Unity MMORPG游戏项目优化
文章转载于https://www.gameres.com/812928.html
在优化Unity游戏时,我们一般从四个方面:CPU、GPU、内存、工程配置等入手,它们都可能是影响游戏性能瓶颈的关键。
CPU
我们平常游戏的很多性能瓶颈都在CPU。例如:MONO内存分配带来CPU开销,当Mono内存从50M、60M、70M,一直增大到100M,这些内存分配都相当于CPU的开销。当在Update函数中存在比较复杂的逻辑时,很容易出现每一帧都触发内存分配,如图01所示。
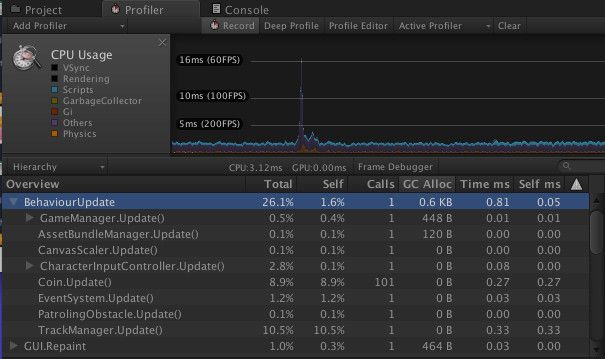
虽然截图中一帧里的GC Alloc只有0.6KB,但是当游戏运行很长时间后,累计数量是相当高的,这就让每一帧都存在GC Alloc带来的CPU开销。
处理客户端与服务器通信的数据包时,会存在序列化与反序列化,如果实现方式不合理时,会带来多余的内存分配。一般很多项目都现在使用Protobuff,如果是自行设计的数据包格式,就要考虑如何控制序列化与反序列化的内存分配。
静态数据表如果使用Json、xml等格式时,同时解析逻辑与数据结构设计不良,在初始化数据表时容易由于过大的内存分配而撑大MONO堆内存。所以要在项目设计时找到最优化的方式来实现功能需求与性能需求。
String是一个很常用的引用类型对象。当代码里存在字符串拼接、直接或间接调用ToString()函数时,会生成字符串的副本,也就产生了内存分配。例如:调用Object.name属性,即使每次返回值是固定的,依然是不同的String对象,因为这里每次返回都是一个对象拷贝。所以建议可以通过把这类字符串预先缓存,或者在打包时生成一个名字的列表作为静态数据,提供给运行时的逻辑直接读取。
部分Unity内置API在被调用时,都是返回对象拷贝。例如:Getcomponents、Sprite.Vertices、Input.Touches等。从设计角度是考虑代码安全性,防止外部直接去修改真正的对象数据。所以,这些属性返回值要做缓存。或者通过其他API来实现需求从而规避掉这个问题。请注意,Getcomponent只会在编辑器环境下存在内存开销,真机上不存在,大家在Profiling时不要被误导。
通常Debug.Log一类的日志函数应该只存在Debug阶段,但是很多时候这些函数没有屏蔽。如果它们出现在调用次数较多的逻辑中,就带来额外的CPU开销。同样Warning和Log存在相同的情况。虽然日常在console或真机Log里常见,但是经常没有被处理。建议对待Warning也要找到它的触发原因并解决,防止在Release中出现。Log函数不会因为打包为release版本就会自动屏蔽,需要使用宏定义来屏蔽。
闭包与匿名函数尽可能不要使用。闭包中调用外部变量,需要创建一个临时class对象来包含外部变量并且传给闭包函数,从而带来内存开销。匿名函数在作为一个函数的参数传入时,也存在内存分配。il2cpp中如果使用匿名函数当参数,不要用预声明的函数。
ParticleSystem API在Unity
2017.2之前的版本中,Stop和Simulate内部实现使用了闭包。粒子系统的一些API,例如:Start、Stop、Pause、Clear、Simulate在调用它们时会递归调用当前粒子节点下面的所有子级节点,并会触发GetComponent,这带来了一定的CPU开销。如果需要调这几个方法的时候,函数参数withChildren可以设为false,不触发遍历子节点。在粒子对象初始化时,预存子节点,在需要时直接根据缓存的子节点列表分别调用它们的Start。
Camera.main的调用是存在开销的,可以把Object.FindObjectWithTag(“MainCamera”)缓存下来来代替。调用射线检测函数时应该使用那些不存在开销的函数,例如Physics.RaycastNonAlloc。
当Canvas重建时,会引起材质的重新创建、排序、Mesh重建,这都会带来CPU的开销。当Canvas内容非常复杂的时候,每次重建很可能会带来比较明显的卡顿。UGUI里面的Mask会使用StencilBuffer,蒙版内的元素是没法和外面的元素做合批,即便在图集与材质都是相同的。这时可以用RectMask2D来实现蒙版,可以稍微降低一些开销。Canvas上的GraphicRaycaster选项,在不需要有交互时可以不勾选。而Layout组件会涉及到节点的遍历操作,都有内存与CPU的开销,如果能不用就不用它,或者自行硬编码实现简单的自动布局。
Canvas都建议做动静分离,频繁改动的元素和固定不变的元素分开到不同的Canvas。需要注意Canvas数量,数量多少根据UI的复杂程度、动静分离的Canvas个数进行测试,评估多少个Canvas是合理的。目前发现Unity2017.3中,出现过当Canvas数量达到十几个或更多时,带来的开销反而比不分拆时还大。
UI元素存在半透并很多元素进行叠加,就导致OverDraw消耗比较大。可以通过减少叠加层数、缩小Sprite的空白区域等方式来控制。
当Canvas 处于Worldspace或者Screen Space时,Canvas存在Event Camera或者Render
Camera属性,需要挂接Camera。此处若为None,运行时每帧都会有十几次访问它,底层默认返回Camera.main。所以预先关联Camera对象。
图集的分类方式直接影响到UI的合批效率。除了几个通用图集外,其它图集按UI模块类型区分,一个或多个UI公用一套图集。图集的面积利用率要做到最高,避免图集存在太多空白区域。而图标是分散还是合并到图集上,要看项目实际情况,并没有固定的规则。
UI背景图不要出现NPOT尺寸,如果要用NPOT,尝试多个NPOT图合并为POT尺寸,或者美术对NPOT图拉伸为POT,在Unity中还原为原始尺寸。
通常静态合批通过给场景上的物体勾上Static实现,但是有时会因为导致包体太大,改为运行时调用staticBatchingUtility.Combine进行物件合并。但是运行时手动静态合批会有不小的CPU开销,同时Mesh可读写选项也开启,在内存中边存在双份的Mesh数据,同时合并后模型也是一份新Mesh数据。建议可以用第三方插件Mesh
Baker来进行静态合批。同时,各个模型的材质也要针对静态合批来制作,毕竟相同材质的模型才可以合并。

动态合批对于大部分有Lightmap的模型是无效的,还存在900左右顶点的合批限制。在Unity 2017.3支持32bit Mesh
index buffers,可以合并Mesh时支持更多的顶点,可以在FBX选项内Index
Format打开或者运行时设置Mesh.indexFormat。
骨骼蒙皮计算一般使用CPU Skinning,虽然引擎也是支持GPU
skinning的,但需要注意性能瓶颈在CPU端还是GPU端。如果GPU端是性能瓶颈时,盲目打开GPU
skinning,会变成一种负优化。当角色模型的骨骼数超过100根、150根时,某些身体部位的骨骼动画,可以用BlendShapes代替。当某一部位骨骼动画不播放时,可以把这个部位的Animator组件关掉。Animation
Instancing也是一个可以优化大量角色动画性能的手段。
物理系统中,MeshCollider的使用在场景比较复杂庞大时,Bake的性能比较差。可以通过配合射线检测和自定义高度图数据控制角色高度。
GPU
顶点数量的控制,首先要从美术方面,控制模型的合理面数。有的建筑物被遮挡了一部分,被遮挡部分可以减面甚至把这一块抠掉留空。避免场景中出现大量小物体组合出一个更大的物件,设计之初就对零散物体合并材质、贴图、Mesh。场景地图也可以分区块制作、加载管理,同时配合LODGroup使用。还可以通过第三方插件Mesh
Baker LOD辅助进行。

纹理的尺寸会影响上传纹理时带宽的使用,也就是上传耗时比较高。通常3D模型的纹理,都会把打开Mipmap,可以提高纹理采样的质量,降低命中耗时,提升IO速度。同时纹理过滤模式的选择,对于UI纹理使用Bilinear足矣,Trilinear配合打开Mipmap后的插值计算,效果更好。
当一个角色带有一对翅膀,设置Mesh.alpha进行隐藏或显示,翅膀在Alpha=0时,依然被渲染。而显示全屏UI时,它挡住了后面的主场景,但由于场景Camera未关闭使得场景依然被渲染,如果此时UI里还显示角色模型,积累的渲染压力就比较大,这些都会体现在Overdraw消耗上。
根据对Shader的功能需求,对复杂度要进行控制。运算符要合理使用,变量的浮点精度要同时考虑计算需求和真机的实际支持的精度范围。对Tex2D、纹理采样的使用方式要合理,毕竟这类指令过多时会增加开销。
Unity引擎自带的Terrian系统,可以通过分区块或者转为Mesh解决此部分性能瓶颈。我们可以通过插件Terrain Slicing & Dynamic Loading Kit来分割地形,并调整地形的尺寸和精度等配置参数。

一个特效包含粒子发射器的数量不能随意创建,对渲染和内存都有不小的负载。当粒子存在发射Mesh的需要时,要控制Max Particles的数量。同时有些特效不一定要通过粒子系统实现,可以通过各种变通方式或低负载的方式制作。
内存
每一个Mesh的压缩选项、Read/Write选项都要根据Mesh使用方式进行单独设置,同时要做好当Mesh存在双份数据时,CPU端数据的及时释放。合理的减面也是必不可少的。
压缩纹理的使用是毋庸置疑,而压缩格式要根据项目的机型适配灵活选择,保证质量和体积都能满足需要。当编辑器中刷地形纹理时,需要纹理开启Read/Write,而在打包时要关闭这个选项。
每个纹理的尺寸要根据它的用途、实际测试时内存占用的情况,进行合理的限制,不能随意设定它。对于图集需要最大限度利用面积,避免浪费宝贵的内存。另外当纹理使用ETC2、ASTC格式时,在不支持这些格式的设备上,压缩纹理会被fallback为无压缩的RGBA格式,不但增大了内存占用,同时增加了fallback的CPU开销。
AnimationClip可以通过压缩浮点数精度,剔除无用的scale曲线降低内存占用。同时AnimationClip加载策略也对内存占用有很大影响,全部预加载还是按需异步加载,需要根据项目实际情况决定。
Mono进行内存分配时,在不同类型的数据对象在内存中是相邻的存在内存块里,如果说释放了一个数组,它所占的内存被释放了。但是这个区域是不会还给系统内存,依然保留着。接着又创建了新的对象,新对象的内存大小比刚才被释放的空间大,就无法直接放入这个空间,只能由Mono申请一份新的内存来存放。当Mono申请新内存时,Mono堆内存一般会扩大很大一部分,如见下图05所示。
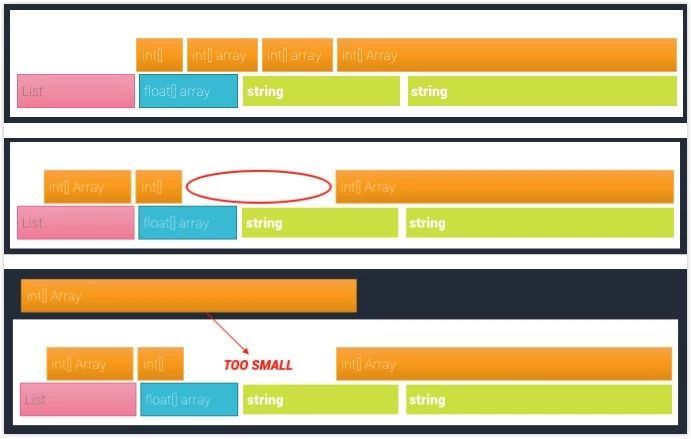
在使用数组类型的对象时,如果初始化时时非定长数组,数组实际容量会根据Add操作以0、4、8、16、32倍逐步扩大,其中大量空间为Null,浪费了内存。这种情况常出现在客户端初始化数据表保存到List、Dictionary时。
当我们需要手动释放一些对象的内存时,会有很多种方式,Unity提供了很多卸载各种资源的函数。主动调GC.collect是不必要的,如果一个对象的引用不是Null时,是不可能释放它的。GC只需要做好对象引用的清理就可以,剩下的还是由GC机制自动管理更好。我们可以通过自定义内存池和资源管理器,来很精细的控制每一种资源的生命周期。
AssetBundle压缩格式一般使用LZ4,但要注意AssetBundle的合理Unload时机。而LZMA格式,由于存在加载时解压后重压缩为LZ4的开销,一般情况下不建议使用。主Bundle卸载时,与它关联的依赖Bundle一定要根据引用计数来控制是否可以卸载,否则依赖Bundle的Asset容易引发内存泄露。
IL2CPP在安卓系统使用时,要注意libil2coo.so的文件大小。在安卓系统中,so会在游戏启动后直接加载在内存中,它的内存占用大小基本上和文件大小差不多。所以so的尺寸要有所控制,否则会影响整个游戏的内存数值。所以,使用il2cpp时要注意值类型的泛型、重复代码等容易增大il2cpp的cpp代码体积的情况。
其它
在PhysicsManagerSetting的LayerCollisionMatrix去掉不参加碰撞检测的layer。Time Manager中的fixed time step要根据物理系统的使用情况设置间隔时长。游戏分辨率要通过高中低配置来动态调整。
Graphics Stettings和内置Shader有关的开关根据项目使用情况来有选择的打开或关闭。同时建议所有Shader都要打包为Bundle来加载初始化。
项目的性能优化工作应该每隔一阶段就进行一次性能分析评估,及时解决掉性能瓶颈。同时应该有专人负责这一项工作,提高执行力。
虽然Unity Asset Store资源商店提供的各种插件功能强大,但是插件内部的一些逻辑没有考虑到移动平台的应用环境,存在很多不良代码,需要开发者仔细检查插件源代码,根据情况进行改进。并在性能测试时观察是否存在插件带来的性能瓶颈。
通常在对项目进行性能分析时,会有很多工具辅助我们进行分析工作。下面是我们推荐的工具:
- Unity Profiler & MemoryProfiler
- UPA (Unity Performance Analysis)
- Xcode & Instrunments
- RenderDoc
- Snapdragon Profiler

 浙公网安备 33010602011771号
浙公网安备 33010602011771号