
Spatial-Temporal Graph Convolutional Network for Video-based person Re-identification
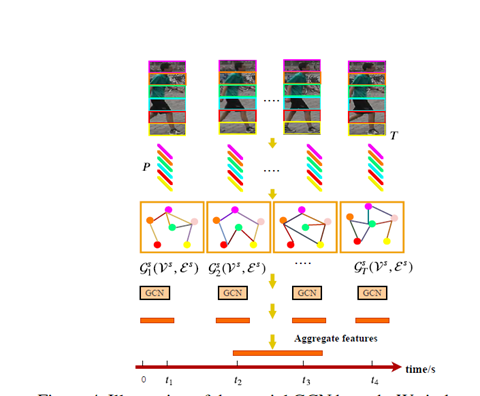
整体结构如下图

考虑了不同patch在所有帧上的关系,以及每一帧上的patch关系(结构)
因为对图还不是很了解(下面先直接总结论文)
Patch graph construction
每对节点间的关系
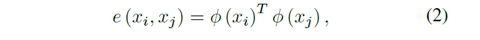
允许我们动态的选择和学习不同patch的关系(这里的patch指的 是把特征图切块并池化后的一个d维向量)
邻接矩阵:

每一行和为1,且无复制。

用这个公式逼近图的拉普拉斯
TGCN
捕获patch在不同帧上的时间关系
把所有patch都当做顶点构造对应的邻接矩阵

构造m层卷积去捕获关系,第m层,图卷积表示如下:
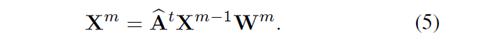

并且每一层后设置Layer Normalization 和 leakrelu
并且每一层设置残差连接。
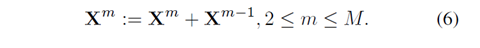
对最后的X进行池化,

SGCN
提取每一帧的结构信息,然后最大池化,然后fuse(concat) 所有帧。
获取邻接矩阵,且每一层的卷积公式如下


Loss函数:
Batch hard triplet loss function
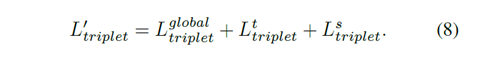
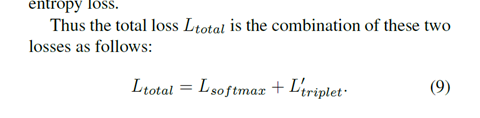
实验:(只写感兴趣的,tgcn,sgcn都是有效果的)
这里作者试着把每一层的卷积表达式去掉邻接矩阵,即把图卷积变成全连接,发现效果变差。
图网络不能过浅也不易过深(over-smothing)
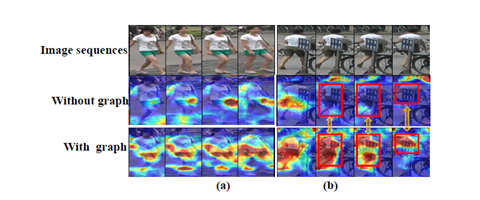
可视化后发现也是有一定去遮挡作用的,且关注点准确。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号