
Vrstc stcnet
这里试着把他的网络改成3d卷积加nolocal看效果会不会更好。
或者把stcnet加到其他网络里看看效果。
主要是用来做数据增强的。
STCnet 明确处理部分遮挡问题,通过空间结构和时间信息两部分来重建。重建部分用的都是autoencode。
最近的办法(2019)通常使用注意力来提取最显著的部分,但是对于遮挡部分一般是丢弃。(其实20年也有很多注意力办法是丢弃的)
最近工作:
提出时间卷积提取局部动作,但是平等对待每一帧,这样遮挡会造成破坏。
Rnn时间注意力机制去选择最有辨别力的帧
使用卷积网络对每一帧的质量评分
空间注意力和时间注意力结合,空间注意池化选择最有辨别力的特征,通过时间注意力池化选择有用信息
使用多个空间注意力模块去关注不同部位,然后通过时间注意力进行池化。(这篇论文就是Diversity Regularized Spatiotemporal Attention for Video-based Person Re-identification)
图像补全的一些工作:
Gan
Conttext encoder 用重建损失和对抗损失生成清洗图片
空洞卷积去处理任意分辨率
全局和局部描述符通过对抗损失(stcnet 基于这个,另外还采用了guide-id保证生成图片的一致性)
STC net
整体结构:
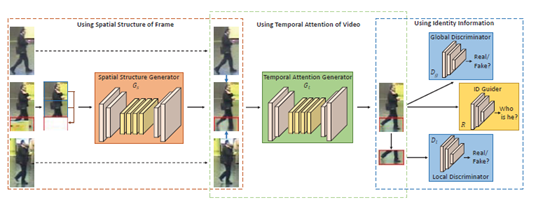
空间结构生成器:
Autoencoder 将遮挡部分像素设置为像素,且生成的图片只取遮挡部分然后和原图融合。
具体细节:encoder采用空洞卷积扩大感受野,有助于传送远处的信息到达感受野。

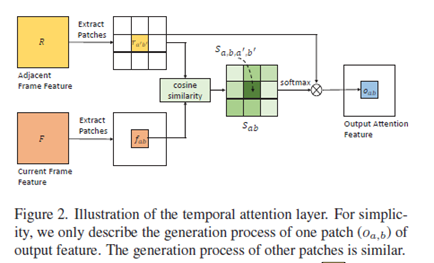
时间注意力生成器(通过空间生成的图片与相邻图片产生注意力 gated map(有点类似于注意力但不是),然后送到时间生成网络生成图片)
一些算式(和nonlocal 一对比就清楚了):
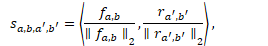
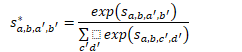
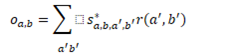
时间注意力图的摆放位置(没弄明白):


两个分辨器(gan里的)
看图,判断生成的遮挡区域从全局和部分看效果是否好,采用3*3卷积,步长为2,最后全连接层采用sigmod 作为激活函数。
和id guider 网络
输入完整的帧,输出id,使generator生成的图片具有一致性
采用resnet-50,移除最后的空间下采样操作。
目标方程
重建损失捕获结构(autoencode的损失),对抗损失(对抗网络)保证真实性和一个guder 损失使生成帧得id不变。
重建损失 即是生成和输入的L1距离(包括空间重建和时间重建)
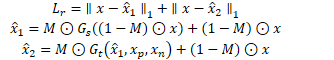
M是用来从生成图片里取遮挡位置的图片的,其他位置仍然用原图的。
对抗损失:全局分辨器和局部分辨器两部分组成
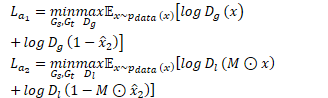
交叉熵损失(guild-id网络)
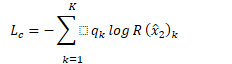
最后 stcnet的总损失为:
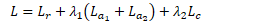
和Re-Id网络进行整合。
首先要找出哪张图片的那个部分有遮挡,stcnet恢复外观,最后用恢复的图片训练训练re-ID网络(这个网络不复杂)。
定位遮挡位置
有一些工作通过注意力机制来定位遮挡帧,但是因为没有额外的监督信息,这样做是困难的。
由于遮挡出现在一小部分连续帧里,并且遮挡和其他部位有很大的语义差别,使用帧的区域和视频区域的cos 相似度来判别。
视频区域的特征
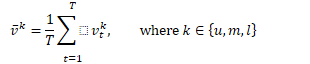
然后每个帧区域的得分由下式子计算
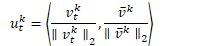
经过试验,当得分低于阈值时,认为该区域为遮挡区域。通过stcnet 恢复区域。
Re-ID网络
stcnet可以和大部分sota reid模型结合,这篇论文为了验证stcnet这个数据增强办法,这里使用了简单的re-ID网络(进行了平均时间池化和交叉熵损失)
使用res50作为主干,并且嵌入了non-local(不同于以往只插入到最后建立时间依赖性,作者的方法将non-local插入到深度网络的早期部分),可以建立起富裕的层次时间依赖,结合了非局部和局部信息。
实验:
实现细节
先预训练res50作为guider网络(用交叉熵函数),每个输入序列取4帧,通过res50提取特征,然后进行平均时间池化去获取数据序列特征。注意预训练没有nonlocal,数据增强只有水平镜像。
定位遮挡区域
训练stcnet
固定guider 网络的参数,只使用未被遮挡的图片进行训练,通过随机遮挡区域,注意空间,时间生成器,和两个辨别器我轮流用adam优化器进行优化。
训练完后,用stc恢复遮挡部分的外观。
提升
用恢复遮挡后的数据集重新训练reid,且把non-local嵌入res50里,
res的插入位置与non-locl论文一致。

注意测试时不用恢复遮挡

消融实验
验证了时间生成器的作用(并不是因为加深了空间生成器)
也验证了时间注意力层的作用(但是我还不确定时间注意力层加的位置)
全局分辨器和局部分辨器提升比较小(作者推测分辨器目标是生成更真实的图片,没有带来额外的分辨信息。)
ID guider network的作用:通过在训练stcnet的时候加不加guider的损失,结合最后的性能,来判断id guider network的作用,这里ID guider network既用来辅助训练,也用做reid网络。
比较了损失函数的两个系数的作用:系数较大会发生退化,是因为对抗损失或者guider 损失占据主要成分时,stc收敛会变得困难。
遮挡阈值的判断
给定一个阈值,丢弃在低于阈值的帧,然后提取到融合特征,与视频计算相似度。
与各种sota的比较
加了光流的snippet效果比这个模型好
可视化:
发现如果不去除遮挡,网络的关注点有可能会在遮挡上 。
结论:明确处理遮挡问题然后训练re-ID网络。将来将研究各种生成模型去恢复外观。
上下这两张图是原图,还是时间注意力图呢?
遮挡数量较少,可在整个数据集上,提升却很明显。
训练stcnet时,损失函数里有guider损失的,且因为guider冻结参数,所以这里起到了指导作用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号