nlp文本转化方式小结
一、独热编码(one-hot)
在自然语言处理中,若有个字典或字库里有 $N$ 个单字,则每个单字可以被一个 $N$ 维的one-hot向量代表。如字库里仅有apple,banana ,以及pineapple这三个单词,则他们各自的one-hot向量可以为:
$\begin{array}{ll}\text { apple } & =\left[\begin{array}{lll}1 & 0 & 0\end{array}\right] \\ \text { banana } & =\left[\begin{array}{lll}0 & 1 & 0\end{array}\right] \\ \text { pineapple } & =\left[\begin{array}{lll}0 & 0 & 1\end{array}\right]\end{array}$
由于电脑无法理解非数字类的数据,one-hot编码可以将类别性数据转换成统一的数字格式,方便机器学习的算法进行处理及计算。而转换成固定维度的向量则方便机器学习算法进行线性代数上的计算。
二、词袋模型(Bag of Words)
词袋模型 (英语: Bag-of-words model) 是个在自然语言处理和信息检索(IR)下被简化的表达模型。此模型下,一段文本 (比如一个句子或是一个文档) 可以用一个装着这些词的袋子来表示, 这种表示方式不考虑文法以及词的顺序。
示例:下面是两个简单的文件
(1) John likes to watch movies. Mary likes movies too.(2) John also likes to watch football games.
基于以上两个文件,可以构建出下列清单(词集):
[ "John", "likes", "to", "watch", "movies", "also", "football", "games", "Mary", "too" ]
此处有是个不同的词,使用清单(词集)的索引表示长度为10的向量:
(1) [1, 2, 1, 1, 2, 0, 0, 0, 1, 1] (2) [1, 1, 1, 1, 0, 1, 1, 1, 0, 0]
每个向量的索引内容对应到清单中词出现的次数。
举例来说,第一个向量(文件一)前两个内容索引是1和2,第一个索引内容是"John"对应到清单第一个词并且该值设定为1,因为"John"出现一次。
此向量表示法不会保存原始句子中词的顺序。该表示法有许多成功的应用,像是邮件过滤。
基于维基百科的解释和sklearn中对于词袋模型的实现(CountVectorizer)可以得出:在实际过程中,词袋模型多以词集+词频矩阵的方式实现。
值得一提的是,得到了两篇文章的词频矩阵,可以根据余弦相似度来比较两篇文章的相似度,余弦相似度公式如下:
$\frac{\mathrm{a} \cdot \mathrm{b}}{|| \mathrm{a}|| \times|| \mathrm{b}||}$
在示例中的计算结果为:
$\frac{1*1+2*1+1*1+1*1+2*0+0*1+0*1+0*1+1*0+1*0}{\sqrt{1^{2}+2^{2}+1^{2}+1^{2}+2^{2}+0^{2}+0^{2}+0^{2}+1^{2}+1^{2}}+\sqrt{1^{2}+1^{2}+1^{2}+1^{2}+0^{2}+1^{2}+1^{2}+1^{2}+0^{2}+0^{2}}}\approx 0.8$
三、TF-IDF
四、n-gram模型
参考链接七至十分别是维基百科的 条件概率、贝叶斯定理、似然函数和最大似然估计 数学概念解释。
如果我们有一个由 $m$ 个词组成的序列 (或者说一个句子),我们希望算得概率 $p\left(w_{1}, w_{2}, \ldots, w_{m}\right)$ ,根据琏式规则,可得
$p\left(w_{1}, w_{2}, \ldots, w_{m}\right)=p\left(w_{1}\right) * p\left(w_{2} \mid w_{1}\right) * p\left(w_{3} \mid w_{1}, w_{2}\right) \ldots p\left(w_{m} \mid w_{1}, \ldots, w_{m-1}\right)$
这个概率显然并不好算,不妨利用马尔科夫链的假设,即当前这个词仅仅跟前面几个有限的词相 关,因此也就不必追溯到最开始的那个词, 这样便可以大幅缩减上述算式的长度。即
$$
p\left(w_{1}, w_{2}, \ldots, w_{m}\right)=p\left(w_{i} \mid w_{i-n+1, \ldots, w_{i-1}}\right)
$$
这个马尔科夫链的假设为什么好用? 我想可能是在现实情况中,大家通过真实情况将 $n=1,2$, 3 , ....这些值都试过之后,得到的真实的效果和时间空间的开销权衡之后,发现能够使用。
下面给出一元模型,二元模型,三元模型的定义:
当 $\mathrm{n}=1$, 一个一元模型 (unigram model)即为:
$$
P\left(w_{1}, w_{2}, \cdots, w_{m}\right)=\prod_{i=1}^{m} P\left(w_{i}\right)
$$
当 $\mathrm{n}=2$, 一个二元模型 (bigram model)即为 :
$$
P\left(w_{1}, w_{2}, \cdots, w_{m}\right)=\prod_{i=1}^{m} P\left(w_{i} \mid w_{i-1}\right)
$$
当 $\mathrm{n}=3$, 一个三元模型 (trigram model)即为
$$
P\left(w_{1}, w_{2}, \cdots, w_{m}\right)=\prod_{i=1}^{m} P\left(w_{i} \mid w_{i-2} w_{i-1}\right)
$$
对于bigram model而言,
$$
P\left(w_{i} \mid w_{i-1}\right)=\frac{C\left(w_{i-1} w_{i}\right)}{C\left(w_{i-1}\right)}
$$
对于 $n$-gram model而言,
$$
P\left(w_{i} \mid w_{i-n-1}, \cdots, w_{i-1}\right)=\frac{C\left(w_{i-n-1}, \cdots, w_{i}\right)}{C\left(w_{i-n-1}, \cdots, w_{i-1}\right)}
$$
举例参考链接十一。
n-gram有许多平滑方法,在这里不记录。
实数在计算机内用二进制表示,所以不是一个精确值,当数值过小的时候,被四舍五入为0,这就是下溢出。此时如果对这个数再做某些运算(例如除以它)就会出问题。反之,当数值过大的时候,被视为(正负)无穷,情况就变成了上溢出;有时候防止下溢出就会使用log求解,也可以简化运算。
五、共现矩阵、PPMI(正点互信息)与SVD(奇异值分解)
假设有一句话'you say goodbye and i say hello.',现在要创建它的共现矩阵。首先可以创建一个词集{0: 'you', 1: 'say', 2: 'goodbye', 3: 'and', 4: 'i', 5: 'hello', 6:'.'},词汇总数为7个,以单词say为例,它相邻的单词有四个(you,goodbye,i,hello),将这四个分别标记为相邻出现的次数,也就是1,其他标记为0,可以得到一行类似表格的数据如下所示。

同理推出整句话的共现矩阵
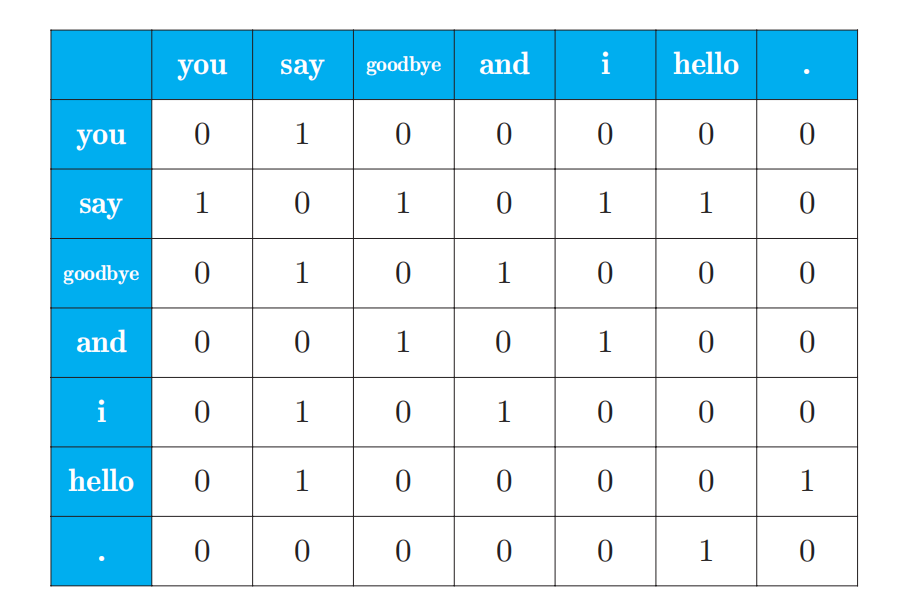
共现矩阵的元素表示两个单词同时出现的次数。但是, 这种 “原始” 的次数并不具备好的性质。如果我们看一下高频词汇(出现次数很多的单词 ),就能明白其原因了。
比如,我们来考虑某个语料库中 the 和 car 共现的情况。在这种情况下, 我们会看到很多 “...the car...” 这样的短语。因此, 它们的共现次数将会很 大。另外, car 和 drive 也明显有很强的相关性。但是, 如果只看单词的出 现次数, 那么与 drive 相比, the 和 car 的相关性更强。这意味着, 仅仅因 为 the 是个常用词, 它就被认为与 car 有很强的相关性。
为了解决这一问题, 可以使用点互信息(Pointwise Mutual Information, PMI )这一指标。对于随机变量 $x$ 和 $y$, 它们的 PMI 定义如下:
$$
\operatorname{PMI}(x, y)=\log _{2} \frac{P(x, y)}{P(x) P(y)}
$$
现在, 我们使用共现矩阵 (其元素表示单词共现的次数 ) 来重写上式。 这里, 将共现矩阵表示为 $C$, 将单词 $x$ 和 $y$ 的共现次数表示为 $C(x, y)$, 将 单词 $x$ 和 $y$ 的出现次数分别表示为 $C(x), C(y)$, 将语料库的单词数量记为 $N$, 则上式可以重写为:
$$
\operatorname{PMI}(x, y)=\log _{2} \frac{P(x, y)}{P(x) P(y)}=\log _{2} \frac{\frac{C(x, y)}{N}}{\frac{\boldsymbol{C}(x)}{N} \frac{\boldsymbol{C}(y)}{N}}=\log _{2} \frac{\boldsymbol{C}(x, y) \cdot N}{\boldsymbol{C}(x) \boldsymbol{C}(y)}
$$
这里假设语料库的单词数量 $(N)$ 为 10000 , the 出现 100 次, car 出现 20 次, drive 出现 10 次, the 和 car 共现 10 次, car 和 drive 共现 5 次。这时, 如 果从共现次数的角度来看, 则与 drive 相比, the 和 car 的相关性更强。而如果从 PMI 的角度来看, 结果:
$$
\begin{aligned}
&\text { PMI("the", "car" })=\log _{2} \frac{10 \cdot 10000}{1000 \cdot 20} \approx 2.32 \\
&\text { PMI("car", "drive" })=\log _{2} \frac{5 \cdot 10000}{20 \cdot 10} \approx 7.97
\end{aligned}
$$
结果表明, 在使用 PMI 的情况下, 与 the 相比, drive 和 car 具有更强 的相关性。这是我们想要的结果。之所以出现这个结果,是因为我们考虑了 单词单独出现的次数。在这个例子中, 因为 the 本身出现得多, 所以 PMI 的得分被拉低了。
虽然我们已经获得了$PMI$这样一个好的指标,但是$PMI$也有一个问题。那就是当两个单词的共现次数为 0 时, $\log _{2} 0=-\infty$ 。为了解决这个问题, 实践上我们会使用下述正的点互信息(Positive PMI,PPMI )。
$$
\operatorname{PPMI}(x, y)=\max (0, \operatorname{PMI}(x, y))
$$
SVD直接参考参考连接最后一条
六、Word2Vec模型
参考:
https://blog.csdn.net/ziuno/article/details/104727185
https://spaces.ac.cn/archives/4122
https://zh.wikipedia.org/wiki/One-hot
https://zh.wikipedia.org/wiki/%E8%AF%8D%E8%A2%8B%E6%A8%A1%E5%9E%8B
https://zh.wikipedia.org/wiki/N%E5%85%83%E8%AF%AD%E6%B3%95
https://blog.csdn.net/u014539465/article/details/105353638
https://zh.wikipedia.org/wiki/%E6%9D%A1%E4%BB%B6%E6%A6%82%E7%8E%87
https://zh.wikipedia.org/wiki/%E8%B4%9D%E5%8F%B6%E6%96%AF%E5%AE%9A%E7%90%86
https://zh.wikipedia.org/wiki/%E4%BC%BC%E7%84%B6%E5%87%BD%E6%95%B0
https://zh.wikipedia.org/wiki/%E6%9C%80%E5%A4%A7%E4%BC%BC%E7%84%B6%E4%BC%B0%E8%AE%A1
https://zhuanlan.zhihu.com/p/32829048
https://zhuanlan.zhihu.com/p/29846048
《深度学习进阶:自然语言处理》
