno FROM sc
#5. +号的作用:只能做运算符
select 100+90 =190
select '100'+90 =190
select 'num'+90=0+90=90
select null+10 =null 只要一方为null,结果就是null
#6. 拼接 concat('a','b')
SELECT CONCAT(mno,mname) AS "m all" FROM major
模糊查询
select * from stu where sname like "_张"; --小张 x张
# _ 匹配单个任意字符
select length("a张") --output 4
-- 查看当前的编码
SHOW VARIABLES LIKE '%char%'
--其中有一条结果 character_set_client utf8
-- 在utf8中每一个汉字占3个字节,gbk是2字节
条件查询
in
select * from sc where sno="C001" or sno="C002";
等价于 select * from sc where sno in ('C001','C002');
∴ select * from sc where sno in ('C001','C%');
等价于 select * from sc where sno = ‘C001’ or sno='C%';
结论:通配符在in中是不生效的,是= 不是like
排序查询
# 先按成绩降序 再按sno升序
select * from sc order by grade desc ,sno ;
特点:
asc【默认升序】 desc 降序
oder by 子句一般放在查询语句的最后面,limit子句除外
聚合函数
sum 求和
avg 平均值
max 最大值
min 最小值
count 计算个数
1. 以上函数都忽略null值
select count(*) from stu 统计行数(因为只要有一列的不为null,就会统计进去)
2. 可以和distinct一起使用实现去重
select count(distinct sno) from stu;
group by 分组
1. 【ERROR】select mno,count(*) from stu group by mno where count(*)>2
where 后面的跟的必须是表中有的字段,而表中没有count(*)字段
∵是根据分组后再进行筛选,∴在group by 后面加 having
小结:
where 分组前筛选放group by前
having 分组后筛选放group by后
连接查询
分类
左连接:取左边的表的全部,右边的表按条件,符合的显示,不符合则显示null
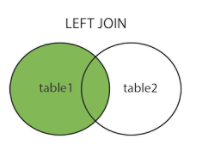
右连接:取右边的表的全部,左边的表按条件,符合的显示,不符合则显示null
内连接:返回两张表都满足条件的部分
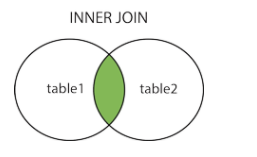
语法
select 查询列表
from 表1 别名
inner/left outer/right outer/full join 表二 别名
on 连接条件;
SELECT sname,cname,grade
FROM sc
INNER JOIN stu s ON sc.`sno`=s.`sno`
INNER JOIN cou c ON sc.`cno`=c.`cno`;
SELECT sname,mname
FROM stu
LEFT OUTER JOIN major ON stu.`mno`=major.`mno`
子查询
出现在其他语句中的select语句,称为子查询
分类
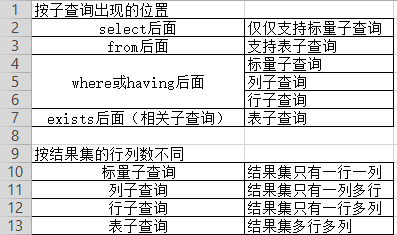
where或having后面 (☆)
子查询特点
①子查询放在小括号内
②子查询一般放在条件的右侧
③标量子查询,一般搭配这单行操作符使用 > < >= <= <>
④列子查询,一般搭配着多行操作符使用 in
--1. 标量子查询
案例: 谁的年龄比`小点`大?
一、查询大大的年龄
SELECT age FROM stu WHERE sname="小点"
二、查询谁的年龄比`小点`大?
SELECT sname FROM stu
WHERE age>(
SELECT age
FROM stu
WHERE sname LIKE "小点"
)
--2.列子查询
案例:返回专业名包含"工程"的总学生人数
SELECT COUNT(*)
FROM stu
WHERE stu.`mno` IN (
SELECT mno
FROM major
WHERE mname LIKE '%工程%'
)
select后面
-- 1.查询学号是20200016学生的20201和20202的总分
SELECT grade+(
SELECT grade
FROM sc
WHERE cno="20201" AND sno='20200016') AS tol
FROM sc
WHERE cno="20202" AND sno='20200016'
from后面
注意点:将子查询结果充当一张表,要求必须起别名
exists后面(相关子查询)
exists返回的结果1或0
分页查询
语法
在sql最后添加
limit offset,size
offset 要显示条目的起始索引(从0开始)
size 要显示条目的个数
-- 查询前五条学生的信息,学号倒序
SELECT * FROM stu ORDER BY sno DESC LIMIT 0,5
联合查询
union 合并 :将多条查询语句的结果合并成一个结果
应用场景:
要查询的结果来自多个表,且多个表没有直接的连接关系,但查询的信息一致时
特点:
1. 要求多条查询语句的列数是一致的,否则报错
2. 要求多条查询语句的查询的每一列的类型和顺序最好一致
3. union 默认会去重,union all 可以包含重复项
select id,name from stu
union
select id,tname from tea;
DML语言
数据库操作语言
添加
-- 插入多值
INSERT INTO `grade`(`name`) VALUES('大二'),('大三')
-- 支持子查询
INSERT INTO sc
SELECT * FROM sc_copy
修改
-- 联表修改的记录
-- 案例:修改软件工程的所有学生年龄+1
update stu
inner join major on stu.mno=major.mno
set stu.age=stu.age+1
where major.mname="软件工程"
删除
delete 和 truncate 区别
1. delete 可以加where条件,truncate 不行
语法:
delete from stu where sname="大大"
truncate table stu
2. truncate 删除,效率高一点
因为他没有where
3. 假如要删除的表中有自增长列(auto_increment),如果用delete删除后,再删除从断点开点
truncate清空表后,从1开始
4.delee删除有返回值,truncate删除没有返回值
delete eg:共3行受到影响
truncate eg:共0行受到影响
5.truncate删除不能回滚,delete删除可以回滚
DDL语言
数据库定义语言
创建表
# id自动增长
# 在name字段上建立一个唯一性索引
create table user(
id int auto_increment,
name varchar(30) unique,
unique index user_index(name)
)
# 给id创建一个普通索引
create table user(
id int,
index(id)
)
# 复制表
CREATE TABLE sc1
SELECT * FROM sc
WHERE 1=2
常见数据类型
整型、浮点型、字符型、日期型
varchar和char的区别
varchar的长度是可变 ,而char的长度是固定的。所以,查找的时候,char的效率更高。
常见约束
六大约束
not null 非空 用于保证该字段不能为空
default 默认,用于保证该字段有默认值,比如性别 default '男'
primary key 非空且唯一
unique 保证字段唯一,可以为空,比如:手机号
foreign key 外键
check 检查【在mysql中不支持】
最佳实践
-
数据库就是单纯的表,只是用来存放行和列
-
如果想使用外键,程序实现
约束添加分类
| 列级约束(在字段后加) | 表级约束(在表所有字段最后加) |
|---|---|
| 六大约束都支持,除了外键约束没有效果 | 除了非空、默认,其他都支持 |
| age int default 18 | foreign key(mno) references major(mno) |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号