

linux 3.10 一次softlock排查
x86架构。一个同事分析的crash,我在他基础上再次协助分析,也没有获得进展,只是记录一下分析过程。记录是指备忘,万一有人解决过,也好给我们点帮助。
有一次软锁,大多数cpu被锁,log中第一个认为被锁的cpu已经被冲掉了,直接敲入log,总共24个cpu,首先看到的是17cpu的堆栈,分析如下:
[ 4588.212690] CPU: 17 PID: 9745 Comm: zte_uep1 Tainted: G W OEL ------------ T 3.10.0-693.21.1.el7.x86_64 #1 [ 4588.212691] Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS rel-1.10.2-0-g5f4c7b1-prebuilt.qemu-project.org 04/01/2014 [ 4588.212692] task: ffff880a3d364f10 ti: ffff880aa7fd8000 task.ti: ffff880aa7fd8000 [ 4588.212693] RIP: 0010:[<ffffffff810fe46a>] [ 4588.212696] [<ffffffff810fe46a>] smp_call_function_many+0x20a/0x270 [ 4588.212697] RSP: 0018:ffff880aa7fdbcb0 EFLAGS: 00000202 [ 4588.212698] RAX: 0000000000000006 RBX: 00080000810706a0 RCX: ffff880b52b9bfa0 [ 4588.212698] RDX: 0000000000000006 RSI: 0000000000000018 RDI: 0000000000000000 [ 4588.212699] RBP: ffff880aa7fdbce8 R08: ffff880beeb51c00 R09: ffffffff8132a699 [ 4588.212700] R10: ffff88169235abc0 R11: ffffea0057afa800 R12: 0000000000000282 [ 4588.212701] R13: 0000000000000282 R14: ffff880aa7fdbc60 R15: 0000000000000001 [ 4588.212702] FS: 00007fbd936f6700(0000) GS:ffff881692340000(0000) knlGS:0000000000000000 [ 4588.212703] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 [ 4588.212704] CR2: 00007fbd6c004d80 CR3: 00000015c7fa6000 CR4: 00000000001606e0 [ 4588.212706] DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000 [ 4588.212707] DR3: 0000000000000000 DR6: 00000000ffff0ff0 DR7: 0000000000000400 [ 4588.212707] Call Trace: [ 4588.212708] [ 4588.212712] [<ffffffff81070868>] native_flush_tlb_others+0xb8/0xc0 [ 4588.212712] [ 4588.212714] [<ffffffff81070938>] flush_tlb_mm_range+0x68/0x140 [ 4588.212714] [ 4588.212717] [<ffffffff811b3493>] tlb_flush_mmu.part.63+0x33/0xc0 [ 4588.212717] [ 4588.212719] [<ffffffff811b47b5>] tlb_finish_mmu+0x55/0x60 [ 4588.212719] [ 4588.212721] [<ffffffff811b6d3a>] zap_page_range+0x13a/0x180 [ 4588.212721] [ 4588.212723] [<ffffffff811bf0be>] ? do_mmap_pgoff+0x31e/0x3e0 [ 4588.212724] [ 4588.212725] [<ffffffff811b2b5d>] SyS_madvise+0x3cd/0x9c0 [ 4588.212726] [ 4588.212727] [<ffffffff816bd721>] ? __do_page_fault+0x171/0x450 [ 4588.212728] [ 4588.212729] [<ffffffff816bdae6>] ? trace_do_page_fault+0x56/0x150 [ 4588.212730] [ 4588.212733] [<ffffffff816c2789>] system_call_fastpath+0x16/0x1b
cpu17在刷新tlb,它需要发送ipi给其他的cpu,简单查看一下,
crash> dis -l ffffffff810fe46a /usr/src/debug/kernel-3.10.0-693.21.1.el7/linux-3.10.0-693.21.1.el7.x86_64/kernel/smp.c: 110 0xffffffff810fe46a <smp_call_function_many+522>: testb $0x1,0x20(%rcx)
110 行对应的代码是:
其实就是在执行 smp_call_function_many 调用的csd_lock_wait函数:
void smp_call_function_many(const struct cpumask *mask, smp_call_func_t func, void *info, bool wait) { struct call_function_data *cfd; int cpu, next_cpu, this_cpu = smp_processor_id(); /* * Can deadlock when called with interrupts disabled. * We allow cpu's that are not yet online though, as no one else can * send smp call function interrupt to this cpu and as such deadlocks * can't happen. */ WARN_ON_ONCE(cpu_online(this_cpu) && irqs_disabled() && !oops_in_progress && !early_boot_irqs_disabled); /* Try to fastpath. So, what's a CPU they want? Ignoring this one. */ cpu = cpumask_first_and(mask, cpu_online_mask); if (cpu == this_cpu) cpu = cpumask_next_and(cpu, mask, cpu_online_mask); /* No online cpus? We're done. */ if (cpu >= nr_cpu_ids) return; /* Do we have another CPU which isn't us? */ next_cpu = cpumask_next_and(cpu, mask, cpu_online_mask); if (next_cpu == this_cpu) next_cpu = cpumask_next_and(next_cpu, mask, cpu_online_mask); /* Fastpath: do that cpu by itself. */ if (next_cpu >= nr_cpu_ids) { smp_call_function_single(cpu, func, info, wait); return; } cfd = &__get_cpu_var(cfd_data); cpumask_and(cfd->cpumask, mask, cpu_online_mask); cpumask_clear_cpu(this_cpu, cfd->cpumask);//将当前cpu排除在外 /* Some callers race with other cpus changing the passed mask */ if (unlikely(!cpumask_weight(cfd->cpumask))) return; for_each_cpu(cpu, cfd->cpumask) { struct call_single_data *csd = per_cpu_ptr(cfd->csd, cpu); csd_lock(csd); csd->func = func; csd->info = info; llist_add(&csd->llist, &per_cpu(call_single_queue, cpu)); } /* Send a message to all CPUs in the map */ arch_send_call_function_ipi_mask(cfd->cpumask); if (wait) { for_each_cpu(cpu, cfd->cpumask) {------------------------------按顺序等各个cpu修改csd的flag,不然我们就死等 struct call_single_data *csd; csd = per_cpu_ptr(cfd->csd, cpu); csd_lock_wait(csd);-------------在执行这个 } } }
根据rcx的值,可以知道当前csd就是 0xffff880b52b9bfa0,我们知道csd是一个percpu变量,发起ipi的一方,通过构造一个csd挂到对方cpu的
/**
* generic_smp_call_function_single_interrupt - Execute SMP IPI callbacks
*
* Invoked by arch to handle an IPI for call function single.
* Must be called with interrupts disabled.
*/
void generic_smp_call_function_single_interrupt(void)
{
flush_smp_call_function_queue(true);
}
17号cpu既然在等待,那么哪些csd没有完成呢?我们知道当前等待的csd是:
crash> struct call_single_data ffff880b52b9bfa0 struct call_single_data { { llist = { next = 0x0 }, __UNIQUE_ID_rh_kabi_hide1 = { list = { next = 0x0, prev = 0x0 } }, {<No data fields>} }, func = 0xffffffff810706a0 <flush_tlb_func>, info = 0xffff880aa7fdbcf8, flags = 1 } crash> struct flush_tlb_info 0xffff880aa7fdbcf8 struct flush_tlb_info { flush_mm = 0xffff88168b3c5dc0, flush_start = 0, flush_end = 18446744073709551615 }
根据cfd和csd的运算关系,由如下几行代码:
cfd = &__get_cpu_var(cfd_data);
。。。。。 struct call_single_data *csd = per_cpu_ptr(cfd->csd, cpu);
可以确定17号等待的csd是6号cpu的。kmem -o的打印是显示的各个cpu的偏移。
crash> kmem -o PER-CPU OFFSET VALUES: CPU 0: ffff880b52a00000 CPU 1: ffff880b52a40000 CPU 2: ffff880b52a80000 CPU 3: ffff880b52ac0000 CPU 4: ffff880b52b00000 CPU 5: ffff880b52b40000 CPU 6: ffff880b52b80000 CPU 7: ffff880b52bc0000 CPU 8: ffff880b52c00000 CPU 9: ffff880b52c40000 CPU 10: ffff880b52c80000 CPU 11: ffff880b52cc0000 CPU 12: ffff881692200000 CPU 13: ffff881692240000 CPU 14: ffff881692280000 CPU 15: ffff8816922c0000 CPU 16: ffff881692300000 CPU 17: ffff881692340000 CPU 18: ffff881692380000 CPU 19: ffff8816923c0000 CPU 20: ffff881692400000 CPU 21: ffff881692440000 CPU 22: ffff881692480000 CPU 23: ffff8816924c0000
crash> px cfd_data:17
per_cpu(cfd_data, 17) = $43 = {
csd = 0x1bfa0,
cpumask = 0xffff880beeb51c00
}
crash> px 0xffff880b52b9bfa0-0x1bfa0
$44 = 0xffff880b52b80000-------------------6号cpu的偏移
crash> p cfd_data
PER-CPU DATA TYPE:
struct call_function_data cfd_data;
PER-CPU ADDRESSES:
[0]: ffff880b52a18780
[1]: ffff880b52a58780
[2]: ffff880b52a98780
[3]: ffff880b52ad8780
[4]: ffff880b52b18780
[5]: ffff880b52b58780
[6]: ffff880b52b98780
[7]: ffff880b52bd8780
[8]: ffff880b52c18780
[9]: ffff880b52c58780
[10]: ffff880b52c98780
[11]: ffff880b52cd8780
[12]: ffff881692218780
[13]: ffff881692258780
[14]: ffff881692298780
[15]: ffff8816922d8780
[16]: ffff881692318780
[17]: ffff881692358780
[18]: ffff881692398780
[19]: ffff8816923d8780
[20]: ffff881692418780
[21]: ffff881692458780
[22]: ffff881692498780
[23]: ffff8816924d8780
那6号cpu在干啥呢?
crash> set -c 6 PID: 24032 COMMAND: "zte_uep1" TASK: ffff880a207ccf10 [THREAD_INFO: ffff880a7766c000] CPU: 6 STATE: TASK_RUNNING (ACTIVE) crash> bt PID: 24032 TASK: ffff880a207ccf10 CPU: 6 COMMAND: "zte_uep1" [exception RIP: native_queued_spin_lock_slowpath+29] RIP: ffffffff810fed1d RSP: ffff880a7766f798 RFLAGS: 00000093 RAX: 0000000000000001 RBX: 0000000000000286 RCX: 0000000000000001 RDX: 0000000000000001 RSI: 0000000000000001 RDI: ffffffff81e991c0 RBP: ffff880a7766f798 R8: 0000000000000001 R9: 000000000000000c R10: 0000000000000000 R11: 0000000000000003 R12: ffffffff81e991c0 R13: ffff88168d655368 R14: ffff880a7766f800 R15: 0000000000000003 CS: 0010 SS: 0018 #0 [ffff880a7766f7a0] queued_spin_lock_slowpath at ffffffff816abe64 #1 [ffff880a7766f7b0] _raw_spin_lock_irqsave at ffffffff816b92d7 #2 [ffff880a7766f7c8] lock_timer_base at ffffffff8109b4ab #3 [ffff880a7766f7f8] mod_timer_pending at ffffffff8109c3c3 #4 [ffff880a7766f840] __nf_ct_refresh_acct at ffffffffc04be990 [nf_conntrack] #5 [ffff880a7766f870] tcp_packet at ffffffffc04c7523 [nf_conntrack] #6 [ffff880a7766f928] nf_conntrack_in at ffffffffc04c112a [nf_conntrack] #7 [ffff880a7766f9d0] ipv4_conntrack_local at ffffffffc044366f [nf_conntrack_ipv4] #8 [ffff880a7766f9e0] nf_iterate at ffffffff815cb818 #9 [ffff880a7766fa20] nf_hook_slow at ffffffff815cb908 #10 [ffff880a7766fa58] __ip_local_out_sk at ffffffff815d9a16 #11 [ffff880a7766faa8] ip_local_out_sk at ffffffff815d9a3b #12 [ffff880a7766fac8] ip_queue_xmit at ffffffff815d9dc3 #13 [ffff880a7766fb00] tcp_transmit_skb at ffffffff815f40cc #14 [ffff880a7766fb70] tcp_write_xmit at ffffffff815f484c #15 [ffff880a7766fbd8] __tcp_push_pending_frames at ffffffff815f552e #16 [ffff880a7766fbf0] tcp_push at ffffffff815e347c #17 [ffff880a7766fc00] tcp_sendmsg at ffffffff815e6e40 #18 [ffff880a7766fcc8] inet_sendmsg at ffffffff816133a9 #19 [ffff880a7766fcf8] sock_sendmsg at ffffffff815753a6 #20 [ffff880a7766fe58] SYSC_sendto at ffffffff81575911 #21 [ffff880a7766ff70] sys_sendto at ffffffff8157639e #22 [ffff880a7766ff80] system_call_fastpath at ffffffff816c2789 RIP: 00007fbe5777572b RSP: 00007fbe217d4158 RFLAGS: 00000246 RAX: 000000000000002c RBX: ffffffff816c2789 RCX: 0000000000000231 RDX: 0000000000000001 RSI: 00007fbe217c4090 RDI: 00000000000000af RBP: 0000000000000000 R8: 0000000000000000 R9: 0000000000000000 R10: 0000000000000000 R11: 0000000000000246 R12: ffffffff8157639e R13: ffff880a7766ff78 R14: 00007fbe217c4010 R15: 0000000000000001 ORIG_RAX: 000000000000002c CS: 0033 SS: 002b
RFLAGS(64位)将EFLAGS(32位)扩展到64位,新扩展的高32位全部保留未用。
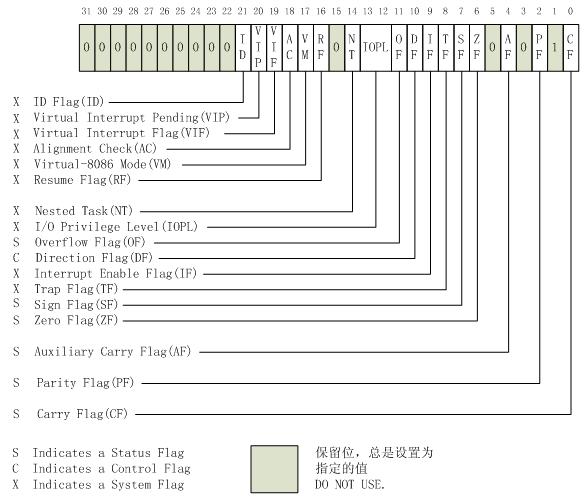
RFLAGS为0x93,换算成2进制,第9位IF就是0,
IF(bit 9) [Interrupt enable flag] 该标志用于控制处理器对可屏蔽中断请求(maskable interrupt requests)的响应。置1以响应可屏蔽中断,反之则禁止可屏蔽中断。就是关中断了,这个和堆栈是对得上的,堆栈明显在_raw_spin_lock_irqsave 等锁:
可以看出_spin_lock_irq的参数通过rdi传递(x86_64架构的传参规则,从左到右依次rdi、rsi...),而rdi在后续的函数中没有再使用,所以最终上下文中的rdi即为参数的值:ffffffff81e991c0(bt中有RDI寄存器的值) ,为了进一步验证,我们来看下6号cpu积压的ipi:
crash> p call_single_queue:6 per_cpu(call_single_queue, 6) = $45 = { first = 0xffff880b52b9bd70 } crash> list 0xffff880b52b9bd70 ffff880b52b9bd70 ffff880b52b9bfa0 crash> struct call_single_data ffff880b52b9bd70------------------------3号cpu发来的ipi请求, struct call_single_data { { llist = { next = 0xffff880b52b9bfa0 }, __UNIQUE_ID_rh_kabi_hide1 = { list = { next = 0xffff880b52b9bfa0, prev = 0x0 } }, {<No data fields>} }, func = 0xffffffff810706a0 <flush_tlb_func>, info = 0xffff8814f160fb58, flags = 1 } crash> struct call_single_data ffff880b52b9bfa0 struct call_single_data { { llist = { next = 0x0 }, __UNIQUE_ID_rh_kabi_hide1 = { list = { next = 0x0, prev = 0x0 } }, {<No data fields>} }, func = 0xffffffff810706a0 <flush_tlb_func>, info = 0xffff880aa7fdbcf8,--------------------------6号cpu发送来的ipi请求 flags = 1 }
从积压的情况来看,有两个ipi没有处理,17号cpu发过来的ipi请求还排在后面,说明从时间上说,6号cpu关中断来获取锁的时候,17号cpu的ipi请求还没到。实际上6号cpu积压了一个3号cpu发来的ipi,以及17号cpu发来的ipi。
crash> bt PID: 8854 TASK: ffff8809e7f2cf10 CPU: 3 COMMAND: "zte_uep1" [exception RIP: smp_call_function_many+522] RIP: ffffffff810fe46a RSP: ffff8814f160fb10 RFLAGS: 00000202 RAX: 0000000000000006 RBX: 0000000000000018 RCX: ffff880b52b9bd70--------------------在等6号cpu RDX: 0000000000000006 RSI: 0000000000000018 RDI: 0000000000000000 RBP: ffff8814f160fb48 R8: ffff88016e791000 R9: ffffffff8132a699 R10: ffff880b52adabc0 R11: ffffea002548e000 R12: 0000000000018740 R13: ffffffff810706a0 R14: ffff8814f160fb58 R15: ffff880b52ad8780 CS: 0010 SS: 0000 #0 [ffff8814f160fb50] native_flush_tlb_others at ffffffff81070868 #1 [ffff8814f160fba0] flush_tlb_page at ffffffff81070a64 #2 [ffff8814f160fbc0] ptep_clear_flush at ffffffff811c8984 #3 [ffff8814f160fbf8] try_to_unmap_one at ffffffff811c2bb2 #4 [ffff8814f160fc60] try_to_unmap_anon at ffffffff811c460d #5 [ffff8814f160fca8] try_to_unmap at ffffffff811c46cd #6 [ffff8814f160fcc0] migrate_pages at ffffffff811ed44f #7 [ffff8814f160fd68] migrate_misplaced_page at ffffffff811ee11c #8 [ffff8814f160fdb0] do_numa_page at ffffffff811b6f68 #9 [ffff8814f160fe00] handle_mm_fault at ffffffff811b8377 #10 [ffff8814f160fe98] __do_page_fault at ffffffff816bd704 #11 [ffff8814f160fef8] trace_do_page_fault at ffffffff816bdae6 #12 [ffff8814f160ff38] do_async_page_fault at ffffffff816bd17a #13 [ffff8814f160ff50] async_page_fault at ffffffff816b9c38 RIP: 00007fbe56dc98d3 RSP: 00007fbb3eceb790 RFLAGS: 00010202 RAX: 00000000e2c27930 RBX: 0000000000001f42 RCX: 00000000e2c30000 RDX: 0000000000000e67 RSI: 00000000e2c27930 RDI: 00007fbe5701b790 RBP: 00007fbb3eceb7c0 R8: 00007fbe50021b18 R9: 0000000000001f40 R10: 0000000000000e67 R11: 0000000000000008 R12: 0000000000000000 R13: 00007fbbb4040938 R14: 000000000000fa00 R15: 00007fbbb4045800 ORIG_RAX: ffffffffffffffff CS: 0033 SS: 002b
3号cpu,17号cpu都在等6号cpu,
crash> p call_single_queue:3 per_cpu(call_single_queue, 3) = $47 = { first = 0x0 } crash> p call_single_queue:17 per_cpu(call_single_queue, 17) = $48 = { first = 0x0 }
3号核17号都没有积压的ipi处理,且都没有关中断,说明他俩是受害者。3号有没有阻塞别人呢,查看3号的堆栈,它拿了一把 ffffea002676cc30 的自旋锁,阻塞了如下的进程:
crash> search -t ffffea002676cc30 PID: 2681 TASK: ffff880afa3b5ee0 CPU: 10 COMMAND: "zte_uep1" ffff8809acf8fd48: ffffea002676cc30 PID: 4208 TASK: ffff8809a6b61fa0 CPU: 4 COMMAND: "zte_uep1" ffff88095b2f7d48: ffffea002676cc30 PID: 4209 TASK: ffff8809a4ad3f40 CPU: 1 COMMAND: "zte_uep1" ffff8809a6bf3d48: ffffea002676cc30 PID: 4212 TASK: ffff8809a4ad2f70 CPU: 13 COMMAND: "zte_uep1" ffff880985b53d48: ffffea002676cc30 PID: 4949 TASK: ffff8815dd2c8000 CPU: 16 COMMAND: "zte_uep1" ffff88009865bd48: ffffea002676cc30 PID: 8854 TASK: ffff8809e7f2cf10 CPU: 3 COMMAND: "zte_uep1"-------------------3号拿了 fffea002676cc30的锁 ffff8814f160fc20: ffffea002676cc30 ffff8814f160fda0: ffffea002676cc30 PID: 23686 TASK: ffff8815cbfcaf70 CPU: 18 COMMAND: "zte_uep1" ffff8815a9f0bd48: ffffea002676cc30 PID: 23979 TASK: ffff880a6e3c8fd0 CPU: 22 COMMAND: "zte_uep1" ffff880a11ef3d48: ffffea002676cc30 PID: 29249 TASK: ffff8809e0376eb0 CPU: 2 COMMAND: "zte_uep1" ffff8809ac6fbd48: ffffea002676cc30 PID: 29501 TASK: ffff8809cbe02f70 CPU: 9 COMMAND: "zte_uep1" ffff8809a4a37d48: ffffea002676cc30
10号,4号,1号,13号,16号,18号,22号,2号,9号全部被cpu 3号阻塞,3号,17号被6号阻塞,
再分析其他cpu的等待关系:
如下,说明7在等0,而0在idle,说明7等0是一个瞬间状态,因为smp_call_function_many正要处理
crash> bt -c 7
PID: 3714 TASK: ffff881689e24f10 CPU: 7 COMMAND: "modprobe"
[exception RIP: smp_call_function_many+522]
RIP: ffffffff810fe46a RSP: ffff880675e1fd70 RFLAGS: 00000202
RAX: 0000000000000000 RBX: 0000000000000018 RCX: ffff880b52a1be10----------------等待的csd
RDX: 0000000000000000 RSI: 0000000000000018 RDI: 0000000000000000
RBP: ffff880675e1fda8 R8: ffff88016e792000 R9: ffffffff8132a699
R10: ffff880b52bdabc0 R11: ffffea002643f800 R12: 0000000000018740
R13: ffffffff8106a8c0 R14: 0000000000000000 R15: ffff880b52bd8780
CS: 0010 SS: 0018
#0 [ffff880675e1fdb0] on_each_cpu at ffffffff810fe52d
#1 [ffff880675e1fdd8] change_page_attr_set_clr at ffffffff8106c566
#2 [ffff880675e1fe88] set_memory_x at ffffffff8106c7d3
#3 [ffff880675e1fea8] unset_module_core_ro_nx at ffffffff8110096b
#4 [ffff880675e1fec0] free_module at ffffffff81102e7e
#5 [ffff880675e1fef8] sys_delete_module at ffffffff811030c7
#6 [ffff880675e1ff80] system_call_fastpath at ffffffff816c2789
RIP: 00007f3f44afa857 RSP: 00007ffc32e48b38 RFLAGS: 00000246
RAX: 00000000000000b0 RBX: ffffffff816c2789 RCX: ffffffffffffffff
RDX: 0000000000000000 RSI: 0000000000000800 RDI: 00000000021d99d8
RBP: 0000000000000000 R8: 00007f3f44dbf060 R9: 00007f3f44b6bae0
R10: 0000000000000000 R11: 0000000000000206 R12: 0000000000000000
R13: 00000000021d7380 R14: 00000000021d9970 R15: 000000000ba846a1
ORIG_RAX: 00000000000000b0 CS: 0033 SS: 002b
crash> p call_single_queue:0
per_cpu(call_single_queue, 0) = $79 = {
first = 0xffff880b52a1be10-------------0号cpu还未处理的csd
}
crash> list 0xffff880b52a1be10
ffff880b52a1be10
7号在等0号,0号是idle态进入irq处理,说明是瞬间情况。cpu 5,cpu6,cpu8,cpu11,cpu12,cpu14 ,cpu23都在等待 ffffffff81e991c0 这把锁。
19在等8,
crash> p call_single_queue:8 per_cpu(call_single_queue, 8) = $84 = { first = 0xffff8815ac3abc00 } crash> list 0xffff8815ac3abc00 ffff8815ac3abc00 crash> call_single_data 0xffff8815ac3abc00 struct call_single_data { { llist = { next = 0x0 }, __UNIQUE_ID_rh_kabi_hide3 = { list = { next = 0x0, prev = 0x0 } }, {<No data fields>} }, func = 0xffffffff810706a0 <flush_tlb_func>, info = 0xffff8815ac3abcd8, flags = 3 }
cpu20在等11:
crash> bt -c 20 PID: 30726 TASK: ffff8809f1e20000 CPU: 20 COMMAND: "java" [exception RIP: generic_exec_single+250] RIP: ffffffff810fddca RSP: ffff8809b4e9fc00 RFLAGS: 00000202 RAX: 0000000000000018 RBX: ffff8809b4e9fc00 RCX: 0000000000000028 RDX: 0000000000ffffff RSI: 0000000000000018 RDI: 0000000000000286 RBP: ffff8809b4e9fc50 R8: ffffffff816de2e0 R9: 0000000000000001 R10: 0000000000000001 R11: 0000000000000202 R12: 000000000000000b-------------等待的cpu号 R13: 0000000000000001 R14: ffff8809b4e9fcd8 R15: 000000000000000b CS: 0010 SS: 0018 #0 [ffff8809b4e9fc58] smp_call_function_single at ffffffff810fdedf #1 [ffff8809b4e9fc88] smp_call_function_many at ffffffff810fe48b #2 [ffff8809b4e9fcd0] native_flush_tlb_others at ffffffff81070868 #3 [ffff8809b4e9fd20] flush_tlb_mm_range at ffffffff81070938 #4 [ffff8809b4e9fd50] change_protection_range at ffffffff811c0228 #5 [ffff8809b4e9fe50] change_protection at ffffffff811c0385 #6 [ffff8809b4e9fe88] change_prot_numa at ffffffff811d8e8b #7 [ffff8809b4e9fe98] task_numa_work at ffffffff810cd1a2 #8 [ffff8809b4e9fef0] task_work_run at ffffffff810b0abb #9 [ffff8809b4e9ff30] do_notify_resume at ffffffff8102ab62 #10 [ffff8809b4e9ff50] int_signal at ffffffff816c2a3d RIP: 00007f9c761c5a82 RSP: 00007f9c4fae3450 RFLAGS: 00000202 RAX: ffffffffffffff92 RBX: 0000000003810f00 RCX: ffffffffffffffff RDX: 0000000000000001 RSI: 0000000000000089 RDI: 0000000003810f54 RBP: 00007f9c4fae3500 R8: 0000000003810f28 R9: 00000000ffffffff R10: 00007f9c4fae34c0 R11: 0000000000000202 R12: 0000000000000001 R13: 00007f9c4fae34c0 R14: ffffffffffffff92 R15: 00000000293f1200 ORIG_RAX: 00000000000000ca CS: 0033 SS: 002b crash> dis -l generic_exec_single+250 /usr/src/debug/kernel-3.10.0-693.21.1.el7/linux-3.10.0-693.21.1.el7.x86_64/kernel/smp.c: 110 0xffffffff810fddca <generic_exec_single+250>: testb $0x1,0x20(%rbx) crash> p call_single_queue:11 per_cpu(call_single_queue, 11) = $85 = { first = 0xffff8809b4e9fc00 }
同理可以分析,21cpu在等12cpu,
15号cpu啥都不等:
crash> bt -c 15
PID: 0 TASK: ffff880beeacbf40 CPU: 15 COMMAND: "swapper/15"
[exception RIP: lock_timer_base+26]
RIP: ffffffff8109b49a RSP: ffff8816922c3a10 RFLAGS: 00000246
RAX: 0000000000000000 RBX: 0000000000000000 RCX: 0000000000000000
RDX: ffff88098fee0100 RSI: ffff8816922c3a40 RDI: ffff8815d6b661e8
RBP: ffff8816922c3a30 R8: 0000000000000001 R9: 000000000000000c
R10: 0000000000000001 R11: 0000000000000003 R12: 0000000000000000
R13: ffff8815d6b661e8 R14: ffff8816922c3a40 R15: 0000000000000003
CS: 0010 SS: 0018
综合来看,需要分析那个等timer的锁,
那cpu 5,cpu6,cpu8,cpu11,cpu12,cpu14 ,cpu23号等待的锁 ffffffff81e991c0 到底被谁拿了呢?
crash> bt -c 5
PID: 28932 TASK: ffff8809ce2d1fa0 CPU: 5 COMMAND: "java"
[exception RIP: native_queued_spin_lock_slowpath+29]
RIP: ffffffff810fed1d RSP: ffff8800b975b758 RFLAGS: 00000093
RAX: 0000000000000001 RBX: 0000000000000286 RCX: 0000000000000001
RDX: 0000000000000001 RSI: 0000000000000001 RDI: ffffffff81e991c0------------和cpu6等的锁是同一把
RBP: ffff8800b975b758 R8: 0000000000000001 R9: 000000000000000c
R10: 0000000000000000 R11: 0000000000000003 R12: ffffffff81e991c0
R13: ffff880b30e85ea8 R14: ffff8800b975b7c0 R15: 0000000000000003
CS: 0010 SS: 0018
#0 [ffff8800b975b760] queued_spin_lock_slowpath at ffffffff816abe64
#1 [ffff8800b975b770] _raw_spin_lock_irqsave at ffffffff816b92d7
#2 [ffff8800b975b788] lock_timer_base at ffffffff8109b4ab
#3 [ffff8800b975b7b8] mod_timer_pending at ffffffff8109c3c3
crash> kmem ffffffff81e991c0 ffffffff81e991c0 (B) boot_tvec_bases PAGE PHYSICAL MAPPING INDEX CNT FLAGS ffffea000007a640 1e99000 0 0 1 1fffff00000400 reserved crash> p boot_tvec_bases boot_tvec_bases = $8 = { lock = { { rlock = { raw_lock = { val = { counter = 1----------------------被人拿了 } } } } }, running_timer = 0x0, timer_jiffies = 4298413481, next_timer = 4298413480, active_timers = 108,
没有开启debug,没法直接获取到owner,各个active进程的堆栈也都搜过,没有搜到这个锁的占用。
这个其实就是tvec_bases 的第0号cpu的锁,为啥这么多cpu等0号cpu变量的锁呢?
通过堆栈可以知道,这些 等待锁的堆栈都是在做一件事情,那就是

