
Diversity Regularized Spatiotemporal Attention for Video-based Person Re-identification
主旨:用空间注意力和时间注意力来解决遮挡和不对齐问题
自动地发现不同部位的注意力(即训练多个注意力模块)
不会受遮挡和不对齐影响(这里是因为时间上的注意力模块会自动择优(权值大的))
可以这么理解:先在空间维度注意力,然后再在各个部件维度的注意力,所以就不需要考虑对齐和遮挡问题了。
以前基于视频的方法最大池化或平均池化,即任何聚合方法都会受到遮挡或不对齐的害处。
特色
使用空间注意力(我觉得还有时间注意力)来解决遮挡问题
使用很多注意力模块去聚焦各个部位和衣服。(用无监督的办法训练)
无监督的办法指的是给损失函数加一个惩罚项,使得各个空间注意力模块概率分布区分开,这里不用KL 是因为注意力的概率大部分接近0,由于log的存在会使得训练不稳定。
对每一个部件使用时间注意力来进行聚合。
一些相关工作(有些论文挑选下看需要看么)
空间时间分割方法提取视觉线索,使用颜色和剧烈的边进行前景检测。定义了图像识别这一任务。
图像识别一般聚焦两个方面:提取有辨别力的特征,学习鲁棒的指标(度量)。
Xiao 提出一个网络实例匹配损失函数,该方法在学习特征上更有效在大龟波验证问题上。
You 展示了一个 top-push 距离学习模型(最小化类内方差来实现)去优化匹配准确率(top rank)
McLaughlin 引入RNN模型编码时间信息,使用时间池化选择最大激活在每一个特征维度。
Wang 选择可靠的时空特征,同时学习排序函数
Ma等人的[34]编码多个时空动态粒度,为每个人生成潜在表示。一次
推导出位移动态时间弯曲模型,在不准确和不完整序列之间进行数据选择和匹配
注意力模型:自__________开始变的流行。
根据rnn的隐藏节点赋予每一帧重要性,输出结果是rnn输出的时间池化(这里的池化指池化么)。根据这种方法,不同时间步的注意力模型将有相同的值
Liu 提出一个多方向的注意力模型去利用全局和局部内容(基于图片的ReID),但是训练多个注意力可能会造成模式崩溃,必须小心训练防止注意力聚焦在相同的地方,我门的模型就解决了这个问题。
方法
随机采样:先分块,再在每块随机采一张。
多注意力模块。(每个部件一个,通过惩罚项让各个模块关注不同的地方)
将N张图片送入预训练的(resnet cov1~res5c),得到N*2048*8*4,然后送每个图片的特征图卷积(压缩通道),在进行softmax形成8*4的mask,mask乘上输入的特征图即获得attentionmap(2048*8*4)
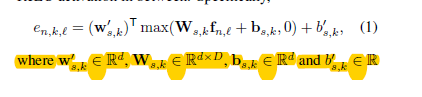
压缩通道的具体实现是经过两次卷积,先压缩到d维,在压缩到1通道。(这里联想下cbam的空间注意力便很容易理解。)
注意这里是有多个mask的(每个部件一个),然后通过加到损失函数里的损失项,使得他们聚焦于不同的位置。
softmax的实现
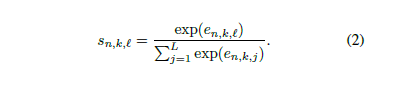
mask乘上如图特征图:(学名叫spatial gated feature)
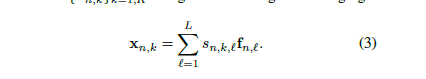
注意得到的map还要经过一次增强。

具体细节不清楚

Attention model 的多样性正则
KL不能用因为有log
这里使用HELLinger 距离
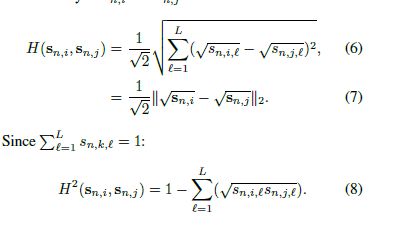
最大化距离相当于最小化
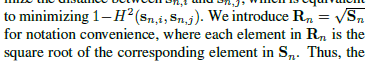
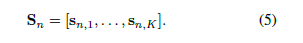
因此正则项变为

且会被加入到损失函数中。
不同于下面的正则项(用在rnn里的文字嵌入)
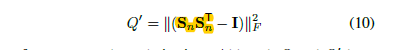
上面的正则项是通过hillinger 距离推导出来的,前提是
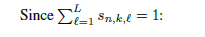
并且他俩的意义也不同

时间注意力模块
这里是根据每个部件分组,然后在每组分别应用注意力机制
这里抽象的概括下通道注意力的机制
全局池化,然后调整通道数,然后又把通道数调整回去,然后再通过relu或softmax,在乘上原来的特征图。
时间注意力实现如下:

这一步可以理解为全局池化

可以理解为相乘
空间注意力和时间注意力结合,最后k个特征结合在一起。形成最终特征。

Loss 函数: 这里使用了OIMloss

OIM loss使用一个存储了之前训练集中所有行人特征的查找表,在前向过程中,每个batch中的样本利用了之前所有行人特征计算分类可能性。OIM loss被证明在行人重识别任务中比Softmax loss更有效(得读读这篇论文)。
实验
几个数据集的介绍,其中mars最大
现将resnet-50 在图像数据集上预训练,然后在mars等数据集上微调,然后固定cnn,加入多个空间注意力模块,时间平均池化,oimloss进行训练,最后整个网络除了cnn,进行联合训练。
Bsgd 初始学习率设置为0.1然后下降为0.01,最后聚集的特征向量经过最后一个fc层
fc降维到128维,然后进行了L2-norm,来表示整个视频
训练阶段采用了上文介绍的采样方式,在测试阶段使用N个片段的第一张图片
PRID2011、iLIDS-VID数据集使用Rank-1,而Mars使用Rank-1和mAP
成分分析如上图,Baseline是指相同的训练方式,但是仅使用ResNet50,提取各帧特征后时域上平均池化,再经过128fc+OIM loss.SapAtn是使用了多空间注意力模型+时域平均池化+128fc+OIM loss。SpaAtn+Q'和 SpaAtn+Q是在SpaAtn的基础上加了多样性正则项。SpaAtn+Q+MaxPool是将时域平均池化变成时域最大池化。SpaAtn+Q+TemAtn使用了时域注意力模块。SpaAtn+Q+TemAtn+Ind是在SpaAtn+Q+TemAtn的基础上最后在相应的测试数据集上进行了fine tune(包括cnn)。
Baseline和SapAtn对比,说明作者的多空间注意力模型能够学到行人身体上有助于判别的信息。
SpaAtn和SpaAtn+Q'以及SpaAtn+Q对比,说明了多样性正则项能够很好地促进多空间注意力模型
SpaAtn+Q'以及SpaAtn+Q对比,证明了作者提出的基于F-距离的正则项Q相比于文本嵌入中常用的正则项Q的有效性,作者认为效果更好的原因是Q使得网络能够学到更大且不重叠的区域
SpaAtn+Q和SpaAtn+Q+MaxPool和SpaAtn+Q+TemAtn的对比,证明了作者时域注意力模块的有效性(大概提升1%)
SpaAtn+Q+TemAtn+Ind说明,最后整个网络在视频数据集上fine tune后,效果最好
这里可以思考下注意力mask是不是都是无监督的训练办法,
和non-local的区别。
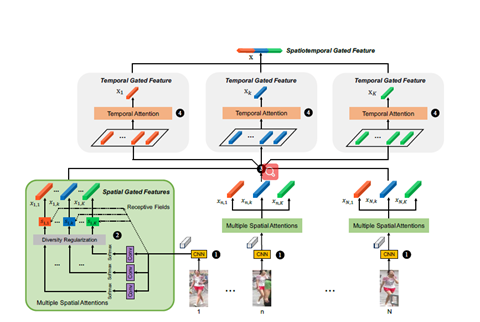
通过实践注意力解决了遮挡,这张图很好的说明了

比如这里给了无遮挡很大权重。
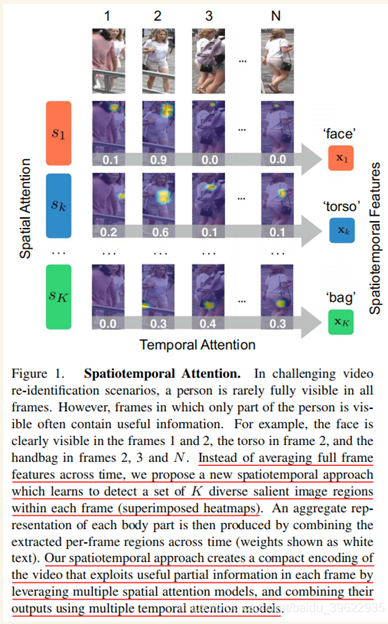
时域注意力的可视化结果,可以看到,作者的时域注意力相比于平庸化的时域平均,能够有选择地关注到无遮挡空间注意力区域。比如对于注意面部的空间注意力模型S1,经过时域注意力模块后能够重点关注第1、2帧人脸比较清晰的图像。而后对于面部信息不太好的后两张,则不关注。

多空间注意力模型的可视化结果,可以看到,作者的方法能够关注到大的且不重叠的对判别有利的区域
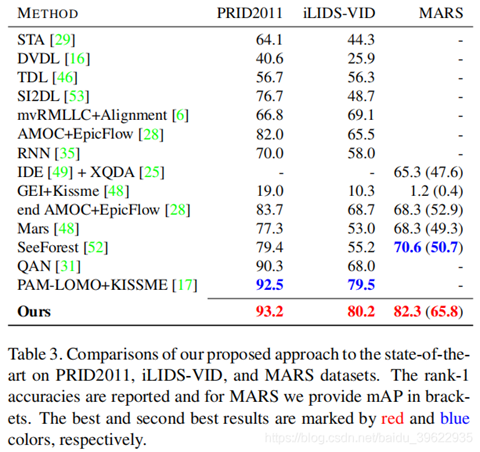
表3是和state of the art的对比,结果说明作者的方法在三个数据集上都超过了state of the art,其中在MARS数据集上提升最大,有11%的提升,说明作者的方法很适合场景较复杂的视频行人重识别问题(MARS有很多distractors)。
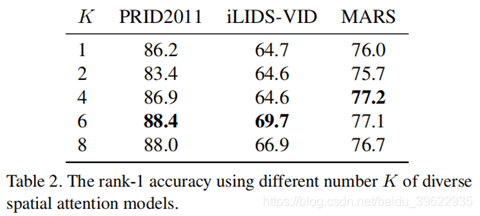
表2说明,k=6即训练6个空间注意力模型效果最好。作者还通过实验发现,对于人体,分成2个空间注意力区域反而不如1个。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号