
Video-based Person Re-identification via 3D Convolutional Networks and Non-local Attention
-
贡献:
3d卷积代替2d卷积
使用non-loca明确l处理不对齐问题(apm通过与相邻帧类似nonlocal
的操作也解决了不对齐)并捕获空时长范围依赖,注意但是没处理遮挡
-
引言里:
基于视频的识别包括提取特征和融合特征两部分
融合特征包括池化,rnn,以及注意力三种如下图。
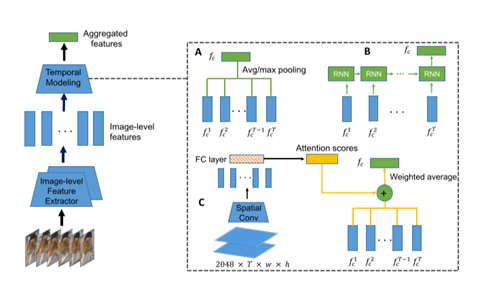
这里rnn的缺点是:最优辨别力的帧不能被rnn学到,因为对待所有的帧平等。这里不理解。
作者说这三种方法不能同时处理时间依赖,注意力和空间不对齐(应该是对应关系),单独如上图的只有时间注意力应该不能处理对齐问题。
作者的方法可以处理空间不对齐,以及时间依赖特征
三个贡献:
- 3d卷积获得空时特征
- No-local 解决不对齐以及捕获长时依赖。
- 融合空间注意力与时间注意力。
-
Related work
自注意力与non-local
nolocal本来是传统的数字图像降噪算法。Kaiming 通过泛化自注意力机制成为nolocal过滤操作。
- 提出的方法
-
整体结构
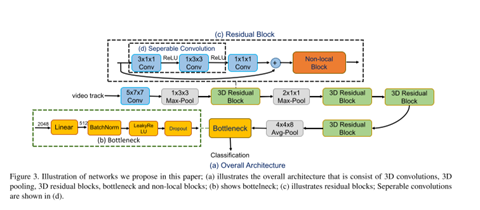
一个序列被拆成多个不重叠的片段,网络以整个片段做输入,输出一个d维特征向量,nonlocal嵌入到残差块中整合空间和时间特征(能学到每一帧像素级的关系和层次特征表达)。最后跟一个平均池化,然后boottleneck去加快训练提升性能,全连接层学习身份特征,softmax(加上标签平滑,一个trick)同时hard triplet loss用来进行度量学习,且用l2距离衡量。
-
3d卷积
使用c3d-like 3d太难优化,就使用2d膨胀成3d,在时间步上复制,然后权重缩小至1/t。继续拆分成1*3*3和t*1*1,将最后全连接层改为id数量。并在kinetics进行预训练。使用最后分类层前的特征作为视频片段的id 表征。
-
Non-local attention block
这里换成了原始论文的non-local图
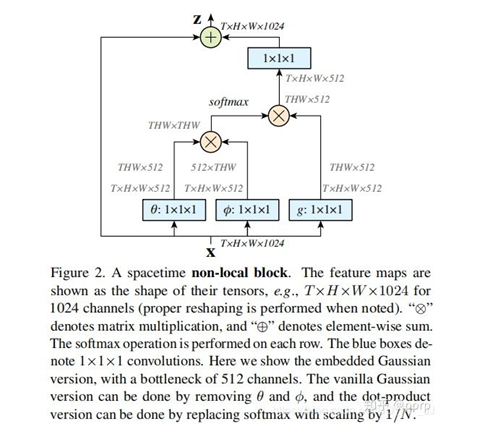
没啥说的,再写下公式
整体的:
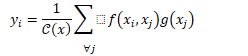
做嵌入高斯:
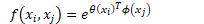
做softmax加权(注意论文里分母的求和下标写错了)
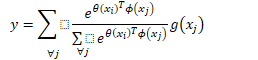
最后把non-local设置插残差模式
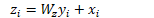
可以将nonlocal插入到预训练的模型中(例如将w设置为0就不影响原先的行为),可以构建一个更有层次的结构结合了全局和局部信息。
-
loss函数
采用triplet loss 加难样本挖掘,和标签平滑的交叉熵。
每个batch p的id,每个id,k个片段,对于每个样本a,选择最难的正样本和负样本计算triplet loss。
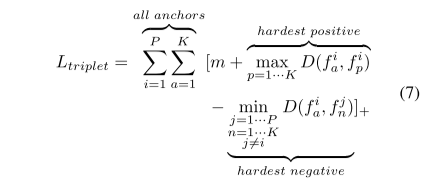
加了标签平滑的softmax
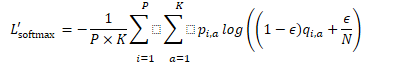
总的损失为上面两个损失函数相加。
- 实验
-
实现细节
五个nonlocal插入位置与原始论文一致。

训练时:8帧的片段来自于(64个连续帧每8个随机取一张。)空间尺寸256*128,
随机裁剪自被缩放的视频(尺寸被随机缩放为1/8)为了训练难样本tripplet loss,每个batch,32个id,每个id四个片段,一个epoch里枚举完所有的id。bottleneck里包含全连接层,bn,leaky relu(α=0.1)dropout(0.5),学习率用指数下降的办法(试一试warm up),adam被采用,权重衰减为0.0005.
初始化方法 以及bn与nolocal的位置

-
消融实验
Baseline

3d,non-local都是有用的。(比多样性正则都好(prid数据集不如)?Diversity regularized spatiotemporal)
不同的初始化方法
对比了在image-net,reid(图像数据集),kinetic预训练的效果,kinetic效果更好(这种实验有点多余),不太适合顶会。
-
总结:
3d网络:像素级的信息和相关性
Non-local 明确解决空间与时间的不对齐问题(non-local是能解决一些对齐问题的,apm也是通过与相邻帧类似nonlocal的操作来解决对齐)。
但是注意nolocal解决不了遮挡问题。(Appearance preserving 3D Convolution 解决了这个问题算是吧,通过除掉遮挡,但我觉得可以试试gan来恢复遮挡内容)
-
感悟
这篇论文比起vrstc,好像就多了个3d卷积。 记得看下效果对比
相比之前sota
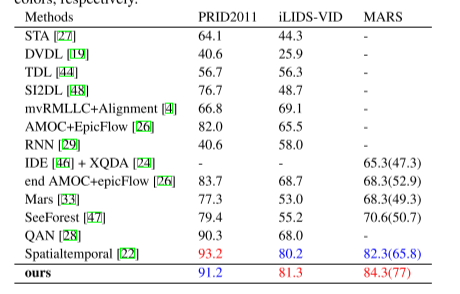
Vrstc mars数据集 88.5 (82.3),同一年,所以恢复遮挡效果应该很好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号