
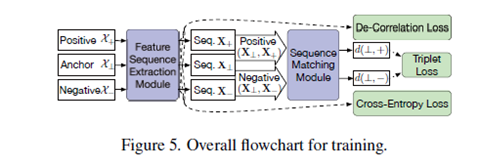
Dual Attention Matching Network Reid
特征序列生成
图片:通过dense net 多通道特征图,然后特征图上一个位置的所有通道作为一个特征,所以多个位置就形成了多个特征序列。
视频:经过densnet,各个帧对应的特征图经过rnn(按帧,也就是按时间步),然后将每一时间步的隐藏状态作为特征序列对。这样的话:第一个时间步的隐藏状态其实就不包括时间全局信息。
序列匹配模块(如下图)
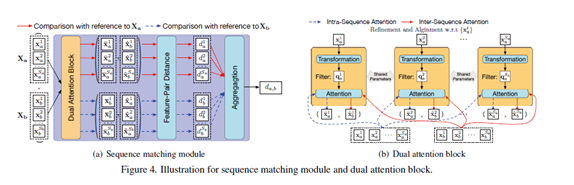
一个transform层(就是一个线性变化加bn加relu)一个attentionmap层(无参数的)
如果像以往的办法直接匹配序列对的话,会受到不对齐的影响。
所以 refine ,对齐(无先后关系)
主干网络提取到两个特征序列,需要分别对每个序列进行refine,对齐。论文里是以a序列来说的。
这里也以a序列来说:(从上图可以清楚看到)
将a里的一个特征送入transform层来生成key(其实他后面的作用就相当于attention的),然后用这个key和a序列内的向量做內积(是要做softmax归一化的),和a序列做加权和对这个特征做refine;接着用这个key和b序列内的向量做内积(是要做softmax归一化的),和b序列做加权生成和a特征对齐的特征。这样针对a序列里的一个特征做refine和对齐就完成了。
中间涉及到的公式:
transform层:
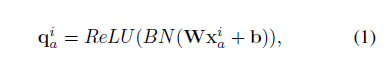
Attention layer 层求內积(点乘)(a序列内,b序列间)
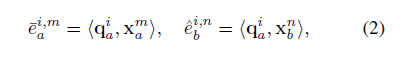
內积做归一化并加权:
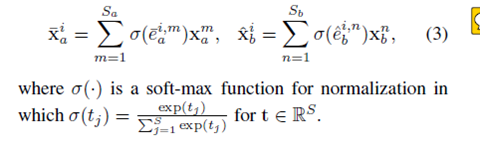
距离计算和叠加。
分别对a序列的每个特征做refine和对齐,然后每个特征对(refine,aligned)求欧式距离并进行平均池化。
同样对b序列在做一次
公式如下:

损失函数:
3个
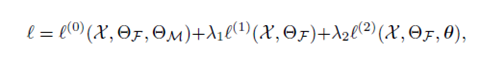
如图所插入的位置,特征提取模块用函数F表示,匹配模块用M表示
Triplet loss:
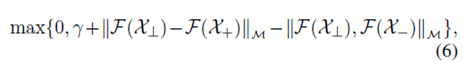
De-correlation loss (放在特征提取模块后)
x是序列内部特征向量矩阵,N是一个序列的数目。
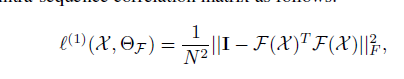
Cross-Entropy Loss with Data Augmentation
通过对提取到的特征重新组合,保持id不变来增强数据。对于结果提升明显。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号