

| Source File | Total Lines | Source Code Lines | Source Code Lines [%] | Comment Lines | Comment Lines[%] | Blank Lines | Blank Lines[%] |
|---|---|---|---|---|---|---|---|
| Expr.java | 82 | 76 | 0.926829268292683 | 0 | 0.0 | 6 | 0.07317073170731707 |
| Factor.java | 106 | 96 | 0.9056603773584906 | 3 | 0.02830188679245283 | 7 | 0.0660377358490566 |
| Lexer.java | 164 | 145 | 0.8841463414634146 | 3 | 0.018292682926829267 | 16 | 0.0975609756097561 |
| MainClass.java | 127 | 113 | 0.889763779527559 | 7 | 0.05511811023622047 | 7 | 0.05511811023622047 |
| Parser.java | 115 | 25 | 0.21739130434782608 | 80 | 0.6956521739130435 | 10 | 0.08695652173913043 |
| Polynomial.java | 57 | 48 | 0.8421052631578947 | 0 | 0.0 | 9 | 0.15789473684210525 |
| SyntaxException.java | 13 | 11 | 0.8461538461538461 | 0 | 0.0 | 2 | 0.15384615384615385 |
| Term.java | 85 | 80 | 0.9411764705882353 | 1 | 0.011764705882352941 | 4 | 0.047058823529411764 |
| UnknownTokenException.java | 14 | 12 | 0.8571428571428571 | 0 | 0.0 | 2 | 0.14285714285714285 |
| WordAttr.java | 8 | 7 | 0.875 | 0 | 0.0 | 1 | 0.125 |
| Total: | 771 | 613 | 0.795071335927367 | 94 | 0.1219195849546044 | 64 | 0.08300907911802853 |
代码复杂度
包复杂度
| package | v(G)avg | v(G)tot |
|---|---|---|
| lex | 2.5833333333333335 | 31.0 |
| mainpack | 5.25 | 21.0 |
| syntax | 3.2 | 64.0 |
| Total | 116.0 | |
| Average | 3.2222222222222223 | 38.666666666666664 |
类复杂度
| class | OCavg | OCmax | WMC |
|---|---|---|---|
| lex.Lexer | 3.4285714285714284 | 8.0 | 24.0 |
| lex.Lexer.Entry | 1.0 | 1.0 | 3.0 |
| lex.UnknownTokenException | 1.0 | 1.0 | 2.0 |
| lex.WordAttr | 0.0 | ||
| mainpack.MainClass | 4.5 | 7.0 | 18.0 |
| syntax.Expr | 4.333333333333333 | 6.0 | 13.0 |
| syntax.Factor | 3.5 | 4.0 | 14.0 |
| syntax.Parser | 1.0 | 1.0 | 2.0 |
| syntax.Polynomial | 1.2857142857142858 | 3.0 | 9.0 |
| syntax.SyntaxException | 1.0 | 1.0 | 2.0 |
| syntax.Term | 6.0 | 7.0 | 12.0 |
| Total | 99.0 | ||
| Average | 2.75 | 3.9 | 9.0 |
方法复杂度
| method | ConC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| lex.Lexer.Entry.Entry(WordAttr, Object) | 0.0 | 1.0 | 1.0 | 1.0 |
| lex.Lexer.Entry.getAttribute() | 0.0 | 1.0 | 1.0 | 1.0 |
| lex.Lexer.Entry.getValue() | 0.0 | 1.0 | 1.0 | 1.0 |
| lex.Lexer.Lexer(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| lex.UnknownTokenException.UnknownTokenException() | 0.0 | 1.0 | 1.0 | 1.0 |
| lex.UnknownTokenException.UnknownTokenException(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| syntax.Parser.Parser(Lexer) | 0.0 | 1.0 | 1.0 | 1.0 |
| syntax.Polynomial.Polynomial(BigInteger, BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| syntax.Polynomial.getCoefficient() | 0.0 | 1.0 | 1.0 | 1.0 |
| syntax.Polynomial.getIndex() | 0.0 | 1.0 | 1.0 | 1.0 |
| syntax.Polynomial.hashCode() | 0.0 | 1.0 | 1.0 | 1.0 |
| syntax.Polynomial.setCoefficient(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| syntax.Polynomial.setIndex(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| syntax.SyntaxException.SyntaxException() | 0.0 | 1.0 | 1.0 | 1.0 |
| syntax.SyntaxException.SyntaxException(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| lex.Lexer.backwards() | 1.0 | 2.0 | 1.0 | 2.0 |
| lex.Lexer.lookAhead() | 1.0 | 1.0 | 1.0 | 2.0 |
| syntax.Expr.negate(HashMap<BigInteger, Polynomial>) | 1.0 | 1.0 | 2.0 | 2.0 |
| syntax.Parser.calculate() | 1.0 | 1.0 | 2.0 | 2.0 |
| syntax.Factor.getIndex(Lexer) | 2.0 | 2.0 | 2.0 | 2.0 |
| lex.Lexer.checkDigit() | 3.0 | 3.0 | 2.0 | 3.0 |
| mainpack.MainClass.main(String[]) | 3.0 | 4.0 | 3.0 | 4.0 |
| mainpack.MainClass.print(HashMap<BigInteger, Polynomial>) | 3.0 | 1.0 | 3.0 | 3.0 |
| syntax.Factor.power(HashMap<BigInteger, Polynomial>, BigInteger) | 3.0 | 3.0 | 3.0 | 4.0 |
| lex.Lexer.checkIdentify() | 4.0 | 3.0 | 3.0 | 4.0 |
| syntax.Factor.getNum(Lexer) | 4.0 | 2.0 | 3.0 | 5.0 |
| syntax.Polynomial.equals(Object) | 4.0 | 3.0 | 3.0 | 5.0 |
| lex.Lexer.checkSymbol(char) | 5.0 | 1.0 | 2.0 | 8.0 |
| syntax.Factor.calculate(Lexer) | 5.0 | 1.0 | 4.0 | 4.0 |
| lex.Lexer.nextWord() | 7.0 | 4.0 | 5.0 | 6.0 |
| mainpack.MainClass.printCoe(BigInteger, boolean) | 7.0 | 1.0 | 4.0 | 4.0 |
| syntax.Term.calculate(Lexer) | 7.0 | 3.0 | 4.0 | 9.0 |
| syntax.Expr.calculate(Lexer) | 8.0 | 3.0 | 4.0 | 8.0 |
| mainpack.MainClass.spePrint(HashMap<BigInteger, Polynomial>) | 11.0 | 1.0 | 10.0 | 10.0 |
| syntax.Expr.addSub(boolean, HashMap<BigInteger, Polynomial>, HashMap<BigInteger, Polynomial>) | 14.0 | 1.0 | 6.0 | 6.0 |
| syntax.Term.mul(HashMap<BigInteger, Polynomial>, HashMap<BigInteger, Polynomial>) | 19.0 | 2.0 | 7.0 | 8.0 |
| Total | 113.0 | 58.0 | 89.0 | 116.0 |
| Average | 3.138888888888889 | 1.6111111111111112 | 2.4722222222222223 | 3.2222222222222223 |
代码量度分析
代码量方面除了几个枚举和异常类之外都比较平均,均在100行左右
代码复杂度方面,似乎传统的OO量度分析工具倾向使单个的类的职责更加单一,即使如词法分析这种几乎不会怎么变化的类依然给出了较高的OCavg值,但在本次作业中我不认为有什么大问题。方法复杂度方面,不出所料的lexer的nextWord具有较高圈复杂度,依然如前所述,其功能固定且较为成熟,不是大问题。其次是MainClass中的spePrint方法具有较高的设计复杂度,主要原因在于其是对指数为0、1、2的多项式的特殊处理,因而具有较高的耦合性同时一个函数完成了多项任务,也具有较复杂的控制流,但由于特判的数量不多,也不会造成太大的影响。后续作业该方法也被删除掉了。让我没有预料到的是乘法函数具有高出其他方法很多的认知复杂度,其本质就是个二重循环,可能是由于对0的处理特殊导致if嵌套了两层,在理解了对0的处理的前提下,理解mul函数应该难度不大。
类图
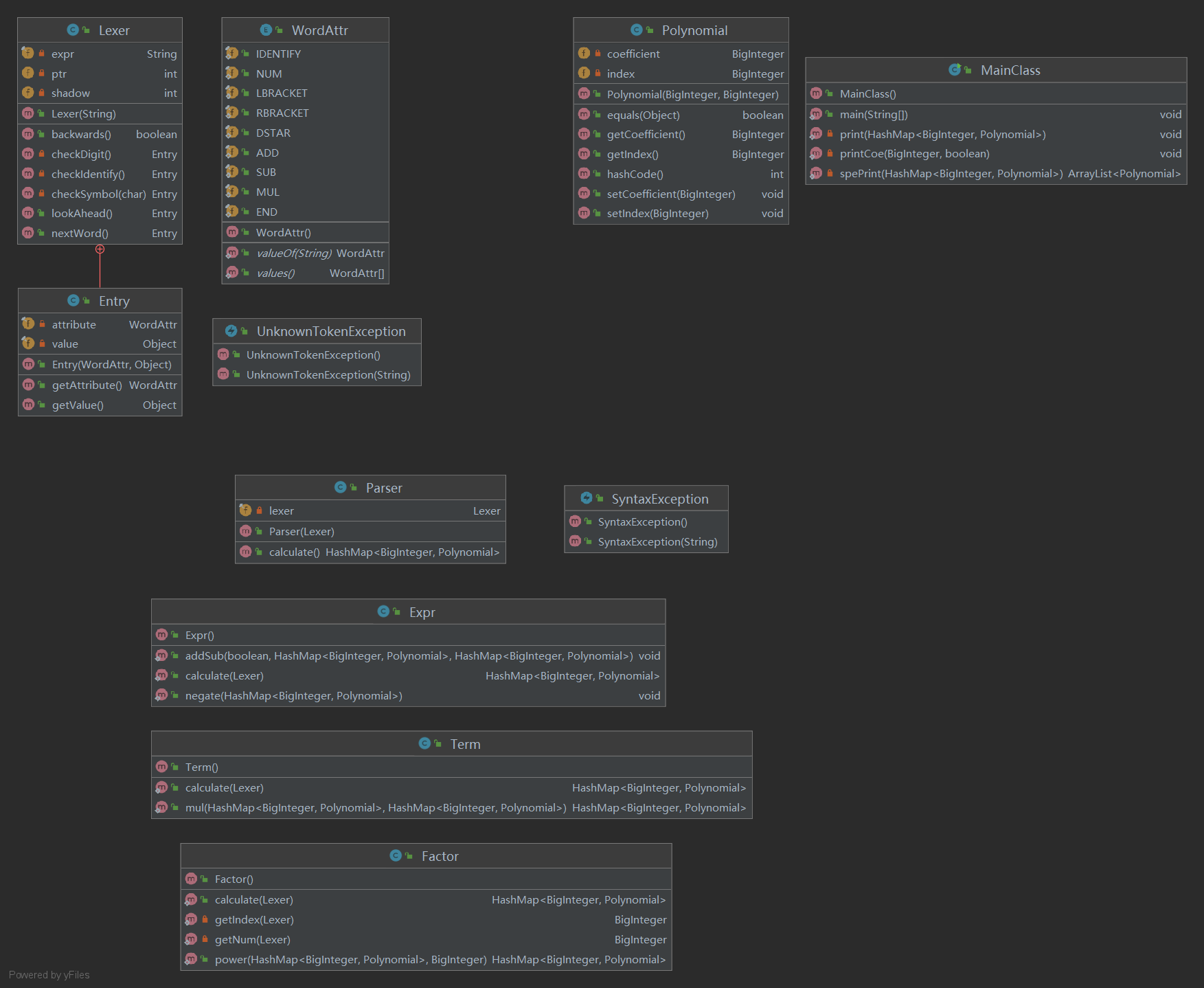
类图分析
第一次作业没有任何继承关系也没有接口,因为当时感受不到任何OO的气息,于是就按照编译的思路做了。为方便理解,类图中对相同包下或者功能相关联的类放在了一起。第二三次作业的类图也如是处理,另,与第二三次作业相同的类将不再重复说明。
图的左上角是词法分析器,内部类Entry是词法分析的结果即一个二元式,二元式的左部是类型,由WordAttr枚举类定义,有部是值,只有标识符和数字有值。同时,词法分析器遇到未定义的符号时会抛出UnknownTokenException,与之平行的,语法分析器发现语法错误时也会抛出SyntaxException。
图的下方是语法分析器,同时兼具语义分析的功能。为了降低词法分析器的复杂度,加上作业中文法的特殊性,在Parser中将Experience、Term、Fator单独抽离出来,作为工具类,同时在类中提供相应的加减、乘、乘方运算进行语义分析。
右上角是主类和结果的保存形式的元素,多项式类。此多项式类的设计有一些问题,因而在后续作业中被删掉了。最终结果的储存形式是一个HashMap,并且以多项式指数作为key,系数作为value。HashMap中各元素间以加法关系关联。后续作业沿用了这个思路,只是把HashMap换成了TreeMap,并且key不再只是指数,而是所有非系数的项组成的集合。另外,在设计中,0是不被存储了,如果要就要表示一个数字0,则用空的HashMap表示。
第二、三次作业
注:这里把两次作业放在一起是因为第三次作业和第二次几乎完全一致,只改了一下无关痛痒的地方(但是关乎格式正确性),工作量也就10行左右,没有单独放出来的必要。
代码量度
代码量
| count | Size Sum | Size Min | Size Max | Size AVG | Lines | Lines Min | Lines Max | Lines AVG | Lines CODE | |
|---|---|---|---|---|---|---|---|---|---|---|
| java | 27 | 53639 | 202 | 6501 | 1986 | 1962 | 10 | 222 | 72 | 1708 |
| Source File | Total Lines | Source Code Lines | Source Code Lines [%] | Comment Lines | Comment Lines[%] | Blank Lines | Blank Lines[%] |
|---|---|---|---|---|---|---|---|
| Add.java | 28 | 22 | 0.7857142857142857 | 0 | 0.0 | 6 | 0.21428571428571427 |
| Cos.java | 29 | 23 | 0.7931034482758621 | 0 | 0.0 | 6 | 0.20689655172413793 |
| Expr.java | 51 | 48 | 0.9411764705882353 | 0 | 0.0 | 3 | 0.058823529411764705 |
| Factor.java | 182 | 174 | 0.9560439560439561 | 0 | 0.0 | 8 | 0.04395604395604396 |
| Function.java | 48 | 40 | 0.8333333333333334 | 0 | 0.0 | 8 | 0.16666666666666666 |
| IFunc.java | 22 | 14 | 0.6363636363636364 | 0 | 0.0 | 8 | 0.36363636363636365 |
| IValue.java | 14 | 10 | 0.7142857142857143 | 0 | 0.0 | 4 | 0.2857142857142857 |
| Lexer.java | 219 | 194 | 0.8858447488584474 | 3 | 0.0136986301369863 | 22 | 0.1004566210045662 |
| MainClass.java | 63 | 58 | 0.9206349206349206 | 0 | 0.0 | 5 | 0.07936507936507936 |
| Mul.java | 28 | 22 | 0.7857142857142857 | 0 | 0.0 | 6 | 0.21428571428571427 |
| Num.java | 29 | 23 | 0.7931034482758621 | 0 | 0.0 | 6 | 0.20689655172413793 |
| Parser.java | 49 | 36 | 0.7346938775510204 | 6 | 0.12244897959183673 | 7 | 0.14285714285714285 |
| Power.java | 26 | 20 | 0.7692307692307693 | 0 | 0.0 | 6 | 0.23076923076923078 |
| PowerFunc.java | 131 | 109 | 0.8320610687022901 | 8 | 0.061068702290076333 | 14 | 0.10687022900763359 |
| Result.java | 195 | 173 | 0.8871794871794871 | 0 | 0.0 | 22 | 0.11282051282051282 |
| Sin.java | 29 | 23 | 0.7931034482758621 | 0 | 0.0 | 6 | 0.20689655172413793 |
| Sub.java | 28 | 22 | 0.7857142857142857 | 0 | 0.0 | 6 | 0.21428571428571427 |
| Sum.java | 53 | 47 | 0.8867924528301887 | 0 | 0.0 | 6 | 0.11320754716981132 |
| SyntaxException.java | 13 | 11 | 0.8461538461538461 | 0 | 0.0 | 2 | 0.15384615384615385 |
| Term.java | 44 | 40 | 0.9090909090909091 | 0 | 0.0 | 4 | 0.09090909090909091 |
| Tree.java | 50 | 40 | 0.8 | 0 | 0.0 | 10 | 0.2 |
| TrigFunc.java | 197 | 182 | 0.9238578680203046 | 0 | 0.0 | 15 | 0.07614213197969544 |
| UnknownTokenException.java | 14 | 12 | 0.8571428571428571 | 0 | 0.0 | 2 | 0.14285714285714285 |
| Util.java | 133 | 120 | 0.9022556390977443 | 1 | 0.007518796992481203 | 12 | 0.09022556390977443 |
| Utils.java | 222 | 187 | 0.8423423423423423 | 12 | 0.05405405405405406 | 23 | 0.1036036036036036 |
| Var.java | 55 | 49 | 0.8909090909090909 | 0 | 0.0 | 6 | 0.10909090909090909 |
| WordAttr.java | 10 | 9 | 0.9 | 0 | 0.0 | 1 | 0.1 |
| Total: | 1962 | 1708 | 0.8705402650356778 | 30 | 0.01529051987767584 | 224 | 0.11416921508664628 |
代码复杂度
包复杂度
| package | v(G)avg | v(G)tot |
|---|---|---|
| lex | 2.375 | 38.0 |
| mainpack | 2.111111111111111 | 38.0 |
| syntax | 4.454545454545454 | 49.0 |
| tree | 1.0 | 7.0 |
| tree.atom | 1.75 | 7.0 |
| tree.calculate | 1.7272727272727273 | 38.0 |
| tree.result | 2.4864864864864864 | 92.0 |
| Total | 269.0 | |
| Average | 2.3391304347826085 | 38.42857142857143 |
类复杂度
| class | OCavg | OCmax | WMC |
|---|---|---|---|
| lex.Lexer | 3.0 | 9.0 | 30.0 |
| lex.Lexer.Entry | 1.0 | 1.0 | 3.0 |
| lex.Lexer.FuncStruct | 1.0 | 1.0 | 1.0 |
| lex.UnknownTokenException | 1.0 | 1.0 | 2.0 |
| lex.WordAttr | 0.0 | ||
| mainpack.MainClass | 5.0 | 5.0 | 5.0 |
| mainpack.Utils | 2.6 | 10.0 | 26.0 |
| mainpack.Utils.FuncInfo | 1.0 | 1.0 | 5.0 |
| mainpack.Utils.UtilException | 1.0 | 1.0 | 2.0 |
| syntax.Expr | 5.0 | 5.0 | 5.0 |
| syntax.Factor | 5.8 | 11.0 | 29.0 |
| syntax.Parser | 1.5 | 2.0 | 3.0 |
| syntax.SyntaxException | 1.0 | 1.0 | 2.0 |
| syntax.Term | 4.0 | 4.0 | 4.0 |
| tree.atom.Num | 1.5 | 2.0 | 3.0 |
| tree.atom.Var | 2.0 | 3.0 | 4.0 |
| tree.calculate.Add | 1.0 | 1.0 | 2.0 |
| tree.calculate.Cos | 1.5 | 2.0 | 3.0 |
| tree.calculate.Function | 1.25 | 2.0 | 5.0 |
| tree.calculate.Mul | 1.0 | 1.0 | 2.0 |
| tree.calculate.Power | 1.0 | 1.0 | 2.0 |
| tree.calculate.Sin | 1.5 | 2.0 | 3.0 |
| tree.calculate.Sub | 1.0 | 1.0 | 2.0 |
| tree.calculate.Sum | 2.0 | 3.0 | 4.0 |
| tree.calculate.Util | 3.75 | 6.0 | 15.0 |
| tree.result.PowerFunc | 1.7 | 3.0 | 17.0 |
| tree.result.Result | 1.3333333333333333 | 3.0 | 12.0 |
| tree.result.Result.Func | 2.625 | 6.0 | 21.0 |
| tree.result.TrigFunc | 3.0 | 9.0 | 30.0 |
| tree.Tree | 1.0 | 1.0 | 7.0 |
| Total | 249.0 | ||
| Average | 2.1652173913043478 | 3.3793103448275863 | 8.3 |
方法复杂度
| method | ConC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| tree.Tree.Tree(IValue, HashMap<String, TreeMap<Func, BigInteger>>) | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.Tree.setTokenTable(HashMap<String, TreeMap<Func, BigInteger>>) | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.Tree.setHead(IValue) | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.Tree.getValue() | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.Tree.getTokenTable() | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.Tree.getHead() | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.Tree.changeTokenTable(String, TreeMap<Func, BigInteger>) | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.result.TrigFunc.TrigFunc(String, BigInteger, TreeMap<Func, BigInteger>) | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.result.TrigFunc.setIndex(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.result.TrigFunc.print() | 4.0 | 1.0 | 6.0 | 6.0 |
| tree.result.TrigFunc.hashCode() | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.result.TrigFunc.getIndex() | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.result.TrigFunc.getFuncName() | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.result.TrigFunc.equalsExcIndex(IFunc) | 8.0 | 7.0 | 3.0 | 8.0 |
| tree.result.TrigFunc.equals(Object) | 4.0 | 4.0 | 2.0 | 5.0 |
| tree.result.TrigFunc.compareTo(IFunc) | 21.0 | 9.0 | 5.0 | 9.0 |
| tree.result.TrigFunc.clone() | 1.0 | 1.0 | 2.0 | 2.0 |
| tree.result.Result.setFunc(Func) | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.result.Result.setCoefficient(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.result.Result.Result(BigInteger, Func) | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.result.Result.Result(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.result.Result.hashCode() | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.result.Result.getFunc() | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.result.Result.getCoefficient() | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.result.Result.Func.setFactors(TreeSet |
0.0 | 1.0 | 1.0 | 1.0 |
| tree.result.Result.Func.multiply(Func) | 12.0 | 4.0 | 5.0 | 6.0 |
| tree.result.Result.Func.hashCode() | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.result.Result.Func.getFactors() | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.result.Result.Func.Func(TreeSet |
0.0 | 1.0 | 1.0 | 1.0 |
| tree.result.Result.Func.Func(Integer) | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.result.Result.Func.equals(Object) | 7.0 | 6.0 | 3.0 | 7.0 |
| tree.result.Result.Func.compareTo(Func) | 4.0 | 4.0 | 2.0 | 4.0 |
| tree.result.Result.equals(Object) | 4.0 | 3.0 | 3.0 | 5.0 |
| tree.result.Result.compareTo(Result) | 1.0 | 2.0 | 1.0 | 2.0 |
| tree.result.PowerFunc.setIndex(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.result.PowerFunc.print() | 1.0 | 1.0 | 2.0 | 2.0 |
| tree.result.PowerFunc.PowerFunc(String, BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.result.PowerFunc.hashCode() | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.result.PowerFunc.getIndex() | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.result.PowerFunc.getBaseName() | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.result.PowerFunc.equalsExcIndex(IFunc) | 3.0 | 3.0 | 2.0 | 4.0 |
| tree.result.PowerFunc.equals(Object) | 4.0 | 3.0 | 3.0 | 5.0 |
| tree.result.PowerFunc.compareTo(IFunc) | 2.0 | 3.0 | 2.0 | 3.0 |
| tree.result.PowerFunc.clone() | 1.0 | 1.0 | 2.0 | 2.0 |
| tree.calculate.Util.trigFunc(String, TreeMap<Func, BigInteger>) | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.calculate.Util.generalPower(TreeMap<Func, BigInteger>, BigInteger) | 3.0 | 3.0 | 2.0 | 4.0 |
| tree.calculate.Util.generalMultiply(TreeMap<Func, BigInteger>, TreeMap<Func, BigInteger>) | 17.0 | 1.0 | 6.0 | 6.0 |
| tree.calculate.Util.generalAddSub(TreeMap<Func, BigInteger>, TreeMap<Func, BigInteger>, IAddSub) | 8.0 | 1.0 | 4.0 | 4.0 |
| tree.calculate.Sum.Sum(BigInteger, BigInteger, Tree) | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.calculate.Sum.getValue() | 2.0 | 2.0 | 2.0 | 3.0 |
| tree.calculate.Sub.Sub(IValue, IValue) | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.calculate.Sub.getValue() | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.calculate.Sin.Sin(IValue) | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.calculate.Sin.getValue() | 1.0 | 2.0 | 1.0 | 2.0 |
| tree.calculate.Power.Power(IValue, BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.calculate.Power.getValue() | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.calculate.Mul.Mul(IValue, IValue) | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.calculate.Mul.getValue() | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.calculate.Function.getValue() | 1.0 | 1.0 | 2.0 | 2.0 |
| tree.calculate.Function.getTokenTable() | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.calculate.Function.getFuncName() | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.calculate.Function.Function(String, Tree, String[], IValue[]) | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.calculate.Cos.getValue() | 1.0 | 2.0 | 1.0 | 2.0 |
| tree.calculate.Cos.Cos(IValue) | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.calculate.Add.getValue() | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.calculate.Add.Add(IValue, IValue) | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.atom.Var.Var(String, BigInteger, HashMap<String, TreeMap<Func, BigInteger>>) | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.atom.Var.getValue() | 5.0 | 2.0 | 3.0 | 3.0 |
| tree.atom.Num.Num(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| tree.atom.Num.getValue() | 1.0 | 1.0 | 2.0 | 2.0 |
| syntax.Term.parse(Lexer, HashMap<String, TreeMap<Func, BigInteger>>) | 4.0 | 1.0 | 3.0 | 5.0 |
| syntax.SyntaxException.SyntaxException(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| syntax.SyntaxException.SyntaxException() | 0.0 | 1.0 | 1.0 | 1.0 |
| syntax.Parser.Parser(Lexer) | 0.0 | 1.0 | 1.0 | 1.0 |
| syntax.Parser.getTree(HashMap<String, TreeMap<Func, BigInteger>>) | 2.0 | 2.0 | 3.0 | 3.0 |
| syntax.Factor.userFunc(Lexer, String, WordAttr, HashMap<String, TreeMap<Func, BigInteger>>) | 6.0 | 5.0 | 3.0 | 6.0 |
| syntax.Factor.sumFunc(Lexer, HashMap<String, TreeMap<Func, BigInteger>>) | 7.0 | 7.0 | 2.0 | 8.0 |
| syntax.Factor.parse(Lexer, HashMap<String, TreeMap<Func, BigInteger>>) | 9.0 | 9.0 | 6.0 | 10.0 |
| syntax.Factor.getNum(Lexer) | 4.0 | 2.0 | 3.0 | 5.0 |
| syntax.Factor.getIndex(Lexer) | 2.0 | 2.0 | 2.0 | 2.0 |
| syntax.Expr.parse(Lexer, HashMap<String, TreeMap<Func, BigInteger>>) | 8.0 | 1.0 | 3.0 | 7.0 |
| mainpack.Utils.UtilException.UtilException(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| mainpack.Utils.UtilException.UtilException() | 0.0 | 1.0 | 1.0 | 1.0 |
| mainpack.Utils.toOneOpti(TreeMap<Func, BigInteger>) | 0.0 | 1.0 | 1.0 | 1.0 |
| mainpack.Utils.printCoe(BigInteger) | 4.0 | 1.0 | 3.0 | 3.0 |
| mainpack.Utils.print(TreeMap<Func, BigInteger>) | 4.0 | 1.0 | 4.0 | 4.0 |
| mainpack.Utils.print(Entry<Func, BigInteger>) | 2.0 | 2.0 | 3.0 | 3.0 |
| mainpack.Utils.optimization(TreeMap<Func, BigInteger>) | 0.0 | 1.0 | 1.0 | 1.0 |
| mainpack.Utils.oneSubOpti(TreeMap<Func, BigInteger>) | 0.0 | 1.0 | 1.0 | 1.0 |
| mainpack.Utils.halfAngelOpti(TreeMap<Func, BigInteger>) | 0.0 | 1.0 | 1.0 | 1.0 |
| mainpack.Utils.getFuncInfo(String) | 8.0 | 4.0 | 3.0 | 9.0 |
| mainpack.Utils.FuncInfo.getParam() | 0.0 | 1.0 | 1.0 | 1.0 |
| mainpack.Utils.FuncInfo.getName() | 0.0 | 1.0 | 1.0 | 1.0 |
| mainpack.Utils.FuncInfo.getBody() | 0.0 | 1.0 | 1.0 | 1.0 |
| mainpack.Utils.FuncInfo.getAttr() | 0.0 | 1.0 | 1.0 | 1.0 |
| mainpack.Utils.FuncInfo.FuncInfo(String, WordAttr, String[], String) | 0.0 | 1.0 | 1.0 | 1.0 |
| mainpack.Utils.eraseOpti(TreeMap<Func, BigInteger>) | 0.0 | 1.0 | 1.0 | 1.0 |
| mainpack.Utils.doubleAngelOpti(TreeMap<Func, BigInteger>) | 0.0 | 1.0 | 1.0 | 1.0 |
| mainpack.MainClass.main(String[]) | 6.0 | 5.0 | 5.0 | 6.0 |
| lex.UnknownTokenException.UnknownTokenException(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| lex.UnknownTokenException.UnknownTokenException() | 0.0 | 1.0 | 1.0 | 1.0 |
| lex.Lexer.nextWord() | 4.0 | 4.0 | 3.0 | 4.0 |
| lex.Lexer.lookAhead() | 1.0 | 1.0 | 1.0 | 2.0 |
| lex.Lexer.Lexer(String, HashMap<String, WordAttr>, HashMap<WordAttr, FuncStruct>) | 0.0 | 1.0 | 1.0 | 1.0 |
| lex.Lexer.Lexer(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| lex.Lexer.getFunctionTree(WordAttr) | 2.0 | 3.0 | 1.0 | 3.0 |
| lex.Lexer.getFunctionParam(WordAttr) | 1.0 | 2.0 | 1.0 | 2.0 |
| lex.Lexer.FuncStruct.FuncStruct(String, Tree, String[]) | 0.0 | 1.0 | 1.0 | 1.0 |
| lex.Lexer.Entry.getValue() | 0.0 | 1.0 | 1.0 | 1.0 |
| lex.Lexer.Entry.getAttribute() | 0.0 | 1.0 | 1.0 | 1.0 |
| lex.Lexer.Entry.Entry(WordAttr, Object) | 0.0 | 1.0 | 1.0 | 1.0 |
| lex.Lexer.checkSymbol(char) | 5.0 | 1.0 | 2.0 | 9.0 |
| lex.Lexer.checkIdentify() | 5.0 | 4.0 | 4.0 | 5.0 |
| lex.Lexer.checkDigit() | 3.0 | 3.0 | 2.0 | 3.0 |
| lex.Lexer.backwards() | 1.0 | 2.0 | 1.0 | 2.0 |
| Total | 204.0 | 199.0 | 194.0 | 269.0 |
| Average | 1.7739130434782608 | 1.7304347826086957 | 1.6869565217391305 | 2.3391304347826085 |
代码量度分析
代码量上主要词法分析器和工具类占有100+至200-左右的行数,其他大多是一些接口的实现类因而比较分散、行数平均且较少。依然如第一次作业所述,词法与语法分析较为固定,因而多个方法间较紧的耦合无伤大雅,至于Util、Utils工具类只是把一些功能类似但是有没有依赖关系的静态方法放在一起,行数多自然而然。
复杂度方面,语法分析的Factor和Term类以及Util工具类给出了较高的平均操作复杂度,原因不必再赘述了。方法复杂度方面,Util里的乘法方法和三角函数实现类的compareTo有很高的认知复杂度,对于前者,其来源于第一次作业的Term类中的mul方法,原因已经说过了。而后者的确会让人难以理解,本质就在于循环嵌套关系的存在必然导致compareTo要有循环依赖关系,这也是其基本圈复杂度高的原因。直观上,因为expression可以表示为多个term的和,term又是系数与不定个函数(幂函数、三角函数)的乘积,三角函数内部可以嵌套表达式。于是,在没有了解文法关系的情况下,对于直接追溯compareTo函数会陷入循环。事实上,该递归(所谓的循环)是会停止的,因为表达式不是无限长的,三角函数内部总会有出现不含三角函数的表达式,此时compareTo函数将停止递归并逐层返回。其实对于有递归思想的读者来说,理解compareTo并不困难。equals类别的方法和compareTo类似,因此具有较高的基本圈复杂度的原因类似。至于如何降低该复杂度,我目前没有什么好的想法,毕竟递归的依赖关系就摆在那。除去equlas和compareTo类型的方法,还有Factor的parse方法和sumFunc、userFunc方法有较高的基本圈复杂度。前者在于为了识别不同的fator而在switch里有大量的case,但是由于各个case间是独立的,因而只需要确保各自的正确性即可,不会造成指数级的测试复杂度增长。后者是因为要判断读入字符串是否符合语法,所以对于终结符要一个一个地if判断,因而被认为有高复杂度,实际上去掉这些判断后原方法就很平凡了。至于Utils类的getFuncInfo方法也没什么好说的了,与sumFunc类似,其本质一个正则表达式就解决问题了。
类图
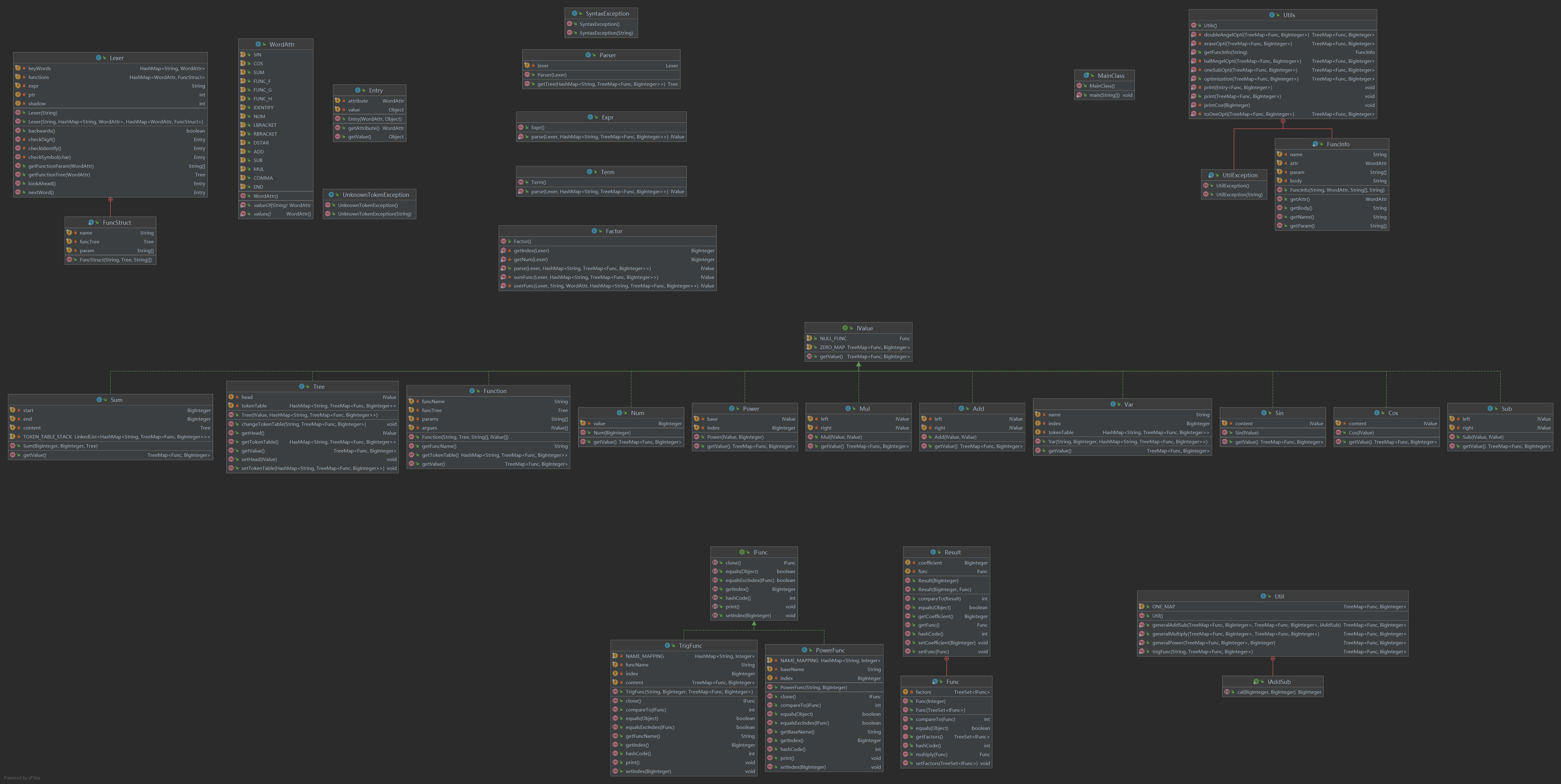
类图分析
请先看第一次作业的类图分析。
第二、三次作业里词法分析器还是在左上角,语法分析器被移到了中间上部,其实Expr、Term、Factor类都可以作为Parser类的方法,但是由于历史遗留问题(雾,我没有改动。右上角则是主类和Utils工具类,该工具类把原来在主类中的print类型的方法抽离出来,并加入了预处理自定义函数定义的getFuncInfo方法,在发现自定义函数定义语法错误时会抛出UtilException,无误则返回FuncInfo的打包数据。另外,其还包括各种优化函数(虽然我都没实现)。中间部分则是表达树,各个节点都实现了IValue接口用于getValue。为了解决函数调用问题,每一个表达式树的非常数叶子节点在getValue时都会查询该树对应的唯一的符号表,并发回查询结果,若查询结果为空,则返回自身对应的结果形式。结果形式指的是以Func类为key,以系数为value的TreeMap。IValue的实现类中Tree较为不同,它只是简单得对一个表达式树和其对应的符号表进行了绑定,没有进行其他实质性的操作。左下角是最终结果表达形式的元素,即最终结果表达为TreeMap<Func,BigInteger>。Func即为各个基本的函数的集合(set),这些基本函数函数实现了IFunc接口,Func则以IFunc类型为元素储存各个基本函数,Func的集合中元素以乘法关系关联。即Func仅含一个字段,该字段为TreeSet
bug分析
第一单元在第三次互测中被hack了一个点,其他测试没有发现bug。被hack的点在于最终的输出格式错误,其原因在于待打印的集合中混入了系数为0的元素,导致‘+’没有打印,即出现了如下的输出结果
sin(x)0 // wrong format
sin(x)+0 // right format
之所以混入了系数为0的元素,是因为在对sum函数进行计算替换i时,忘记特殊判定i为0的情况。i为0时理应在符号表对应位置填上一个空的集合。由于第二次互测不允许出现sum,第二、三次作业我又没测(去看os了,逃)才导致这个bug隔了近两周才被发现。
bug的Hack策略
第一次作业时没有建表达式树,于是写了一个测评机以建树的方式来测试,所以第一次的hack策略就是利用测评机自动化测试,结果一个bug也没有找到,全房无伤。
第二三次作业没有更新测评机,毕竟我把架构改成了显式建树,所以对正确性抱有很大的信心(没想到还是有疏忽)。由于我本人并不喜欢看别人写的代码,所以hack基本就是随便交了两个自己认为可能有坑的数据,结果是两次互测各刀中一刀。
架构设计体验
第一次作业在架构上主要就是先解析表达式然后去括号的过程。解析表达式方面就是个完完全全的语法分析,解析表达式肯定最先想到算符优先分析,但是由于作业中文法诡异的二义性,导致'+'与'-'必须要区分单目与双目,否则算符优先关系有大量冲突,而且即使区分了单双目,依然会有一点冲突,必须稍微修改一下文法。个人觉得有些麻烦(而且从某位学长那里得知编译实验大家都是用LL(k)文法),于是选择了递归下降(应该不会有大佬直接LR(1)吧)。至于去括号,就是一个递归的过程。我采用一个统一的形式存储最终结果,并且把原子单位(数字,幂函数等)也表示成这种形式,所有的运算函数都接收这种形式的参数,并返回这种形式的结果。这也是是我第一次作业没有建树的原因,语法分析完成的同时语义分析也完成了,没必要建树。
但是由于第二次作业开始出现自定义函数,显式建树就显得十分必要。一是函数解析和最终的表达式解析可以共用语法分析,因而也就很轻松地支持了函数定义中含有其他已定义的函数。二是显式建树十分有利于实参的带入,只需要对原子元素建立一个符号表,带入实参只需要把实参的结果填入符号表时即可。同时为了支持形参模式(即原样返回原子元素)需判断符号表对应位置是否非空,为空则表示该元素原样返回,非空则返回实参亦即符号表中对应位置的结果。从隐式的语法语义分析同时进行到显示地先语法后语义的改变花了我不少时间,当时属实是没想到还会自定义函数这种操作,看来OO还是要牺牲一部分的运行时间来保证易拓展性,即使你目前完全可以不牺牲运行时间,但谁又能保证未来没有大变动呢。
至于第三次作业和第二次作业变动不大,只是允许了更深层次的嵌套,因而架构完全没有变化。个人架构还支持三角函数内直接嵌套表达式而不是表达式因子,以及函数定义时含有其他已定义函数的调用,以及sum函数的嵌套。
心得体会
由于个人之前曾学习过一些面向对象的思想,并且也用C++编写过一些千行级的程序,因而觉得第一单元的作业并不是很难,出现的问题大多是不够熟悉JAVA语言的问题,java相较于C++虽然在垃圾回收以及指针处理等方面安全且方便了不少但同时也带来了诸多限制,尤其是枚举类只能一个文件写一个,短短几行占一个文件实在是让人不爽。而且由于代码风格的限制,加之java没有struct关键字,为了实现一个简单的数据打包还要写一大堆的getter、setter,即使有IDEA自动生成,但看起来显得十分冗余。之前和某位同学讨论过这个问题,他给我的回答是为什么不把这个打包的数据看成一个对象。我一时语塞,心想原来还可以把它看成对象,但仔细一想,居然可以把它看成对象?打包数据就是发挥打包的作用,理应把它当作基本数据类型的级别来看待,如果想把它看作某个对象,可以另外定义一个类A,该类中含有上述的打包数据data,该类处理打包数据并进行传递等一系列操作。如果要考虑可拓展性还可以加入中间层充当接口或抽象类,这样当打包数据改变或操作改变时只需改变传递类A的实现类即可,不需要改变其他逻辑,可以类比于工厂模式或者模板模式。另外java的泛型相较于C++的模板显然是弱了太多,STL里众多精彩的操作比如traits,在java中似乎无法实现(不知反射是否能够实现)。另外缺少了宏定义感觉整个人都不好了(w
吐槽归吐槽,java还是有不少优点的,这里就不列举了。
另外,针对第一单元的作业个人感觉不是很OOP,倒是编译的味很重。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)