数据库三大范式&mysql的索引类型和作用&事务的特性和隔离级别
数据库三大范式&mysql的索引类型和作用&事务的特性和隔离级别
数据库三大范式
第一范式
# 数据库表的每一列都是不可分割的基本数据
-每列的值具有原子性,不可再分割
-每个字段的值都只能是单一值
举例:学籍信息不符合第一范式,可以继续分割

第二范式
# 在第一范式的基础上
- 如果表是单主键,那么主键以外的列必须完全依赖于主键,其他列需要跟主键有关系
- 如果表是符合主键,那么主键以外的列必须完全依赖于主键,不仅仅是依赖主键的一部分
举例:
1.上表中如果加上学校地址那么不符合规范,和主键没有关系,此时可以加上学校名,然后另建学校表,做外键关联,外键就是规范数据库的产物。
2.下表中分数字段完全依赖于学生id和课程id,但是课程名字只依赖于主键的一部分课程id,不符合规范
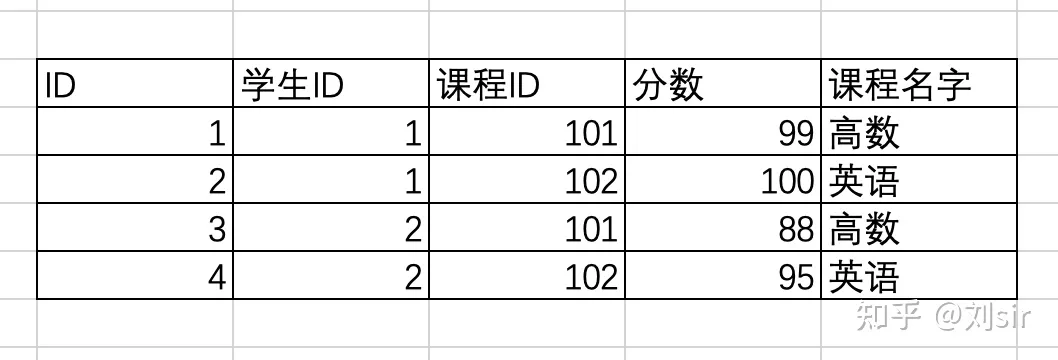
第三范式
# 在第二范式的基础上
- 表中的非主键列必须和主键直接相关而不能简介相关,即非主键列之间不能相互依赖,不存在依赖传递
举例:
下表中部门名称依赖于部门id,部门id依赖于id主键,部门名称不直接依赖于id主键,属于依赖传递,不符合规范
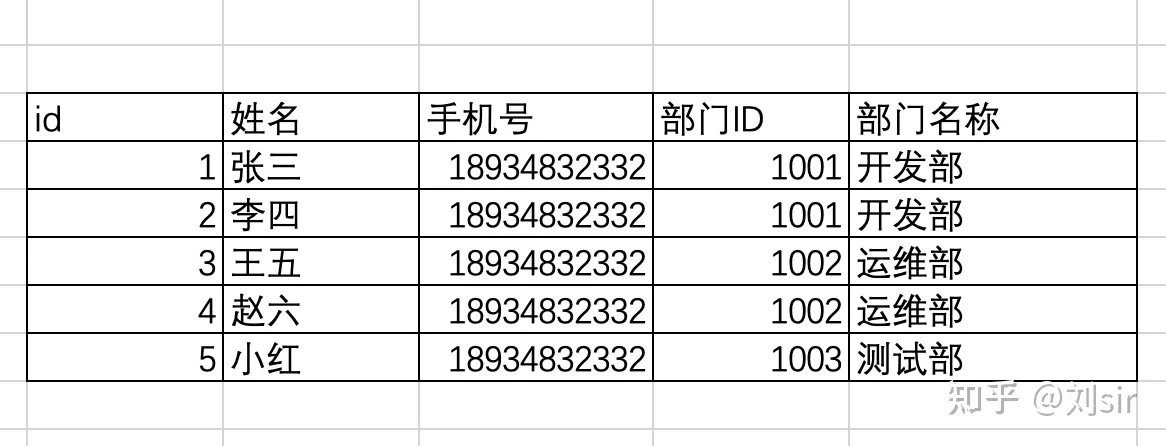
mysql的索引类型和作用
主键索引(聚簇索引)
-表不建立主键,也会有个隐藏字段是主键,是主键索引。主键索引是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。简单来说:主键索引是加速查询 + 列值唯一(不可以有null)+ 表中只有一个
辅助索引(普通索引)
咱们给某个字段自己加索引,django index=True,通过该字段查询,会提高速度,如果字段 变化小(性别,年龄),不要建立普通索引
# CREATE INDEX index_id ON tb_student(id);
唯一索引(unique)
-不是为了提高访问速度,而是为了避免数据出现重复
-唯一索引通常使用 UNIQUE 关键字,允许有null
# CREATE UNIQUE INDEX index_id ON tb_student(id);
联合索引(组合索引)
- 组合索引指在多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用组合索引时遵循最左前缀集合。
- 联合索引的目的是提高数据库查询的性能。它可以加快包含索引的列组合的查询速度,并提高相关查询的效率。
-django 中:
class Meta:
indexes = [
models.Index(fields=['field1', 'field2']),
models.Index(fields=['field2', 'field3']),
]
# CREATE INDEX index_name ON table_name (column1, column2, column3);
全文索引
- 全文索引主要用来查找文本中的关键字,只能在 CHAR、VARCHAR 或 TEXT 类型的列上创建。
- 在 MySQL 中只有 MyISAM 存储引擎支持全文索引。
- 全文索引允许在索引列中插入重复值和空值。
- 不过对于大容量的数据表,生成全文索引非常消耗时间和硬盘空间。
- 创建全文索引使用 FULLTEXT 关键字
事务的特性和隔离级别
四大特性ACID
1.原子性(Atomicity):原子性确保事务中的所有操作要么全部成功完成,要么全部回滚到事务开始前的状态。如果事务中的任何操作失败,那么整个事务将回滚,以保持数据的一致性。原子性确保了事务的完整性和一致性。
2.一致性(Consistency):一致性确保事务在执行前后,数据库始终保持一致的状态。
3.隔离性(Isolation):隔离性确保并发执行的事务相互隔离,每个事务都像是在独立运行。通过隔离级别(如读未提交、读已提交、可重复读和串行化),数据库提供了对并发事务之间可见性的控制。
4.持久性(Durable):事务完成之后,她对数据的修改是永恒的,即时出现故障也能够正常保持
隔离级别
# Read uncommitted(读未提交)-ru
- 一个事物读到了另一个事务未提交的数据
# Read committed(读已提交)-rc
-如果设置了这个级别一个事物读不到另一个事务未提交的数据
-写事务提交之前不允许其他事务的读操作
# Repeatable read(可重复读取)-rr
-在开始读取数据(事务开启)时,不再允许修改操作,这样就可以在同一个事务内两次读到的数据是一样的,因此称为是可重复读隔离级别
# Serializable(串行化)
事务串行执行,只能一个接着一个地执行,完全隔离了并发访问。它提供了最高的数据完整性,但并发性能最差

 浙公网安备 33010602011771号
浙公网安备 33010602011771号