
Temporal Coherence or Temporal Motion Which is More Critical for Video-based Person Re-identification(标红的是我自己一些思考,不过都是瞬时性的想法)
主要思想
将视频序列分为时间一致性特征和时间动作特征,且认为时间一致特征对Reid帮助更大。另外随机增加一些时间动作的 噪音,使得网络更多学到一致性特征。
不同于其他视频任务,reid更关注动作的主体,而不是动作。
时间动作线索通常会带来类内噪音例如姿势的改变特别是在聚合阶段。
这里作者个video-based reid 分了类:
1)挖掘动作线索
直接使用时间动作特征HOG3D;
从光流中学;
用RNN和LSTM对动作过程碱性建模;
3DCNN联合学习外观和线索。
2)聚合视频序列的嵌入
注意力机制找到关键帧
丢弃遮挡帧
但是由于类内方差(遮挡,不对齐)的存在,聚合仍是困难的,特别是关注时间动作特征的话,为了解决这个问题,精炼时间一致特征并用对抗的方式减少方差。这样是否加上对齐机制会更好
AFA机制:
AFA:将视频序列分为时间一致性特征和时间动作特征,对抗性的增加一些时间动作(temporal motion)的噪音来增强时间一致性特征。
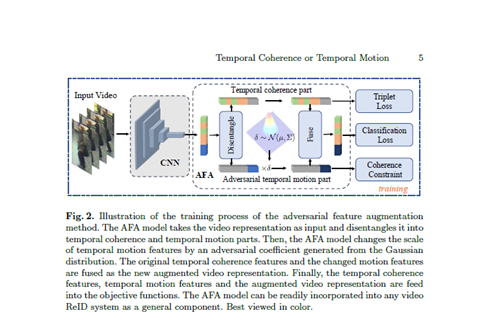
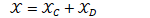

受prototypical network激发,假定不同帧嵌入位于流型,计算视频的原型作为类的中心不清楚这里的流型假定。
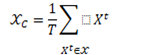
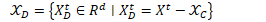
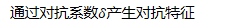
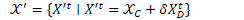
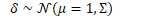

通过对抗训练,可以使学习到表达的类内方差(不同姿势,遮挡和背景)更小。
目标函数(用消融实验验证了每个损失都有用)

分类损失
注意分类损失是对每一帧都应用,确保时间一致性,另在计算分类损失前要归一化,因为该损失对特征尺度敏感。
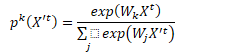
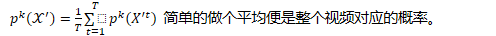
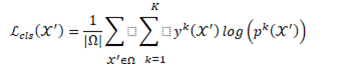
Triplet loss
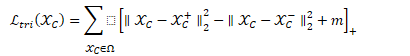
是margin,增强特征的分辨能力,这里采用了软margin 和难样本挖掘。距离是欧式距离。
一致性限制损失
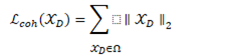
使用MSE减少类内方差,使主干网络更多发现一致性特征。
从以上损失函数可以看出:那么其实加的那些噪音只在分类损失这里有体现,使主干网络更关注一致性部分
如何验证时间一致性和时间动作那个更关键呢?
作者用AFA反过来验证的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号