elasticSearch使用总结
es与mysql的对应关系
mysql: 表 行 字段
es: 索引 document field
es6之前一个index可以设置多个type,es6每个索引只能有一个type,es7的索引的type只能是_doc,es7以后就没有type了,es去掉type是因为底层lucene
并没有type的概念,es在存储时把同一个索引下不同的type合并成一个type,这一个type包含了所有type的field,这会造成数据存储的稀疏,因为除了自己
本身的type的field有值,其他type的field值都是空,而且不同type的相同field名的类型必须一样,不一样会报错.
es支持restful接口和API访问.
用postman--restful接口的方式:
1 创建索引并指定映射: http://192.168.10.99:9200/index1
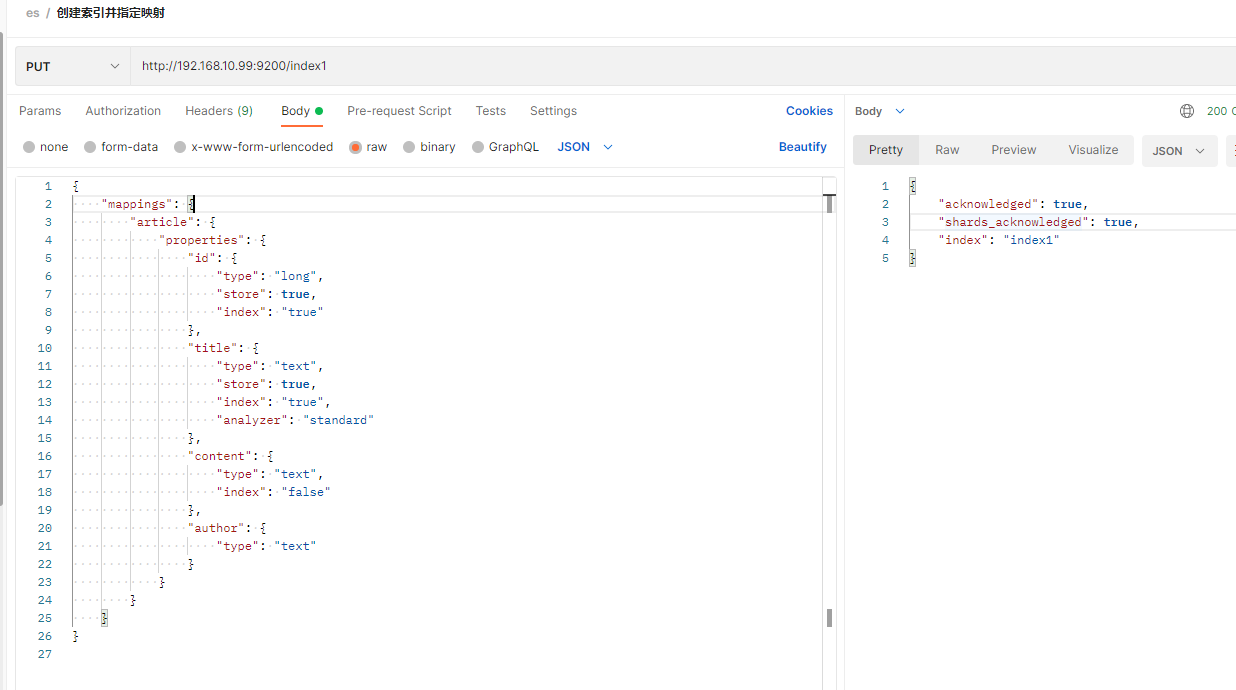
说明: 索引名是index1,类型是article,有四个field:id, title,content,author. title 指定要创建索引(这里的索引是指查询时使用的倒排索引,区别于前面的索引),content指定不创建索引,指定不创建索引就不能用于搜索,author未指定是否创建索引,这样写默认也会创建索引.analyzer是指定分词器名称,只有type是text时才需要,因为其他type类型不需要分词,type也可以定义为object类型,适用于包含properties子属性的字段.
定义mapping映射时需要考虑的是某个字段是否需要分词,如品牌,城市就不需要分词,不需要分词就定义成keyword(前提是字符串),需要分词就定义成text并指定分词器,再看是否需要查找/排序,需要就index:true或者不写,不需要就index:false
"city" : {
"type" : "keyword"
} 代表city这个field不分词整体存储并创建索引,那这个索引就是整个词.
2 查询所有索引
http://192.168.10.99:9200/_cat/indices?v
3 查某个索引的别名
http://192.168.30.53:9200/index1/_alias/*
4 根据别名查索引名
http://192.168.30.53:9200/_alias/sy_comp_nested_index?pretty
5 查询所有索引和映射
http://192.168.10.99:9200/_mapping?pretty=true
6 向索引中插入单条数据
http://192.168.10.99:9200/index1/article/1
{ "id": 1, "title": "ElasticSearch是一个基于Lucene的搜索服务器", "content": "它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。", "author": "北京牛逼坏啦科技有限公司开发一部杨坤" }
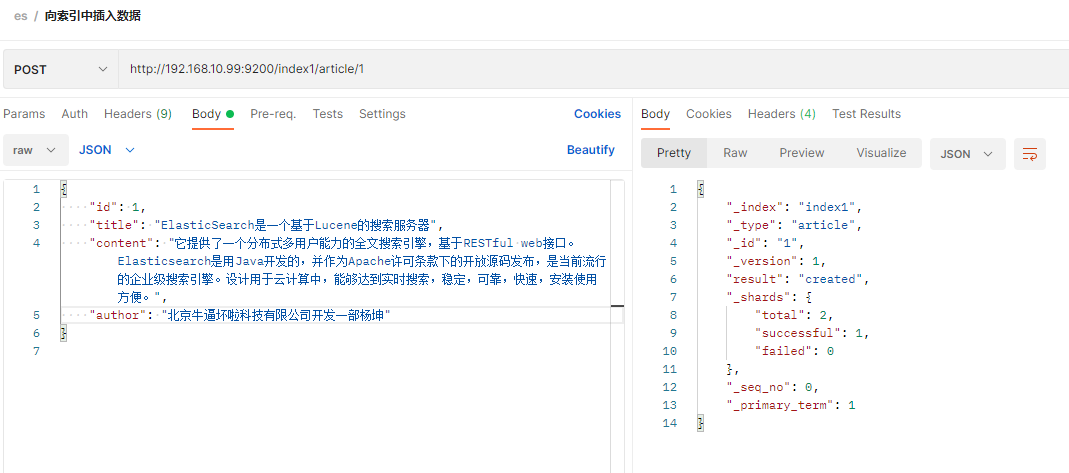
说明:单条数据插入只是学习es语法使用,生产环境可以用代码写批处理或者Logstash插入数据. 路径里article后的1是指定插入的id为1,这个id是es自己维护的_id,请求体中的id是我们手动创建的field-id
7 只显示部分字段:_source,字段排序:sort ,分页的用法
http://192.168.10.99:9200/index1/article/_search
es默认根据_score排序,如果指定排序字段,es就不会再算分,会提高速度
es分页的from+size和不能超多10000.
倒排索引:把文本内容进行分词拆分,生成 分词和文档id列表,用关键字查时直接查分词列,再找到对应的文档id.
例如mysql数据表数据:
id name price
1 小米手机 1999
2 华为手机 3999
3 小米手环 299
用mysql这种关系型数据库做全文搜索只能根据name字段用like做模糊匹配(不会走索引),逐条搜索效率很低
es会先将name进行分词拆分,小米手机拆成小米,手机,华为手机拆成华为,手机等,生成分词和id列表:
name id
小米 1,3
手机 1,2
华为 2
手环 3
如果搜索华为手机,es会将搜索词也进行拆分,拆成华为,手机,再去分词列表查,进而确定id号1,2,还能根据2匹配了两次,1匹配了1次,确定2比1匹配度高
es的数据类型 :
字符串类型:text (存储时会被分词器分词存储) , keyword(不能被分词器分词存储)
数值类型:long ,integer ,short ,byte, double , float, half float , scaled float
日期:date
布尔: boolean
二进制:binary
查询关键字:
term:通过倒排索引精确查询
match:使用分词器
注意:term和match是查询时指定,text和keyword是索引定义时指定
举例: 前面插入了一条author为 北京牛逼坏啦科技有限公司开发一部杨坤 的记录,现在用term查询一下
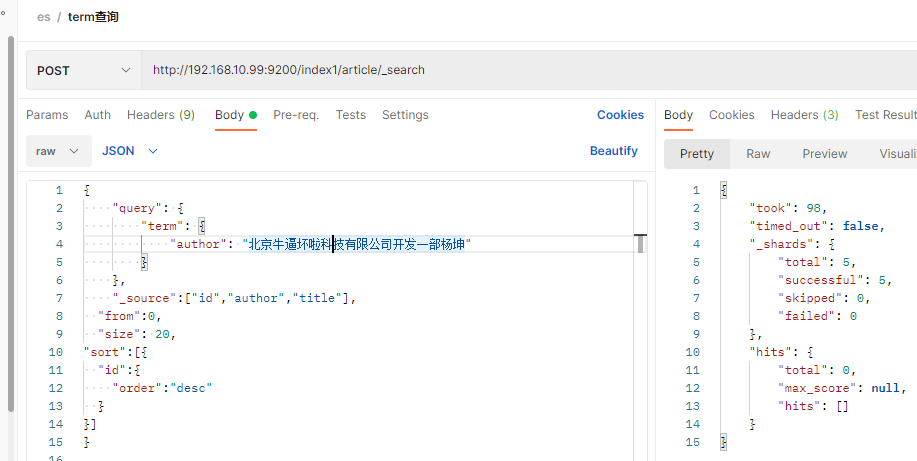
查不出任何数据,这是因为author为text类型,text类型存储时会用分词器分词,默认的分词器会把汉字拆成单个字存储,所以库里存的并不是这一段文字,而是拆成单个字,再用term精确查询就查不出任何数据,实际中term都是查keyword,数字,布尔,日期这种不拆词类型的字段不会查text分词类型的字段.
查看分词结果: http://192.168.10.99:9200/index1/article/1/_termvectors?fields=author
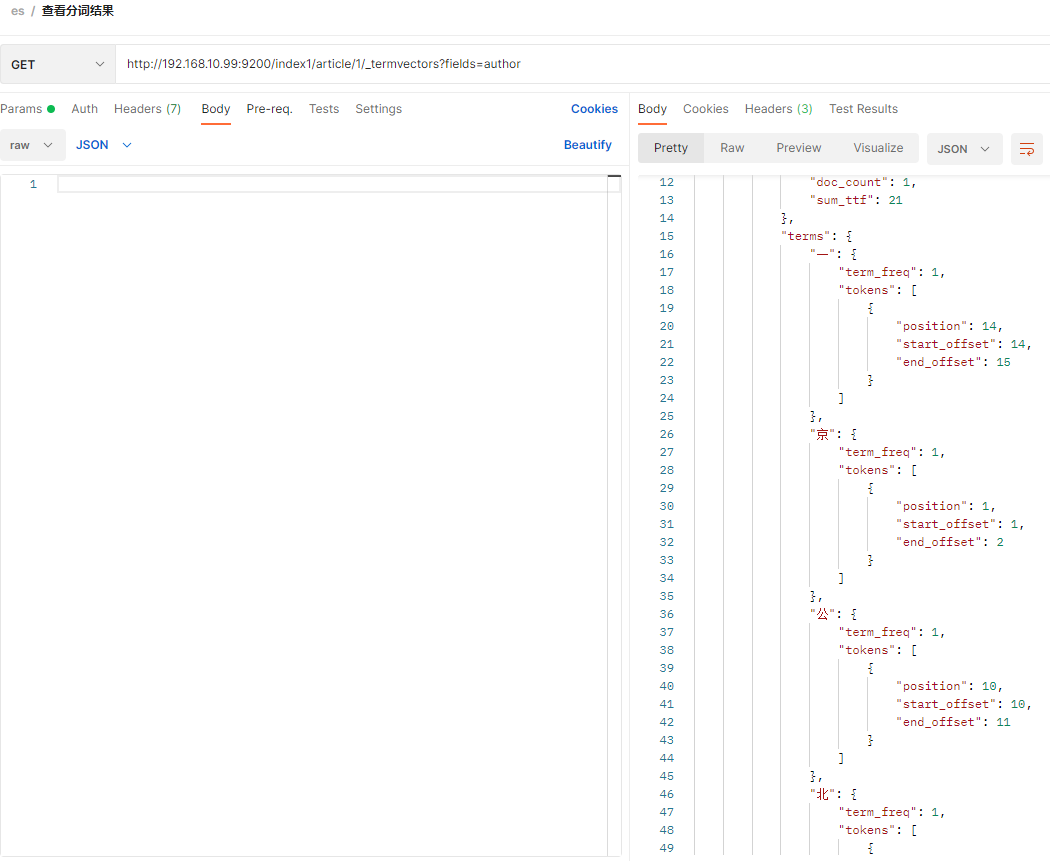
知道分词的结果后用某个分词进行term精确查询:
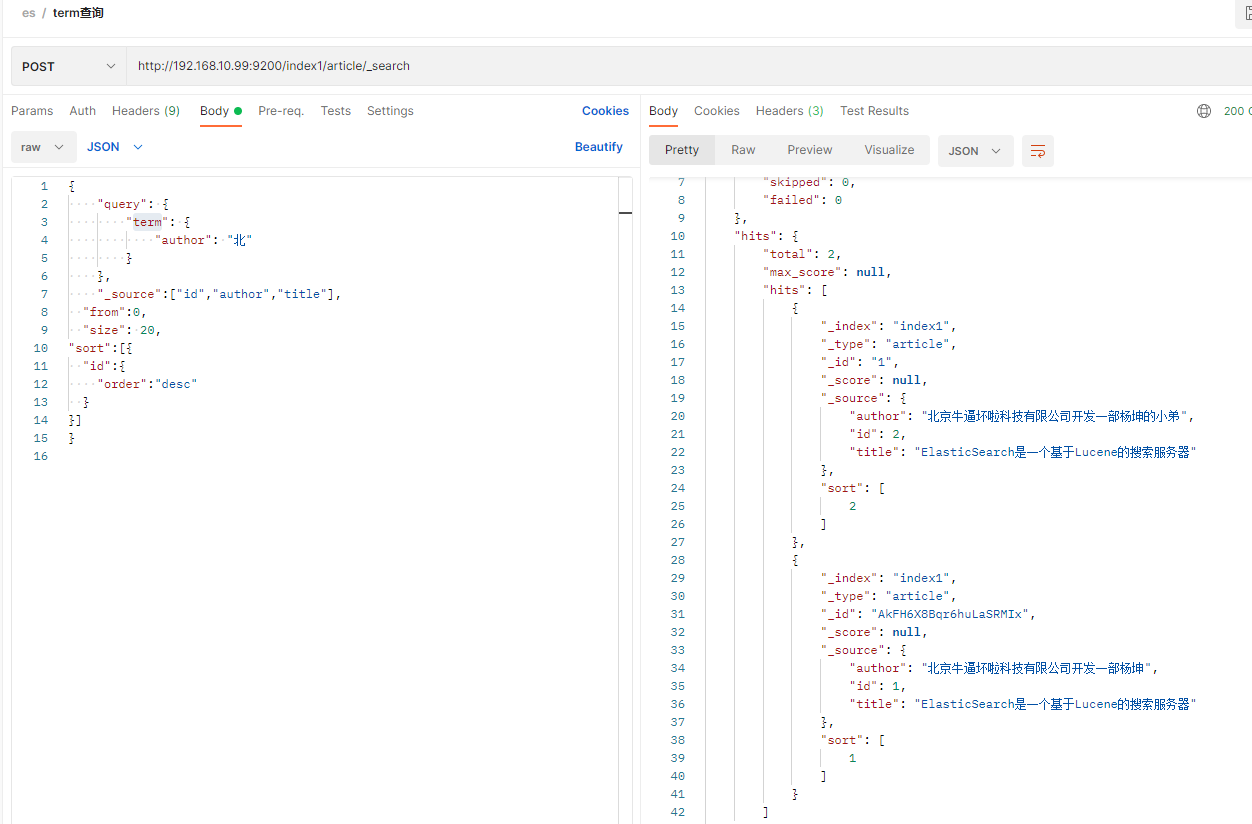
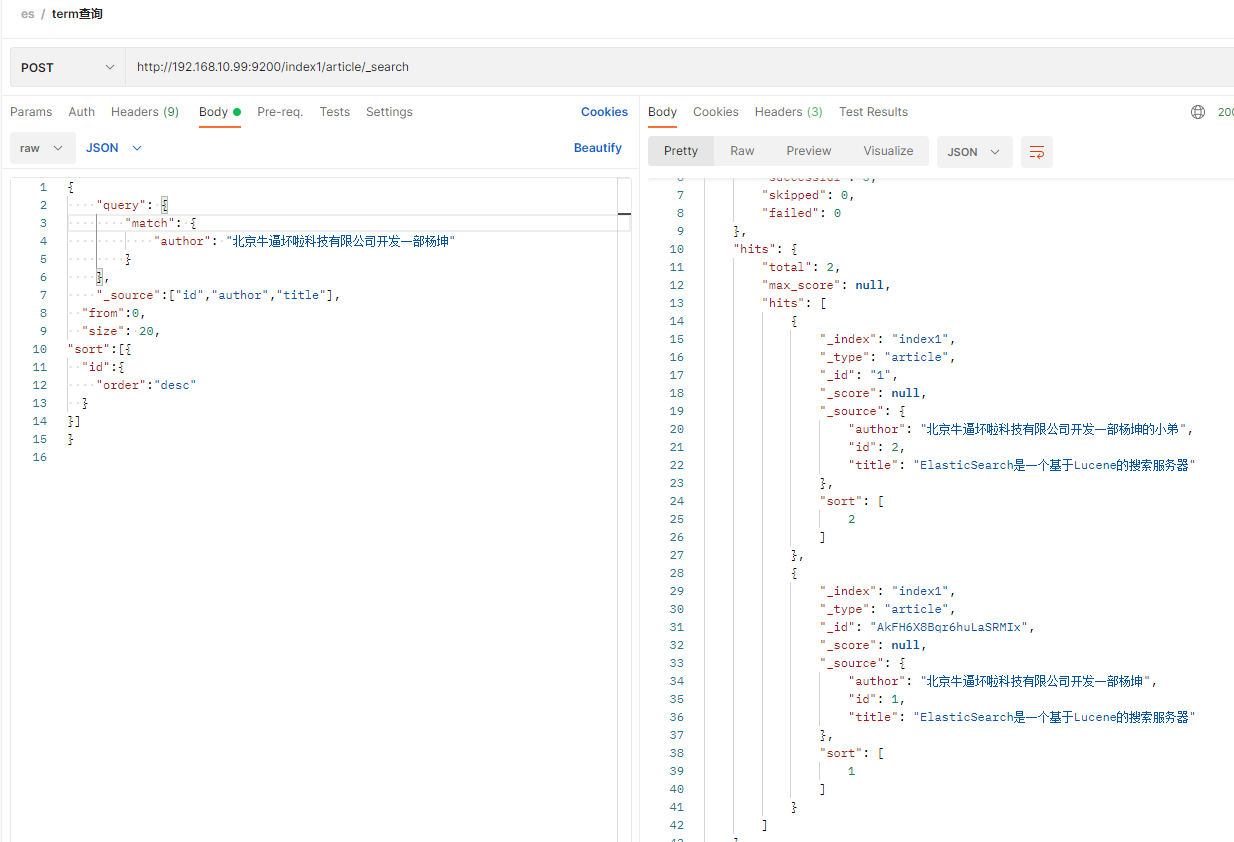
如果用整句文字查询,可以用match的方式,match会把搜索的文字拆成分词
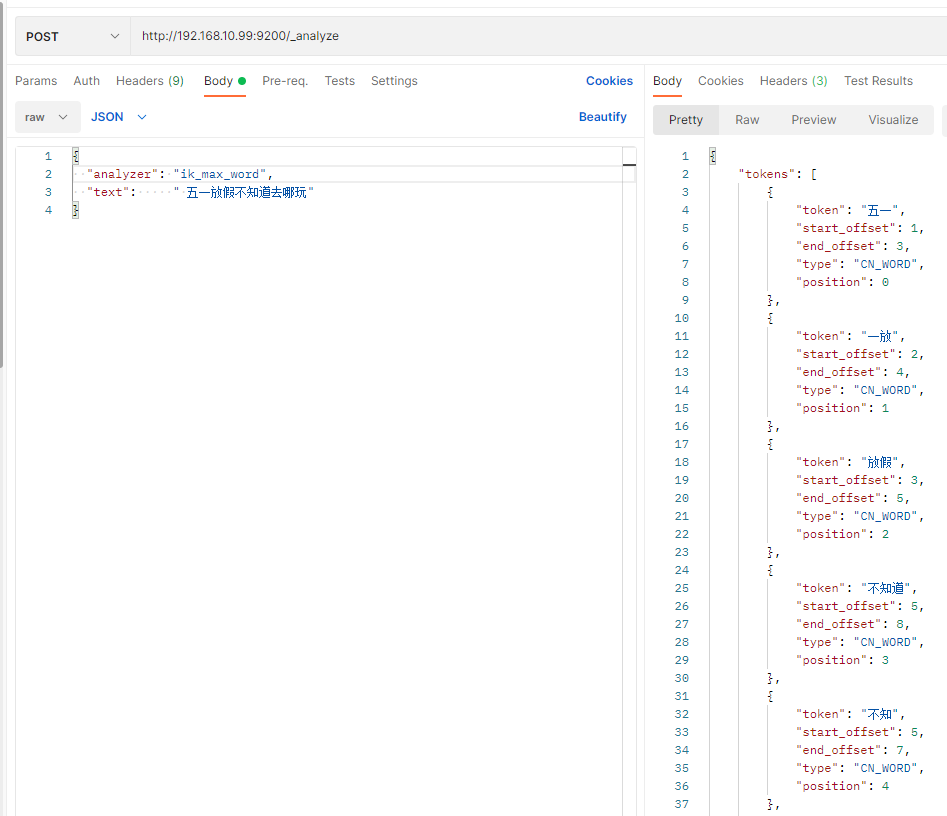
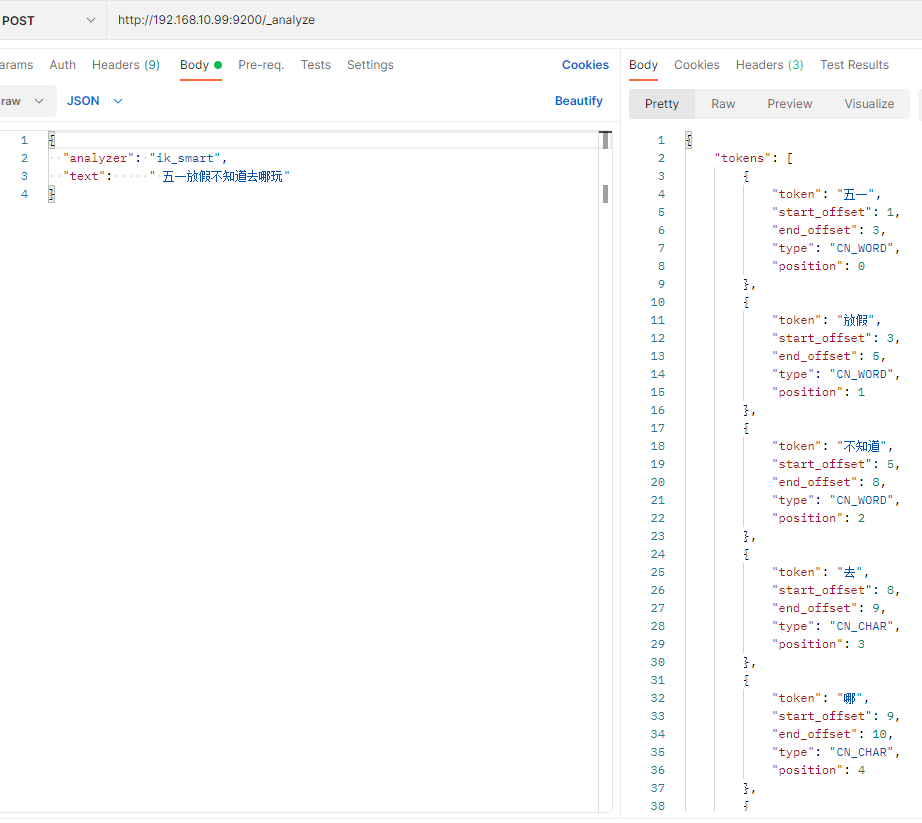
中文ik分词器:
下载:./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.3.0/elasticsearch-analysis-ik-6.3.0.zip (6.3.0换成es对应的版本)
ik有两种颗粒度的拆分:ik_smart: 会做最粗粒度的拆分(拆出来的词少), ik_max_word: 会将文本做最细粒度的拆分(拆出来的词多)
比如 程序员这个词,用ik_smart拆,发现程序员是个词后就不会对这个词再拆,ik_max_word发现程序员是个词后,会再尝试拆分,拆成程序,再对程序拆
直到拆不出词
对ik中文分词器进行扩展,添加自己的分词词库:
要拓展ik分词器的词库,只需要修改一个ik分词器目录中的config目录中的lkAnalyzer.cfg.xml文件:
<?xml version="1.0"encoding="UTF-8"?>
<!D0CTYPE properties SSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 ***添加扩展词典-->
<entry key="ext_dict">ext.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典 ***添加停用词词典-->
<entry key="ext stopwords">stopword.dic</entry>
</properties>
然后在lkAnalyzer.cfg.xml同级目录下新建ext.dic,stopword.dic,添加想要拓展/禁用的词语即可
一个词一行,不需要额外任何标点符号,常用的禁用词为:的,了,啊,呢这种无意义的语气词
字段的fiels属性:
text类型的字段只能用于全文搜索,不能排序,聚合,过滤,如果一个字段需要同时搜索和排序聚合,就需要设置两种类型,要用到fields属性
创建索引和映射
{ "mappings": { "article": { "properties": { "title": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } } } } } }
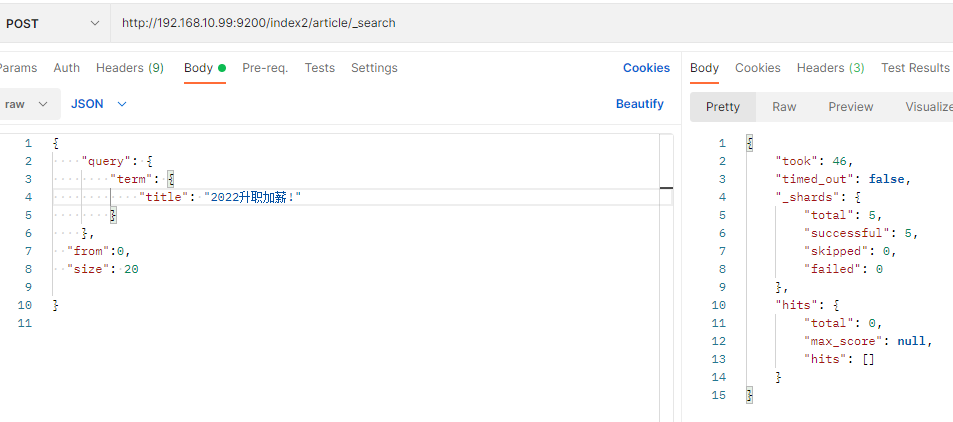
title.keyword是keyword类型,不分词
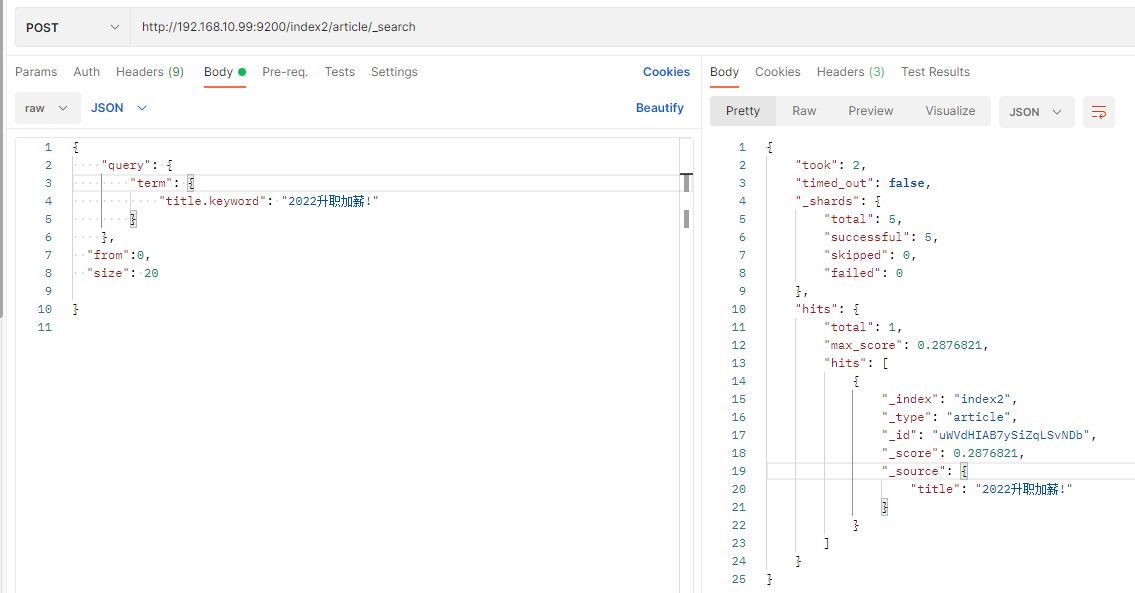
title是text类型,分词存储,查全部内容是查不出来的,只能分词查
DSL查询分类:
1 查询所有,查询出所有数据,一般测试用:match_all
2 全文检索(full text)查询:利用分词器对用户输入内容分词,然后去倒排索引库中匹配: match,multi_match
3 精确查询:根据精确词条值查找数据,一般是查找keyword,数值,日期,boolean等类型字段:ids, range, term
4 地理(geo)查询:根据经纬度查: geo_distance , geo_bounding_box
5 复合(compound)查询:复合查询可以将上述各种查询条件组合起来,合并查询条件:bool, function_score
6 高亮
1.1
全文检索查询的基本流程:
-
对用户搜索的内容做分词,得到词条
-
根据词条去倒排索引库中匹配,得到文档id
-
根据文档id找到文档,返回给用户
因为是拿着词条去匹配,因此参与搜索的字段也必须是可分词的text类型的字段
match查询:单字段查询
GET /indexName/_search { "query": { "match": { "FIELD": "TEXT" } } } #举例: # match查询 GET /hotel/_search { "query": { "match": { "all": "外滩如家" } } }
multi_match:多字段查询,任意一个字段符合条件就算符合查询条件
GET /indexName/_search { "query": { "multi_match": { "query": "TEXT", "fields": ["FIELD1", " FIELD12"] } } } #举例 # multi_match查询 GET /hotel/_search { "query": { "multi_match": { "query": "外滩如家", "fields": ["brand","name","business"] } } }
用copy_to将"brand","name","business"三个字段加入all中,两种搜索效果是一样的,但是搜索字段越多,对查询性能影响越大,因此建议采用copy_to,然后单字段查询的方式
3.1 term查询 :见前面term例子
3.2 range范围查询
GET /indexName/_search { "query": { "range": { "FIELD": { "gte": 10, // 这里的gte代表大于等于,gt则代表大于 "lte": 20 // lte代表小于等于,lt则代表小于 } } } }
使用range(范围查询)查询价格范围在1000到2000的数据:
"query":{
"range":{
"price":{
"gte":1000,
"lte":2000
}
}
}
4.1 地理坐标查询,使用场景:附近的人/车/酒店
4.1.1 geo_distance:查询到指定中心点小于某个距离值的所有文档
// geo_distance 查询
GET /indexName/_search
{
"query": {
"geo_distance": {
"distance": "15km", // 半径
"FIELD": "31.21,121.5" // 圆心
}
}
}
4.1.2 geo_bounding_box:矩形范围查询,需要指定矩形的左上、右下两个点的坐标,然后画出一个矩形,落在该矩形内的都是符合条件的点,使用场景少,不写了.
5.1 fuction score:算分函数查询,可以控制文档相关性算分,控制文档排名,elasticsearch会根据词条和文档的相关度根据BM25算法打分,就是_score字段
示例1:价格是50的文档根据评分降序,价格越接近50评分越高
{ "from": 0, "size": 12, "query": { "function_score": { "query": { "bool": { "must": [ { "term": { "price": { "value": 50, "boost": 1.0 } } } ], "adjust_pure_negative": true, "boost": 1.0 } }, "functions": [ { "filter": { "match_all": { "boost": 1.0 } }, "gauss": { "price": { "origin": 50, "offset": 0, "scale": "25", "decay": 0.5 } } } ] } }, "sort": [ { "_score": { "order": "desc" } } ] }
示例2:价格在200左右并且在给定坐标周围的数据按得分降序
{ "from": 0, "size": 12, "query": { "function_score": { "query": { "match_all": { "boost": 1.0 } }, "functions": [ { "filter": { "match_all": { "boost": 1.0 } }, "gauss": { "location": { "origin": { "lon": 130.380857, "lat": 31.112834 }, "scale": "150km", "decay": 0.5 }, "multi_value_mode": "MIN" }, "weight": 1 }, { "filter": { "match_all": { "boost": 1.0 } }, "gauss": { "price": { "origin": 200, "offset": 0, "scale": "25", "decay": 0.5 } }, "weight": 2 } ], "score_mode": "sum", "boost_mode": "replace", "max_boost": 3.4028235E38, "boost": 1.0 } }, "sort": [ { "_score": { "order": "desc" } } ] }
bool参数说明及示例:
minimum_should_match:指定在should查询子句中至少要匹配多少条件才算查询成功。
disable_coord:控制是否计算每个条件的坐标因子以调整查询的相关性得分。
adjust_pure_negative:控制是否调整纯负面条件的得分。
boost:为整个bool查询指定一个权重,以影响其在整个查询中的相关性得分。
function_score内重要元素说明:
query:普通的查询语句,筛选符合条件的结果,并把这个结果用作后面的评分函数的数据来源
functions:使用评分函数和编写脚本的地方,他的值是一个数组,也就是我们使用多个函数来进行综合评分(示例2中的functions就是两个元素的数组,用价格和距离两个维度来评分),还可以对每个评分进行权重控制,主要包含
1 filter: 符合filter条件的文档才会重新算分,
2 算分函数:
2.1 weight:算分值为固定的常量值,当weight为2时,结果为2 * _score
2.2 field_value_factor:使用文档中某个字段的值来改变_score,比如将受欢迎程度或者投票数量考虑在内
2.3 random_score: 生成一个随机数作为函数结果
2.4 Decay Functions:衰减函数,es内部支持的衰减函数有gauss(高斯)、exp(指数)、linear(线性)
2.5 script_score:使用自定义的脚本来完全控制分值计算逻辑
boost_mode:加权模式,控制的是查询分值(query部分)和功能分值(functions部分)是如何运算的,取值有max(使用查询分数和功能分数里最大值),replace(使用功能分数,查询分数将被忽略)等,默认是相乘
3 score_mode:多个评分函数结果如何运算
5.2 布尔查询,是一个或多个查询子句的组合,每一个子句就是一个子查询。子查询的组合方式有
-
must:必须匹配每个子查询,类似“与”
-
should:选择性匹配子查询,类似“或”
-
must_not:必须不匹配,不参与算分,类似“非”
-
filter:必须匹配,不参与算分
比如除了在搜索框进行关键字搜索外,还设置了价格,范围,评分等条件,就需要用布尔查询了
价格,范围,评分等条件既可以写在filter/must_not里,也可以写在should/must里,写法不是唯一的,区别就是放在must/should里参与打分,放在filter/must_not里
不参与打分.
参与打分的字段越多,查询的性能也越差。因此这种多条件查询时建议
1 搜索框的关键字搜索,是全文检索查询,使用must查询,参与算分
2 其它过滤条件,采用filter/must_not查询。不参与算分
hignlignt:高亮,默认情况下es搜索字段必须与高亮字段一致,如果不一致,需要用 require_field_match:false设置,比如match搜brand品牌字段是如家的,
酒店name字段需要高亮,这就是不一致
{ "query":{ "match":{ "all":"如家" } }, "highlight":{ "fields":{ "name":{ "require_field_match":"false" } } } }
查询结果中高亮的name在highlight里

es常用查询类型总结:
参考文档:https://blog.csdn.net/sinat_39620217/article/details/135620648 , https://blog.csdn.net/viperd/article/details/136626896, https://zhuanlan.zhihu.com/p/675425736

 浙公网安备 33010602011771号
浙公网安备 33010602011771号