
Programming on C 学习笔记
目录
- include不同的声明方式有什么不同?
- if defined 与 #ifdef 有什么区别?
- undef 是怎么工作的?
- 如何利用 typedef 来定义数组?
- 枚举中,如果有个元素被赋予值,也后一个元素怎么办?
- 如何利用 typedef 来定义指针?
- typedef 怎么定义结构体?
- make 可以指定依赖关系,那么他可以指定没有关系的文件相互依赖吗?
- make 命令会不会重复编译一个没有改动的 c 程序?
- Printf 函数支持的格式,百分号前的那个字母
- %# 字符有什么用?背后接大小写又会导致什么?
- union 的初始化方法有哪些?
- volatile 关键字的作用是什么?
- argv 数组的最后一个参数的值是什么?
- 如何启用宏命令来进行调试?
- 如何利用 define 来进行更精确的调试?
- 如何通过 gcc 来控制调试?
- 如何运用 gdb 进行调试?
- 运用 gdb 进行调试的前提是什么?
- gdb 如果运行的话,会有什么特征?
- 如何通过 gdb 来查看具体的变量值?
- gdb 如何显示那些数组变量?
- 如何退出 gdb ?
- 如何给利用 gdb 给特定的变量进行赋值?
- 如何访问特定的函数的形参?
- 如何访问全局变量?
- 如何访问结构体和指针这种?
- 如何查看某个函数的源码?
- 如何查看当前的源码文件叫什么?
- 如何快速浏览下十行,还有上十行?
- 如何插入断点?
- 如何进行单步?
- 如何查看我设置的断点?
- 如何删除断点?
- 如何跟踪堆栈?
- 如何给数组或者结构体进行赋值?
- 结构体的初始化方法有几种?
- 第一种
- 第二种
- 第三种
- 第四种
- 错误的指针使用方法
- 错误的预处理方法
- restrict 关键词怎么用?
include不同的声明方式有什么不同?
#include "metric.h"
这种声明,会首先查找当前目录下是否存在 metric.h 当查找不到,才会去系统定义的头文件目录文件夹里寻找,比如 Unix 系统就默认 /usr/include 是他的头文件目录。
#include <metric.h>
这种声明,则仅会查找系统定义的头文件目录文件夹。
所以,一般 "" 这种形式,用于当前文件夹里包含的头文件,<>这种形式,用于标准头文件。
#if defined 与 #ifdef 有什么区别?
下面这段代码
#if defined (DEBUG)
...
#endif
和下面这段代码
#ifdef DEBUG
...2
#endif
做的事情是一样的。
#undef 是怎么工作的?
有时候,你需要将某个事先 defined 的东西,给取消掉,你当然可以将那句代码删除掉,但同时你也可以使用 undef 来做。
#undef name
这样的话,如果你有 #ifedf name 或者 #if defined (name) 将会判定为 FALSE
如何利用 typedef 来定义数组?
typedef char Linebuf [81];
定义了一种类型,叫做 Linebuf,这是一种含有 81 个字符的数组。
Linebuf text, inputLine;
上面的代码等同于下面
char text[81], inputLine[81];
枚举中,如果有个元素被赋予值,也后一个元素怎么办?
enum direction { up, down, left = 10, right };
编译器会这么初始化上面的枚举
up = 0 因为他出现在第一位。
down = 1 因为他出现在第二位。
left = 10 因为他已经被指定了。
right = 11 因为他前一位是 10
可见,编译器初始化枚举是根据前面那个变量的数值来做依据的。
如何利用 typedef 来定义指针?
typedef char *StringPtr;
上面的代码定义了一个指针,以后你使用下面的语句来声明,就会被编译器认为是一个指向 char 型的指针。
StringPtr buffer;
等同
char *buffer;
typedef 怎么定义结构体?
typedef struct
{
int month;
int day;
int year;
} Date;
使用上面的代码后,意味着以后你初始化结构体,只要使用 Date xxx 就行了,而不是 struct xxx
make 可以指定依赖关系,那么他可以指定没有关系的文件相互依赖吗?
make 命令会根据一个特殊的文件,叫做 makefile ,来考虑编译源代码与否。
他甚至允许你指定一个目标文件(.o)和依赖文件的关系,只要依赖文件一更新,make 命令就会自动重新编译源文件,从而产生新的目标文件。
比如说,你可以在 makefile 里指定 datefuncs.o 依赖的源文件是 datefunc.c 和头文件 date.h 然后,当你改变了 date.h 头文件后,make 会自动重新编译 datefun.c 。
这意味着,你甚至能指定跟目标文件一毛钱关系都没有的文件作为依赖,从而达到控制控制编译与否的效果。
make 命令会不会重复编译一个没有改动的 c 程序?
答案是,不会的,放心吧。
Printf 函数支持的格式,百分号前的那个字母
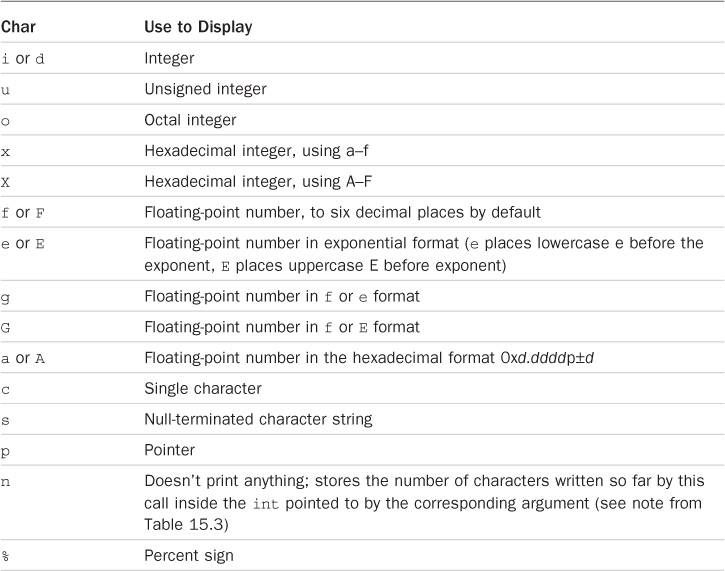
%# 字符有什么用?背后接大小写又会导致什么?
%#x 等同 0x
%#X 等同 0X
union 的初始化方法有哪些?
union mixed x = { '#' };
上面的代码,意味着,这个 union 里面,的第一个数据被初始化。
union mixed x = { .f = 123.456; };
上面的代码,意味着,union 里面的 f 元素被初始化。
void foo (union mixed x)
{
union mixed y = x;
...
}
上面的代码,是将另外一个 union 变量 x 赋予给 union 变量 y
volatile 关键字的作用是什么?
volatile 和 const 关键词是完全相反的。
他告诉编译器,这个变量是随时都可以改变的,他在程序里面的作用,主要是防止编译器优化,从而丢失某些过程。
比如,如果你有这么两条声明语句。
*outPort = 'O';
*outPort = 'N';
如果你没有将 outPort 声明为 volatile 的话,编译器会自动忽略第一句话,直接执行第二句,将他赋值为 N,然而,如果你有了 volatile ,那么他会一步步执行下去。
argv 数组的最后一个参数的值是什么?
argv 的最后一个参数,就是 argv[argc]被定义为 null
其实这就跟数组 a[5] 一样,a[5]肯定是无法访问的,否则数组就越界了。
如何启用宏命令来进行调试?
简单来说,就是使用 #ifdef 来进行调试。
直接上代码解说
#include <stdio.h>
#define DEBUG
int process (int i, int j, int k)
{
return i + j + k;
}
int main (void)
{
int i, j, k, nread;
nread = scanf ("%d %d %d", &i, &j, &k);
#ifdef DEBUG
fprintf (stderr, "Number of integers read = %i\n", nread);
fprintf (stderr, "i = %i, j = %i, k = %i\n", i, j, k);
#endif
printf ("%i\n", process (i, j, k));
return 0;
}
这代码里面,你需要注意的地方是 #define DEBUG 和 #ifdef DEBUG 这两个语句,简单来说,他的调试原理,就跟 printf 一样,只不过用了宏命令来进行控制,显得更加高大上。
ifdef 那个宏命令会判断 DEBUG 这个变量有没有被 define ,如果定义了,那么就会执行 ifdef 里面的东西。
这样做的好处是,你可以通过取消 define debug 这个语句来取消掉 ifdef 的功能,从而一步就让程序推出调试模式,想象一下,如果你使用 printf 的话,你调试完毕,需要手动的将多余的 printf 一条条删掉,你要花多少精力,而使用 ifdef 来进行调试,你只要一步就搞定删除 printf 的操作,但是实际上你是没有删掉那些 fprintf 的,所以这样做会让代码显得很乱,看着就不爽。
所以建议还是用 gdb 调试。
如何利用 define 来进行更精确的调试?
你能够更加精确的利用宏命令来进行调试,通过将 DEBUG 扩充成函数的形式。
#define DEBUG(level, fmt, ...) \
if (Debug >= level) \
fprintf (stderr, fmt, __VA_ARGS__)
上面这段代码,就是将 DEBUG 写成了函数了,他的作用是,如果 Debug 的数值比 level 大,那么就执行后续的程序,如果小,就停止,而这个 Debug 我们是在程序运行的时候通过命令行赋予的,这样就能够更加精确的控制到哪一部分的代码进行调试了。
比如,你可以这样子控制。
a.out –d1 Set debugging level to 1
a.out -d3 Set debugging level to 3
那么,当运行第一条命令的时候,比 1 小后者等于 1 的调试层级就会执行,运行第二条命令的时候,比 3 小或者等于 3 的调试层级就会执行。
所以
DEBUG (3, "number of elements = %i\n", nelems);
变成了
if (Debug >= 3)
fprintf (stderr, "number of elements = %i\n", nelems);
如何通过 gcc 来控制调试?
你甚至能够通过 gcc 命令在程序编译的时候进行调试。
gcc –D DEBUG debug.c
这等于是在编译 debug.c 的过程中,将 #define DEBUG 放入到你的程序中去。
如何运用 gdb 进行调试?
运用 gdb 进行调试的前提是什么?
你必须要在编译程序的时候,使用 gcc 的 -g 选项,-g 选项会让 C 编译器将额外的信息添加到输出文件中,包括变量和结构体类型,源文件名,还有 C 代码跟机器语言的对应关系。
gdb 如果运行的话,会有什么特征?
当 gdb 运行的时候,命令行会出现 (gdb) 的提示符
如何通过 gdb 来查看具体的变量值?
在 gdb 下,使用 print sum 可以查看 sum 变量的值。
gdb 如何显示那些数组变量?
也是直接使用 print,如果你使用 print data,那么他就会显示 data 这个数组中的所有元素,如果你想要看具体的某个数组元素,可以直接指定,比如 print data[0]
如何退出 gdb ?
直接输入 quit
需要补充说明的,如果你使用 gdb 来运行你的程序,出现有错误而暂停,那么你实际上是并没有推出 gdb 的,这个错误实际上导致了你的程序暂停了,但是并没有终止,你只有使用 quit 才会真正的退出 gdb。
如何给利用 gdb 给特定的变量进行赋值?
通过 set 命令,比如 set var i=5 是设置变量 i 等于 5
需要注意的是,使用这一招是有限制的,一般来说,这个赋值是会从当前的运行点来进行执行的。
比如说,如果你启动 gdb 调试一个项目,而没有指定具体的文件的话,那么 gdb 默认是从 main 函数里的第一句话开始的,否则,gdb 会将当前行设定为当前程序停止的地方。
如果你赋予变量的时候,gdb 在当前函数找不到这个变量,就会从全局变量里查找了。
如何访问特定的函数的形参?
你可以使用下面的语法来实行,函数名::形参,比如nima::nimei
如何访问全局变量?
file::var
这会强制 gdb 访问全局变量,并且无视掉任何函数里面相同名字的变量。
如何访问结构体和指针这种?
就跟在程序里面的语法那样用就行了,如果 datePtr 是一个指向结构体的指针,那么就使用 datePtr->year 就会打印出指向的那个结构体里面的 year 变量。
如果指向的结构体或者 union 而不指定特定的 member ,那么就会导致该结构体或者 union 下面全部的元素被打印出来。
如何查看某个函数的源码?
list foo
显示了这个源代码下的 foo 函数的所有行,如果这个函数在其他源文件,那么 gdb 自动切换到那个函数。
如何查看当前的源码文件叫什么?
使用命令 info source
如何快速浏览下十行,还有上十行?
list +
会浏览后十行
list -
会浏览前十行
如何插入断点?
将断点设置在第 12 行
break 12
将断点设置在特定函数
break main
将断点设定在某个文件的某个函数
break mod2.c:foo
设置在 mod2.c 文件中的 foo 函数
如果你想要让程序遇到断点后继续运行,可以使用 continue 命令,或者直接 c 命令。
如何进行单步?
一行行执行,并且会进入调用函数里面一行行执行的,是使用 step
一行行执行,并且会调用函数,但是不会进入函数里面一行行执行的,是使用 next
需要注意的是,当你单步完了后,gdb 会列出下一行需要执行的代码,而不是刚才执行过的代码。
如何查看我设置的断点?
info break
如何删除断点?
clear 20
移除在 20 行的断点。
如何跟踪堆栈?
backtrace 或者短一点 bt
如何给数组或者结构体进行赋值?
set var array = {100, 200}
结构体的初始化方法有几种?
第一种
struct point
{
float x;
float y;
} start = {100.0, 200.0};
第二种
struct point end = { .y = 500, .x = 200 };
第三种
struct entry
{
char *word;
char *def;
} dictionary[1000] = {
{ "a", "first letter of the alphabet" },
{ "aardvark", "a burrowing African mammal" },
{ "aback", "to startle" }
};
等同于
struct entry
{
char *word;
char *def;
} dictionary[1000] = {
[0].word = "a", [0].def = "first letter of the alphabet",
[1].word = "aardvark", [1].def = "a burrowing African mammal",
[2].word = "aback", [2].def = "to startle"
};
等同于
struct entry
{
char *word;
char *def;
} dictionary[1000] = {
{ {.word = "a", .def = "first letter of the alphabet" },
{.word = "aardvark", .def = "a burrowing African mammal"},
{.word = "aback", .def = "to startle"}
};
第四种
struct date tomorrow = today;
today 是一个赋值好的结构体。
错误的指针使用方法
必须要在声明指针的时候就给指针初始化,否则后面的初始化会出错的。
char *char_pointer;
*char_pointer = 'X';
比如这个指针的初始化就有问题了,一般这种指针叫做野指针。
错误的预处理方法
#define SQUARE(x) (x) * (x)
...
w = SQUARE (++v);
这会导致下面的运行结果
w = (++v) * (++v);
你这么写看着都难受,这写的是什么鬼?
你要知道代码你只要写一次,但是却要被读很多次,你写成这鸟样让别人怎么读,会生儿子没屁眼的。
restrict 关键词怎么用?
restrict 关键词,其实也是告诉编译器的,他表示,使用了这个关键词声明的变量,不和别人共用同一个值。
int * restrict intPtrA;
int * restrict intPtrB;
上面的 intPtrA 和 intPtrB 就不能有相同的值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号