《大话数据结构》学习笔记(1)
线性表的定义是什么?
零個或多個數據元素的有限序列。

我们对每个线性表位置的存入或者取出数据,对于计算机来说都是相等的时间,也就是一个常数,因此用我们算法中学到的时间复杂度的概念来说,它的存取时间性能为O(1)。我们通常把具有这一特点的存储结构称为随机存取结构。
線性表順序存儲結構的優缺點是什么?

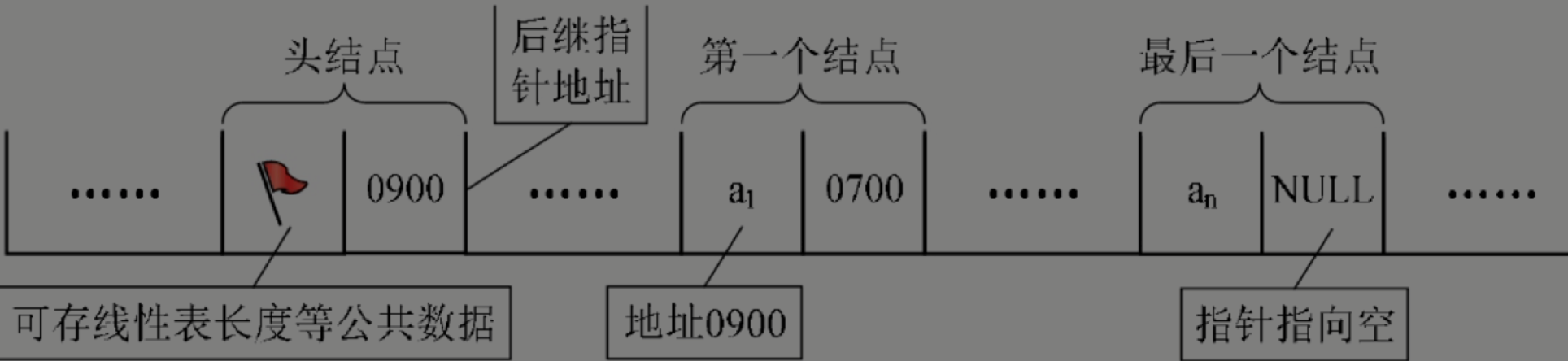
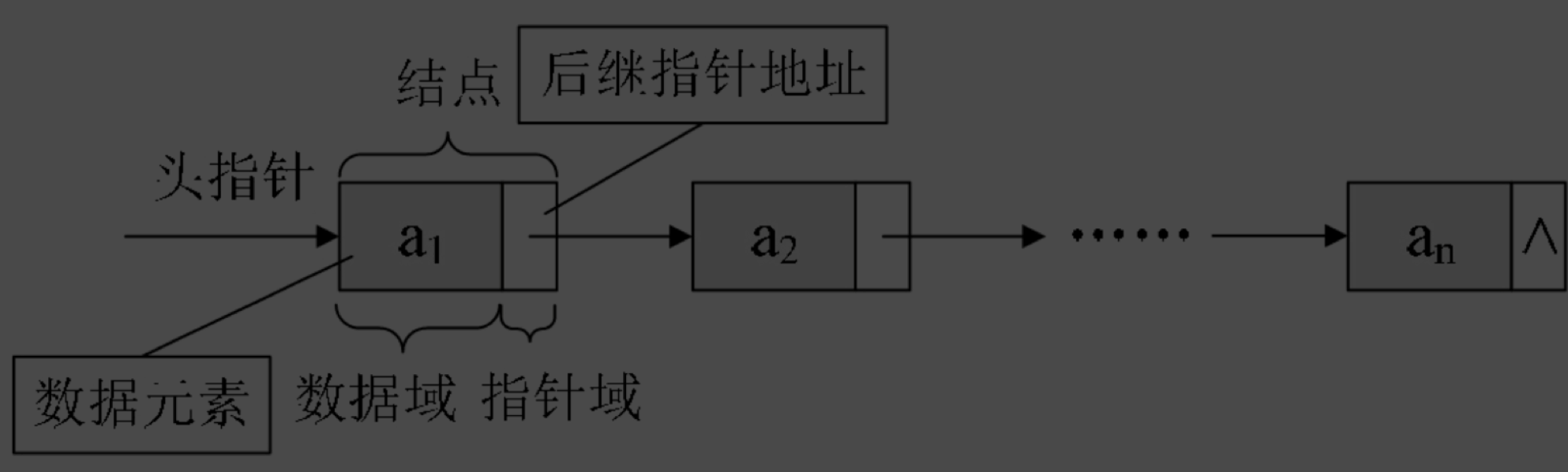
链式结构的节点是怎么构成的?
為了表示每個數據元素ai與其直接後繼數據元素ai+1之間的邏輯關系,對數據元素ai來説,除了存儲其本身的信息之外,還需存儲一個指示其直接後繼的信息(即直接後繼的存儲位置)。我們把存儲數據元素信息的域稱為數據域,把存儲直接後繼位置的域稱為指針域。指針域中存儲的信息稱做指針或鏈。這兩部分信息組成數據元素ai的存儲映像,稱為結點(Node)。
单向链表怎么图解?
更详细的
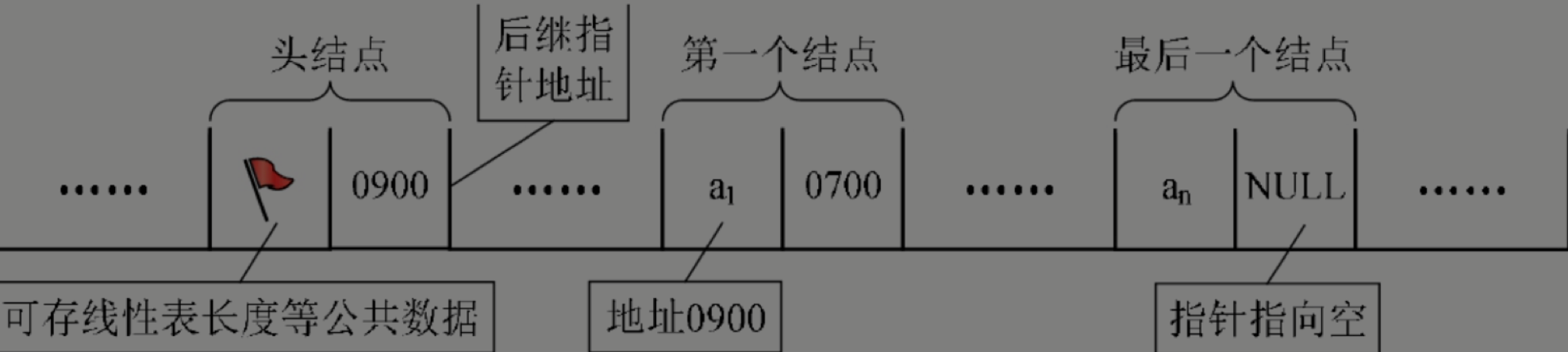
头指针和头节点的区别是什么?

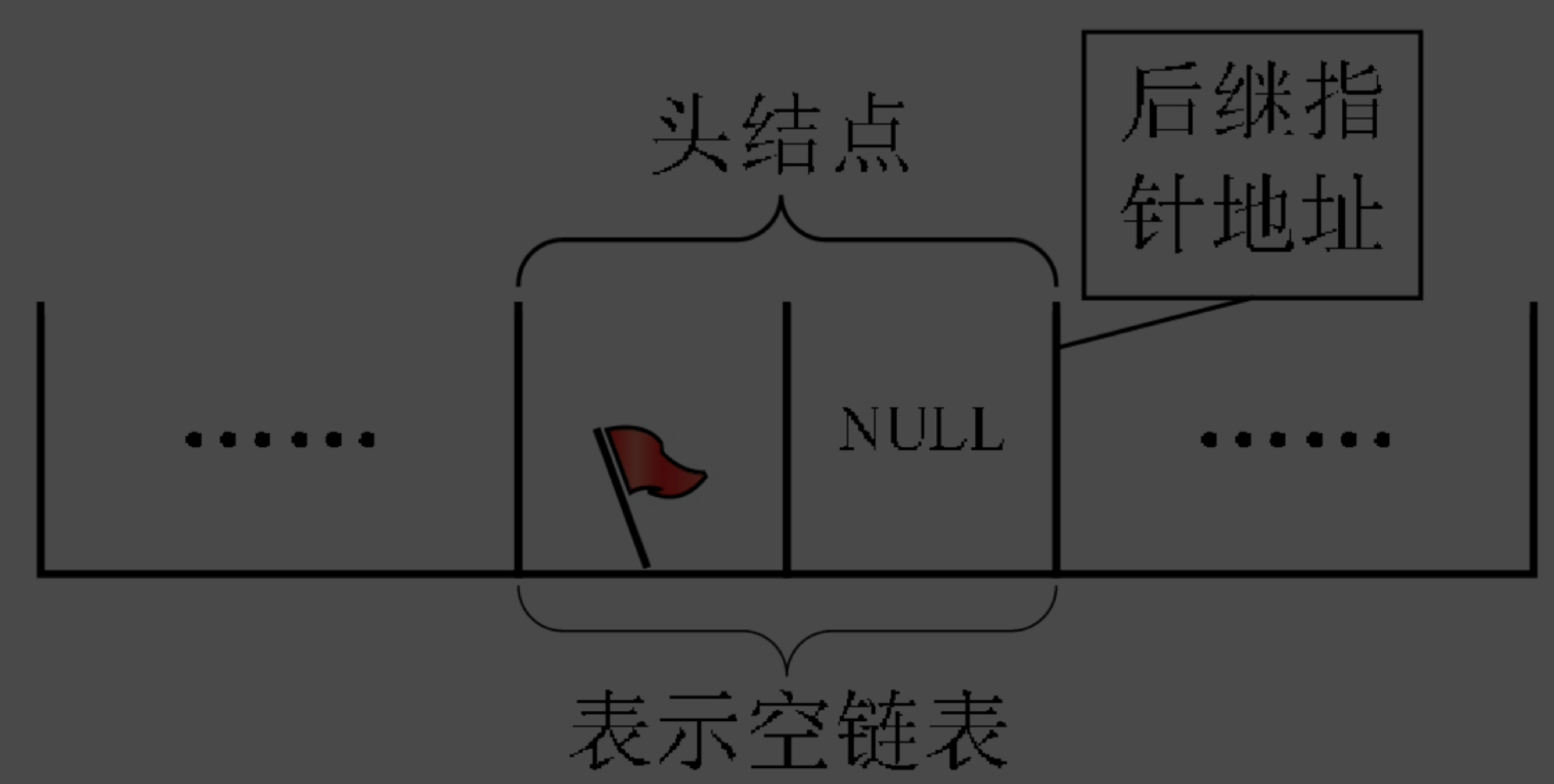
空链表是怎么回事?
线性表的顺序查找是怎么样的?
线性表的順序存儲結構中,我們要計算任意一個元素的存儲位置是很容易的。但在單鏈表中,由於第i個元素到底在哪?沒辦法一開始就知道,必須得從頭開始找。因此,對於單鏈表實現获取第i個元素的數據的操作GetElem,在算法上,相對要麻煩一些。
获得鏈表第i個數據的算法思路:
聲明一個指針p指向鏈表第一個結點,初始化j從1開始;
當j<i時,就遍历鏈表,讓p的指針向後移動,不斷指向下一結點,j纍加1;
若到鏈表末尾p為空,則説明第i個結點不存在;
否則查找成功,返回結點p的數據。
实现算法
/* 初始條件:順序線性表L已存在,1≤i≤ListLength(L) */
/* 操作結果:用e返回L中第i個數據元素的值 */
Status GetElem(LinkList L, int i, ElemType *e)
{
int j;
LinkList p; /* 聲明一指針p */
p = L->next; /* 讓p指向鏈表L的第一個結點 */
j = 1; /* j為計數器 */
while (p && j < i) /* p不為空且計數器j還沒有等於i時,循環繼續 */
{
p = p->next; /* 讓p指向下一個結點 */
++j;
}
if (!p || j > i)
return ERROR; /* 第i個結點不存在 */
*e = p->data; /* 取第i個結點的數據 */
return OK;
}
説白了,就是從頭開始找,直到第i個結點為止。由於這個算法的時間复雜度取決於i的位置,當i=1時,則不需遍历,第一個就取出數據了,而當i=n時則遍历n-1次才可以。因此最壞情況的時間复雜度是O(n)。
单链表和顺序存储结构有什么异同?
若線性表需要頻繁查找,很少進行插入和刪除操作時,宜采用順序存儲結構。若需要頻繁插入和刪除時,宜采用單鏈表結構。

静态链表的优缺点是什么?
總的來説,靜態鏈表其實是為了給沒有指針的高級語言設計的一種實現單鏈表能力的方法。

循环链表解决了什么问题?
如何從當中一個結點出发,訪問到鏈表的全部結點。
什么是循环链表?
將單鏈表中終端結點的指針端由空指針改為指向頭結點,就使整個單鏈表形成一個環,這種頭尾相接的單鏈表稱為單循環鏈表,簡稱循環鏈表(circular linked list)。
為了使空鏈表與非空鏈表處理一致,我們通常設一個頭結點,當然,這并不是説,循環鏈表一定要頭結點,這需要註意。
循環鏈表帶有頭結點的空鏈表如圖所示:

对于非空的循环链表

循环链表和单链表有什么区别?
其實循環鏈表和單鏈表的主要差異就在於循環的判斷條件上,原來是判斷p->next是否為空,現在則是p->next不等於頭結點,則循環未結束。
为什么会有双向链表?
我們在單鏈表中,有了next指針,這就使得我們要查找下一結點的時間复雜度為O(1)。可是如果我們要查找的是上一結點的話,那最壞的時間复雜度就是O(n)了,因為我們每次都要從頭開始遍历查找。
为了解决这个问题,有了双向链表。
双向链表的定义是什么?
雙向鏈表(double linked list)是在單鏈表的每個結點中,再設置一個指向其前驅結點的指針域。所以在雙向鏈表中的結點都有兩個指針域,一個指向直接後繼,另一個指向直接前驅。
雙向鏈表的循環帶頭結點的空鏈表
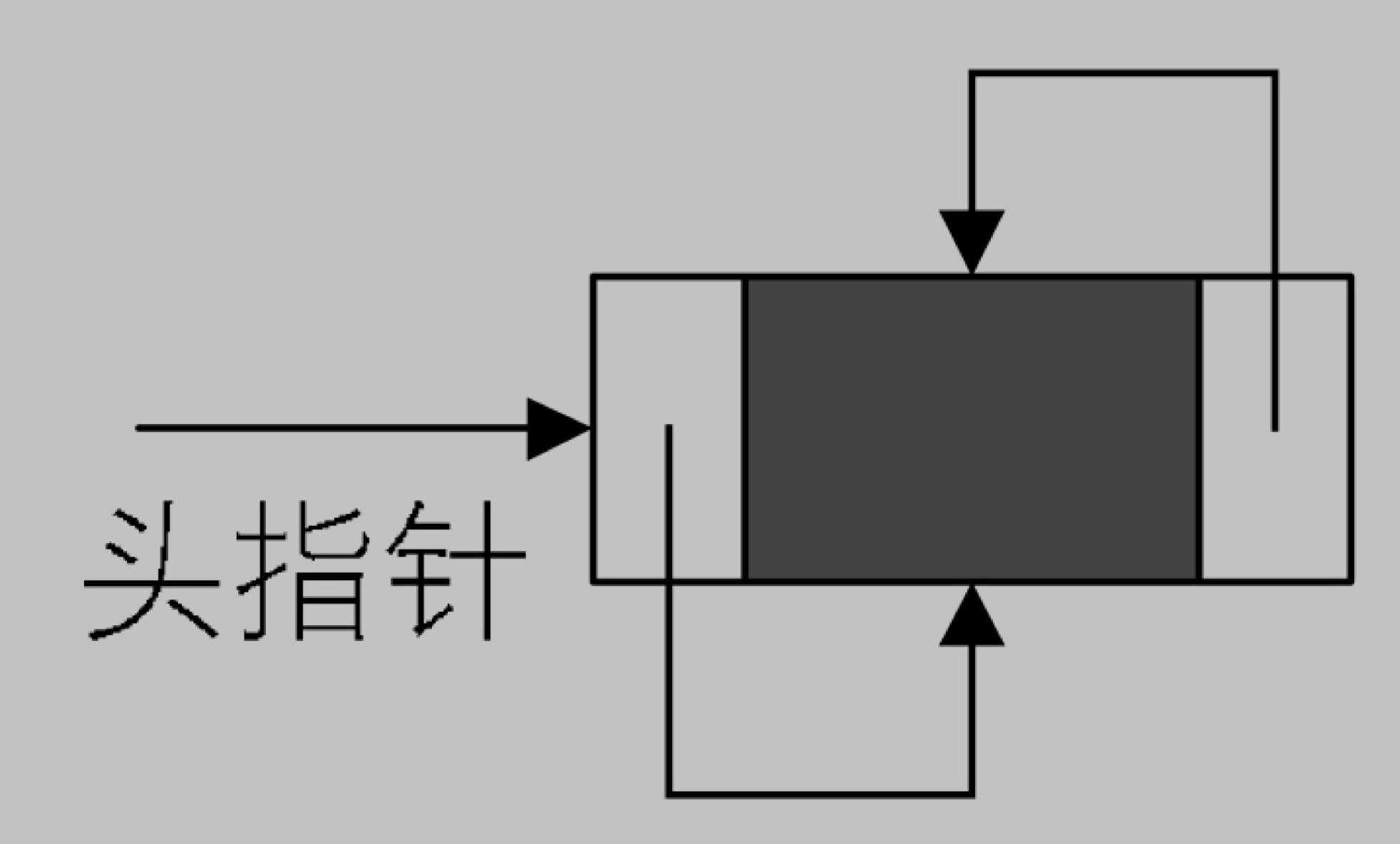
非空的循環的帶頭結點的雙向鏈表
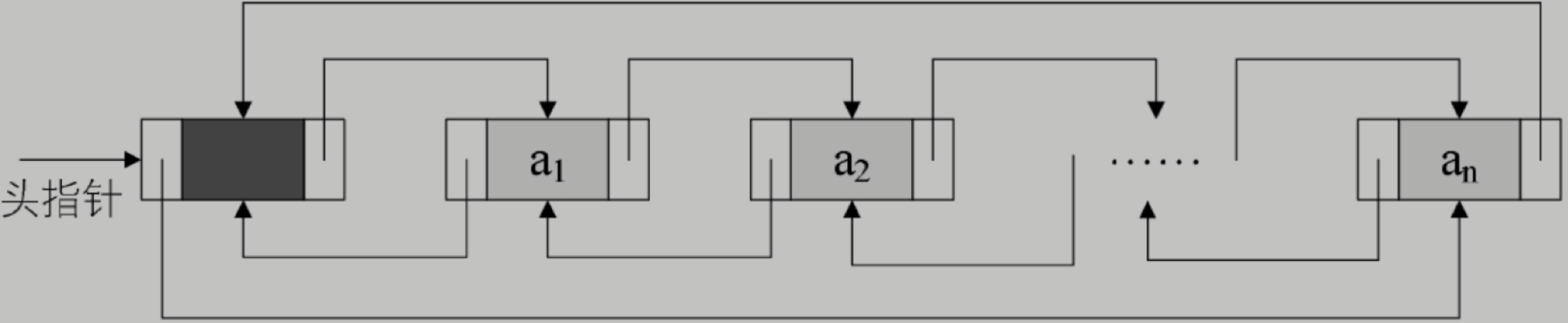
棧與隊列有什么区别?
棧是限定僅在表尾進行插入和刪除操作的線性表。
隊列是只允許在一端進行插入操作、而在另一端進行刪除操作的線性表。
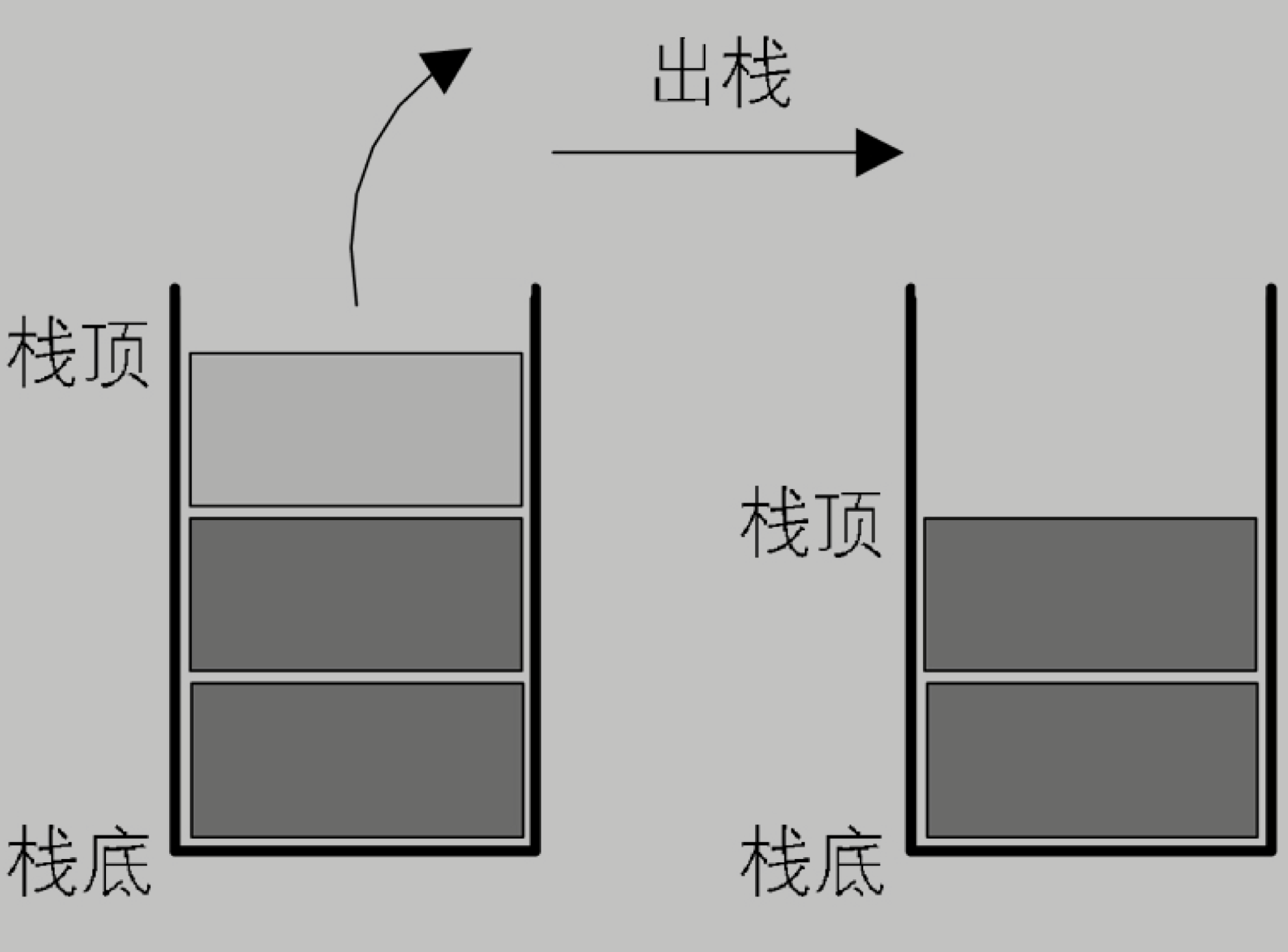
栈的定义是什么?
允許插入和刪除的一端稱為棧頂(top),另一端稱為棧底(bottom),不含任何數據元素的棧稱為空棧。棧又稱為後進先出(Last In First Out)的線性表,簡稱LIFO結構。
理解棧的定義需要註意:
首先它是一個線性表,也就是説,棧元素具有線性關系,即前驅後繼關系。只不過它是一種特殊的線性表而已。定義中説是在線性表的表尾進行插入和刪除操作,這里表尾是指棧頂,而不是棧底。
它的特殊之處就在於限制了這個線性表的插入和刪除位置,它始終只在棧頂進行。這也就使得:棧底是固定的,最先進棧的只能在棧底。
棧的插入操作,叫作進棧,也稱壓棧、入棧。類似子彈入彈夾。

棧的刪除操作,叫作出棧,也有的叫作彈棧。
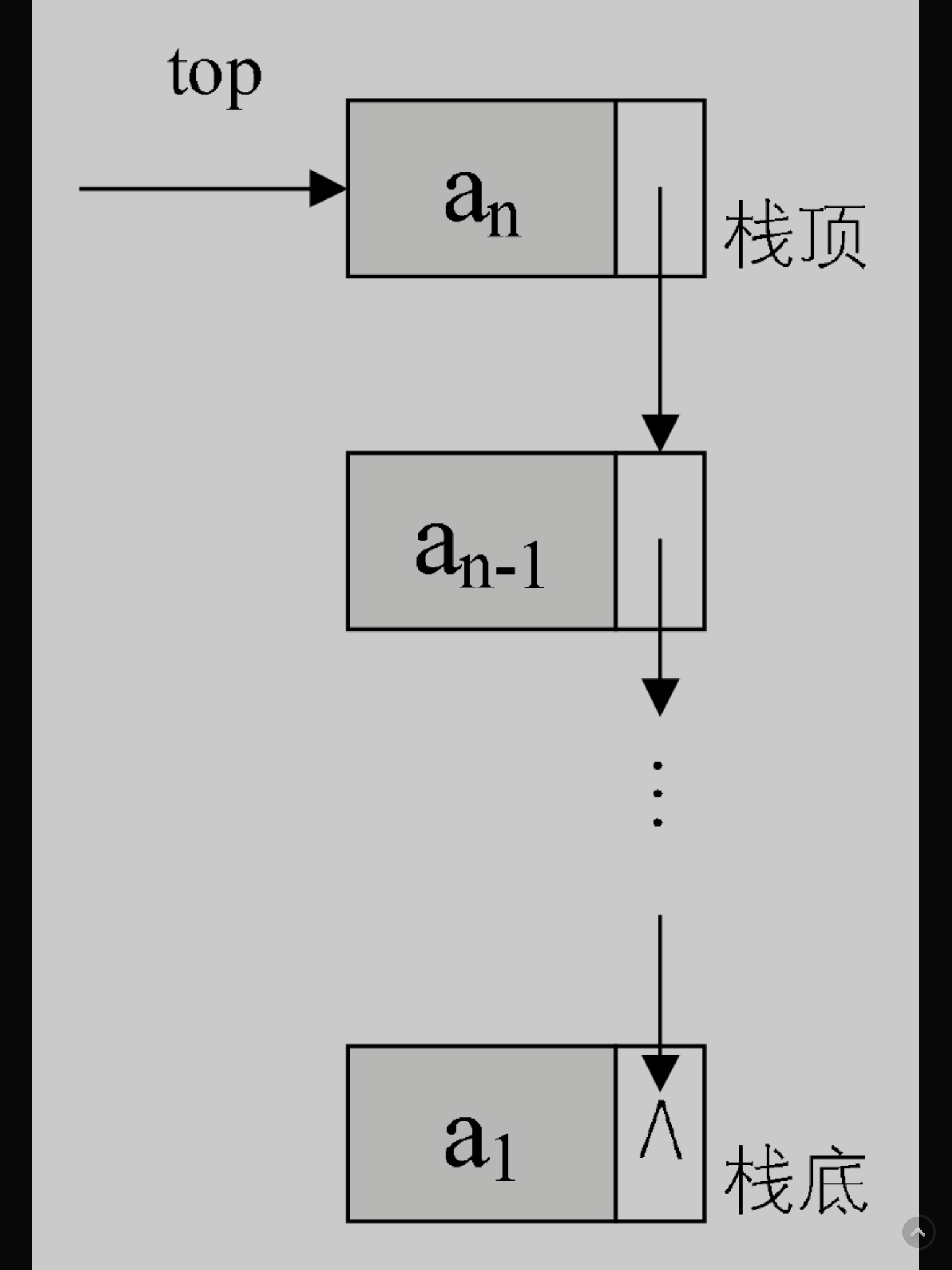
栈的链式存储结构是什么?
由於單鏈表有頭指針,而棧頂指針也是必須的,那干嗎不讓它倆合二為一呢,所以比較好的辦法是把棧頂放在單鏈表的頭部。另外,都已經有了棧頂在頭部了,單鏈表中比較常用的頭結點也就失去了意義,通常對於鏈棧來説,是不需要頭結點的。
對於鏈棧來説,基本不存在棧滿的情況,除非內存已經沒有可以使用的空間,如果真的发生,那此時的計算機操作系統已經面臨死機崩潰的情況,而不是這個鏈棧是否溢出的問題。
但對於空棧來説,鏈表原定義是頭指針指向空,那麼鏈棧的空其實就是top=NULL的時候。
顺序栈和链栈有什么异同?
對比一下順序棧與鏈棧,它們在時間复雜度上是一樣的,均為O(1)。對於空間性能,順序棧需要事先確定一個固定的長度,可能會存在內存空間浪費的問題,但它的優勢是存取時定位很方便,而鏈棧則要求每個元素都有指針域,這同時也增加了一些內存開銷,但對於棧的長度無限制。所以它們的區別和線性表中討論的一樣,如果棧的使用過程中元素變化不可預料,有時很小,有時非常大,那麼最好是用鏈棧,反之,如果它的變化在可控範圍內,建議使用順序棧會更好一些。
后缀表达式是什么?
我們先來看看,對於“9+(3-1)×3+10÷2”,如果要用後綴表示法應該是什麼樣子:“9 3 1-3*+10 2/+”,這樣的表達式稱為後綴表達式,叫後綴的原因在於所有的符號都是在要運算數字的後面出現。顯然,這里沒有了括號。
后缀表达式是给计算机用的,计算机无法理解中缀表达式。
我們把平時所用的標準四則運算表達式,即“9+(3-1)×3+10÷2”叫做中綴表達式。因為所有的運算符號都在兩數字的中間。
要想讓計算機具有處理我們通常的標準(中綴)表達式的能力,最重要的就是兩步:
-
將中綴表達式轉化為後綴表達式(棧用來進出運算的符號)。
-
將後綴表達式進行運算得出結果(棧用來進出運算的數字)。
整個過程,都充分利用了棧的後進先出特性來處理,理解好它其實也就理解好了棧這個數據結構。
队列的定义是什么?
隊列是一種先進先出(First In First Out)的線性表,簡稱FIFO。允許插入的一端稱為隊尾,允許刪除的一端稱為隊頭。
队列的两种结构的比较
線性表有順序存儲和鏈式存儲,棧是線性表,所以有這兩種存儲方式。同樣,隊列作為一種特殊的線性表,也同樣存在這兩種存儲方式。
對於循環隊列與鏈隊列的比較,可以從兩方面來考慮,從時間上,其實它們的基本操作都是常數時間,即都為O(1)的,不過循環隊列是事先申請好空間,使用期間不釋放,而對於鏈隊列,每次申請和釋放結點也會存在一些時間開銷,如果入隊出隊頻繁,則兩者還是有細微差異。對於空間上來説,循環隊列必須有一個固定的長度,所以就有了存儲元素個數和空間浪費的問題。而鏈隊列不存在這個問題,尽管它需要一個指針域,會產生一些空間上的開銷,但也可以接受。所以在空間上,鏈隊列更加靈活。
總的來説,在可以確定隊列長度最大值的情況下,建議用循環隊列,如果你無法預估隊列的長度時,則用鏈隊列。
串的定义是什么
串(string)是由零個或多個字符組成的有限序列,又名叫字符串。
关于串的常识有哪些?
串中的字符數目n稱為串的長度,定義中談到“有限”是指長度n是一個有限的數值。
零個字符的串稱為空串(null string),它的長度為零,可以直接用兩雙引號“""”表示,也可以用希臘字母“Φ”來表示。
所謂的序列,説明串的相鄰字符之間具有前驅和後繼的關系。
空格串,是只包含空格的串。註意它與空串的區別,空格串是有內容有長度的,而且可以不止一個空格。
子串與主串,串中任意個數的連續字符組成的子序列稱為該串的子串,相應地,包含子串的串稱為主串。
子串在主串中的位置就是子串的第一個字符在主串中的序號。
串是如何比较的?
事實上,串的比較是通過組成串的字符之間的編碼來進行的,而字符的編碼指的是字符在對應字符集中的序號。
关于树的常识
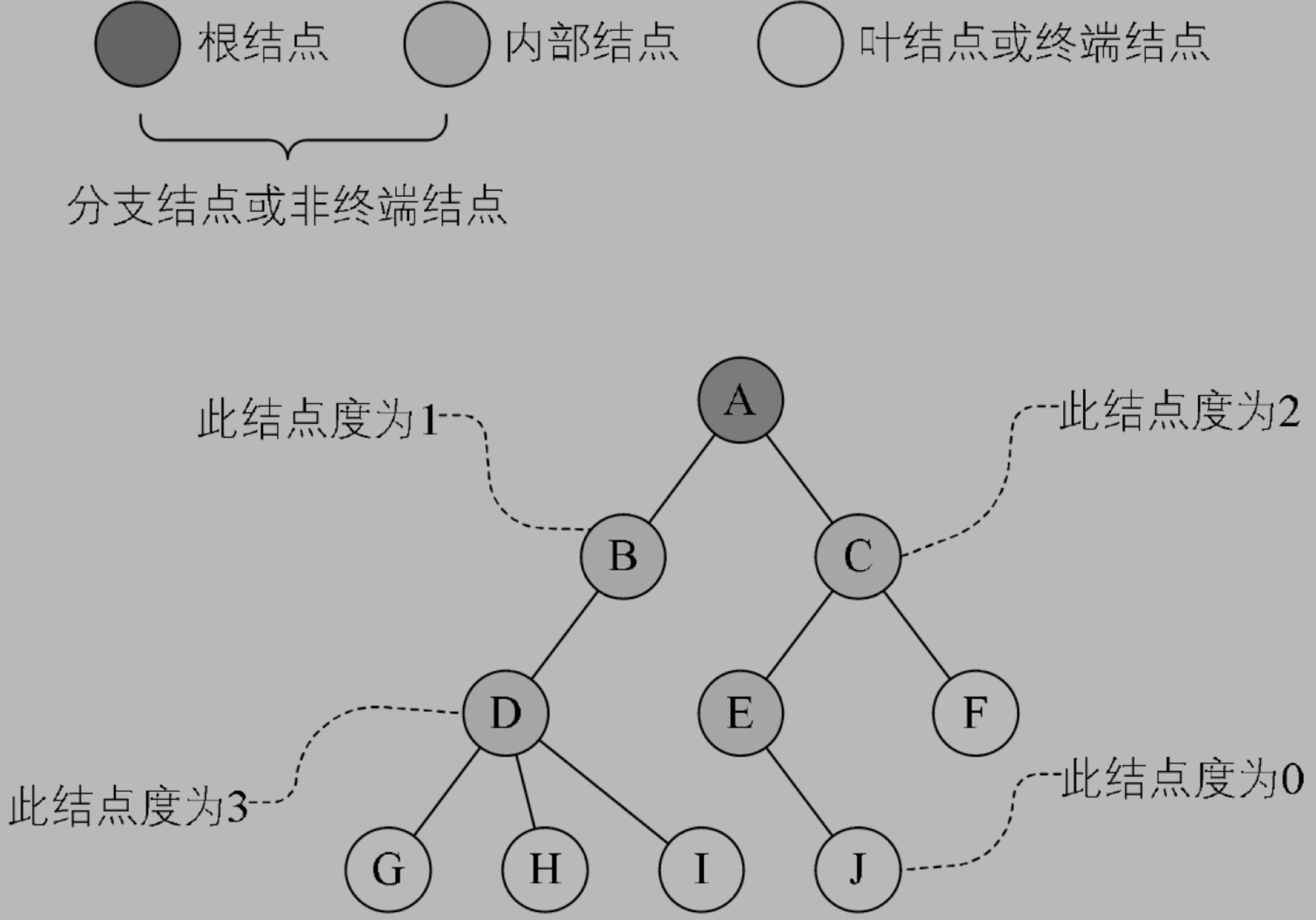
樹的度是樹內各結點的度的最大值。上图所示,因為這棵樹結點的度的最大值是結點D的度,為3,所以樹的度也為3。
如果將樹中結點的各子樹看成從左至右是有次序的,不能互換的,則稱該樹為有序樹,否則稱為無序樹。
树的每个节点的度,就是这个节点的孩子个数。
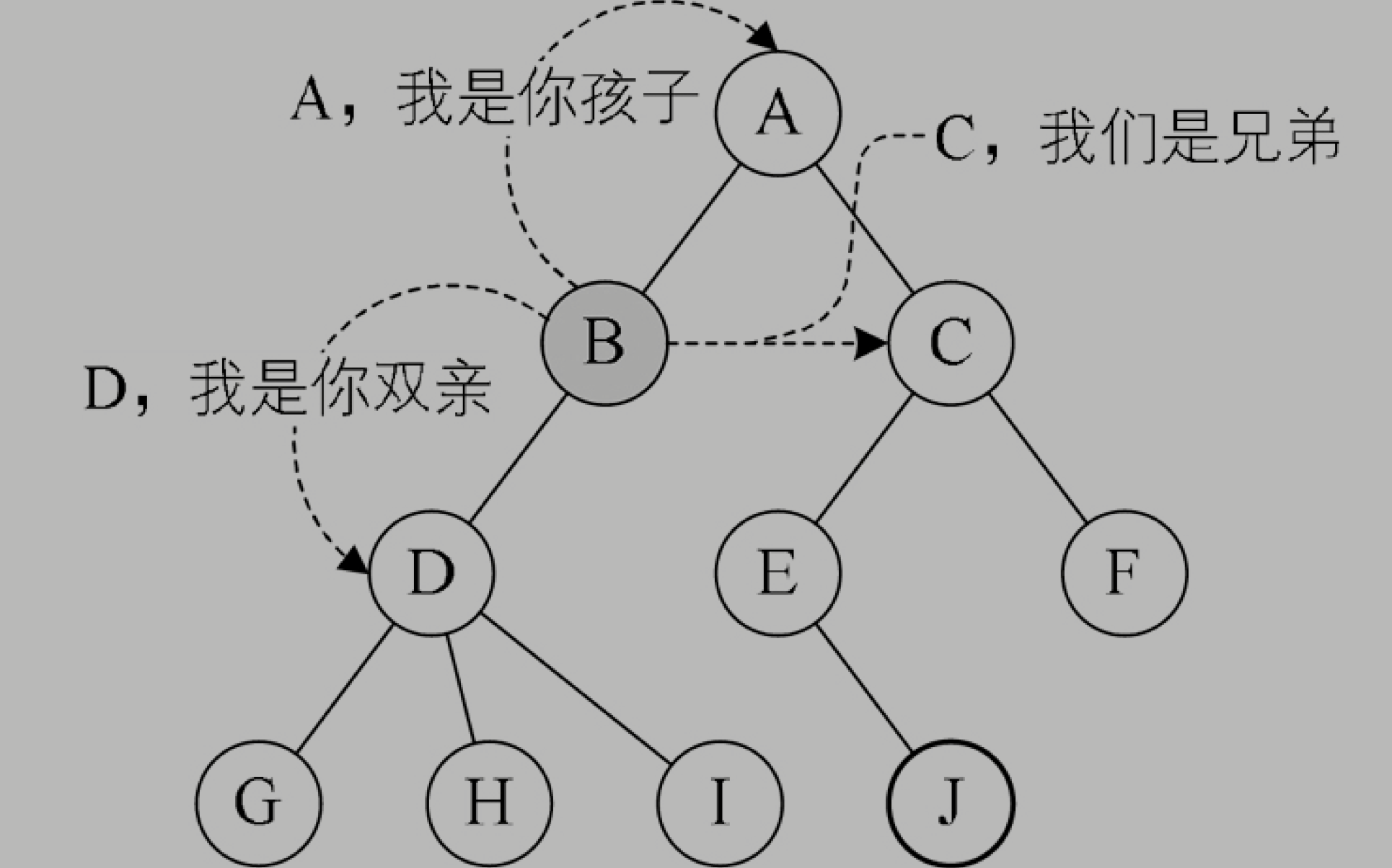
线性表与树的对比

长子域
我們假設以一組連續空間存儲樹的結點,同時在每個結點中,附設一個指示器指示其雙親結點在數組中的位置。也就是説,每個結點除了知道自己是誰以外,還知道它的雙親在哪里。
data | parent
其中data是數據域,存儲結點的數據信息。而parent是指針域,存儲該結點的雙親在數組中的下標。
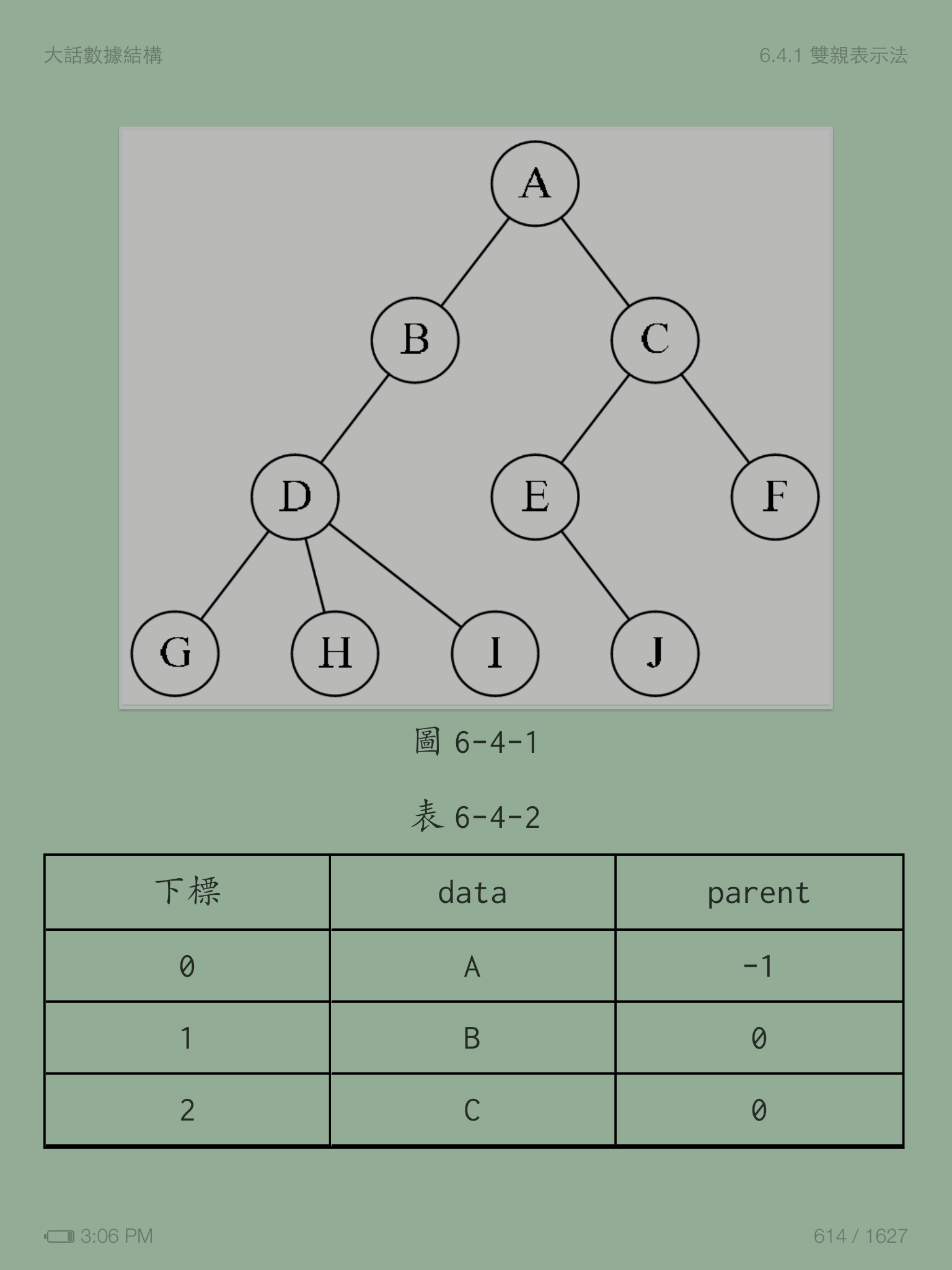
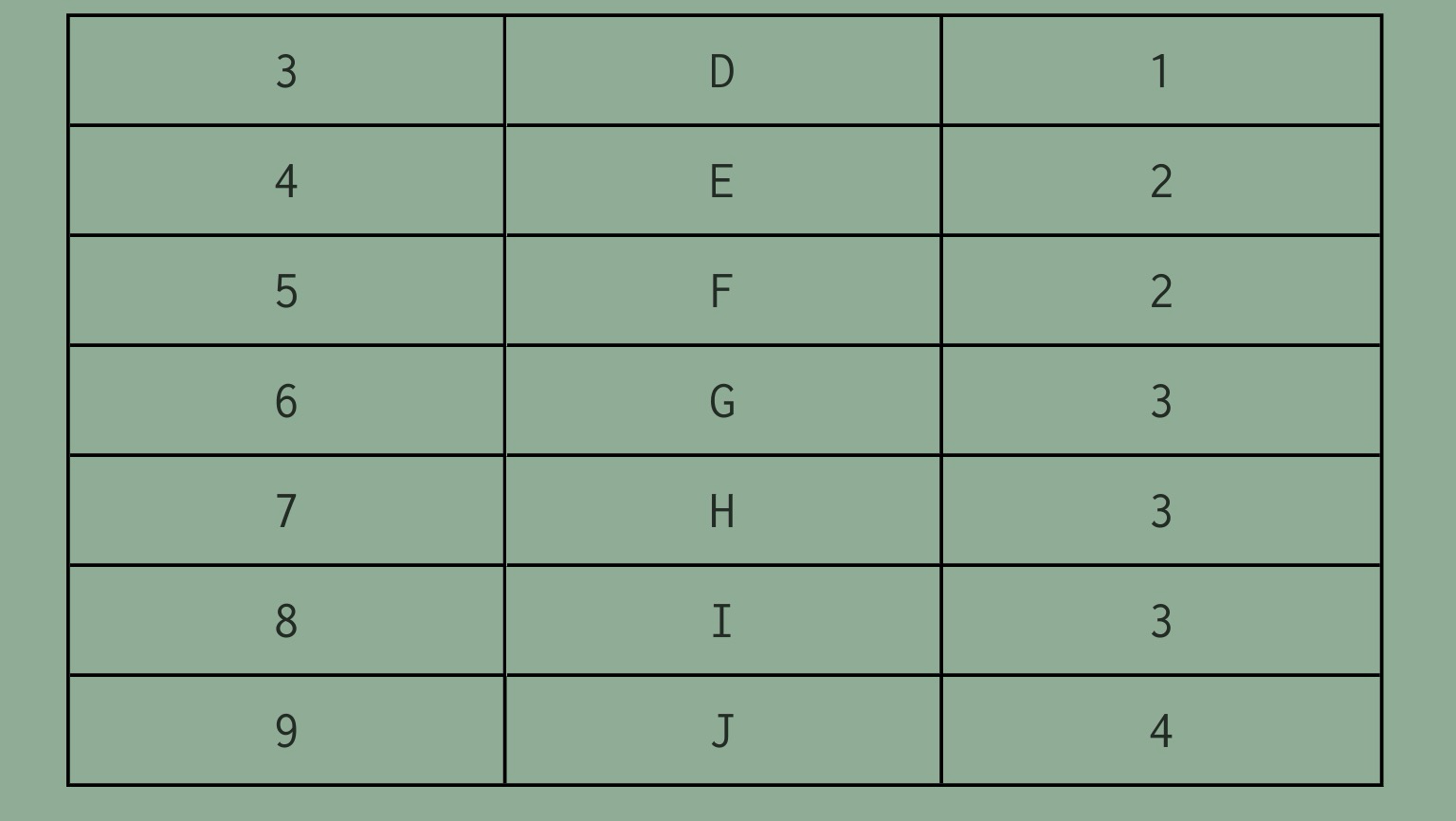
這樣的存儲結構,我們可以根據結點的parent指針很容易找到它的雙親結點,所用的時間复雜度為O(1),直到parent為-1時,表示找到了樹結點的根。
还可以设置长子域。
如果沒有孩子的結點,這個長子域就設置為-1
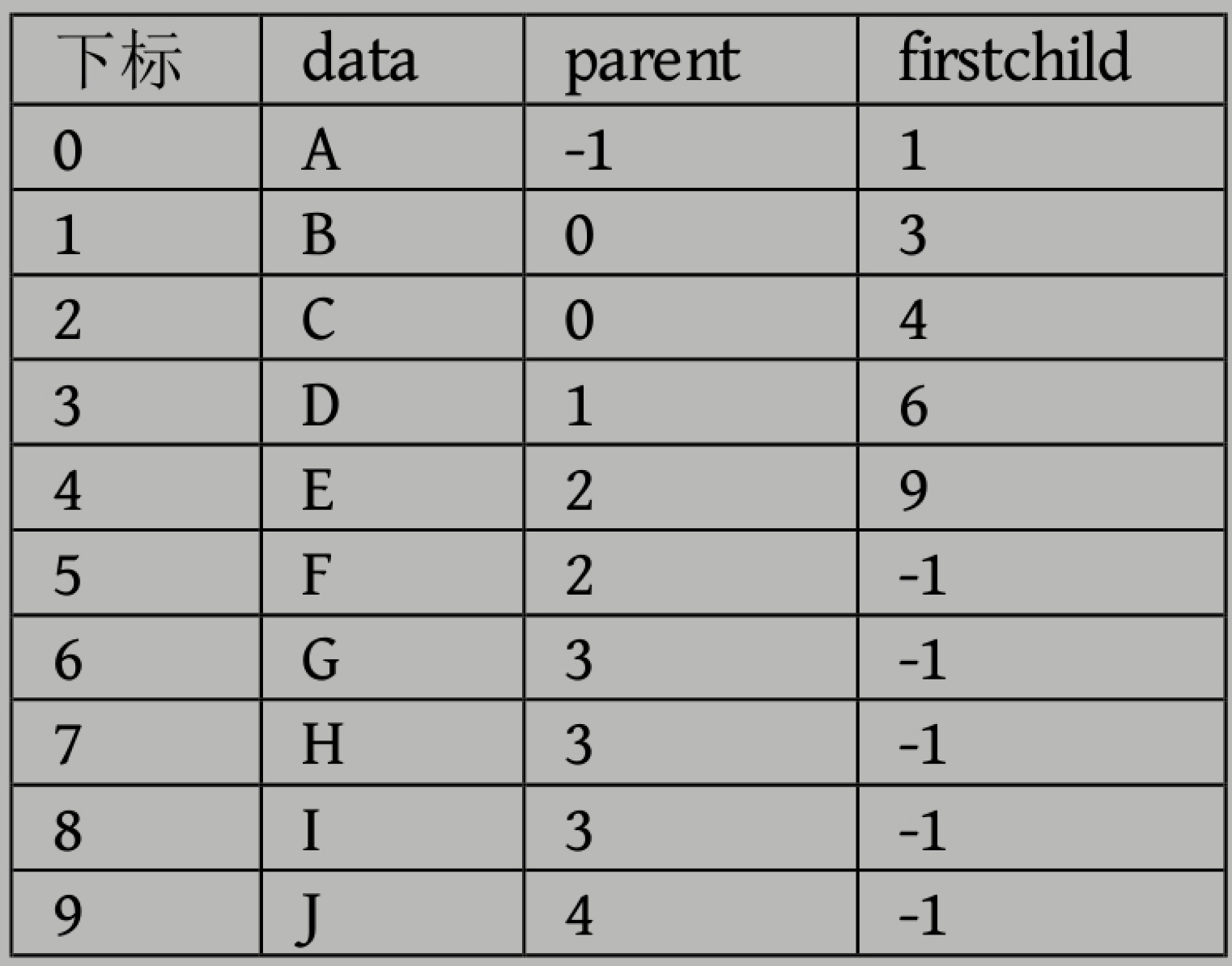
还可以增加,右兄弟域,通过那个节点就能知道兄弟在哪里
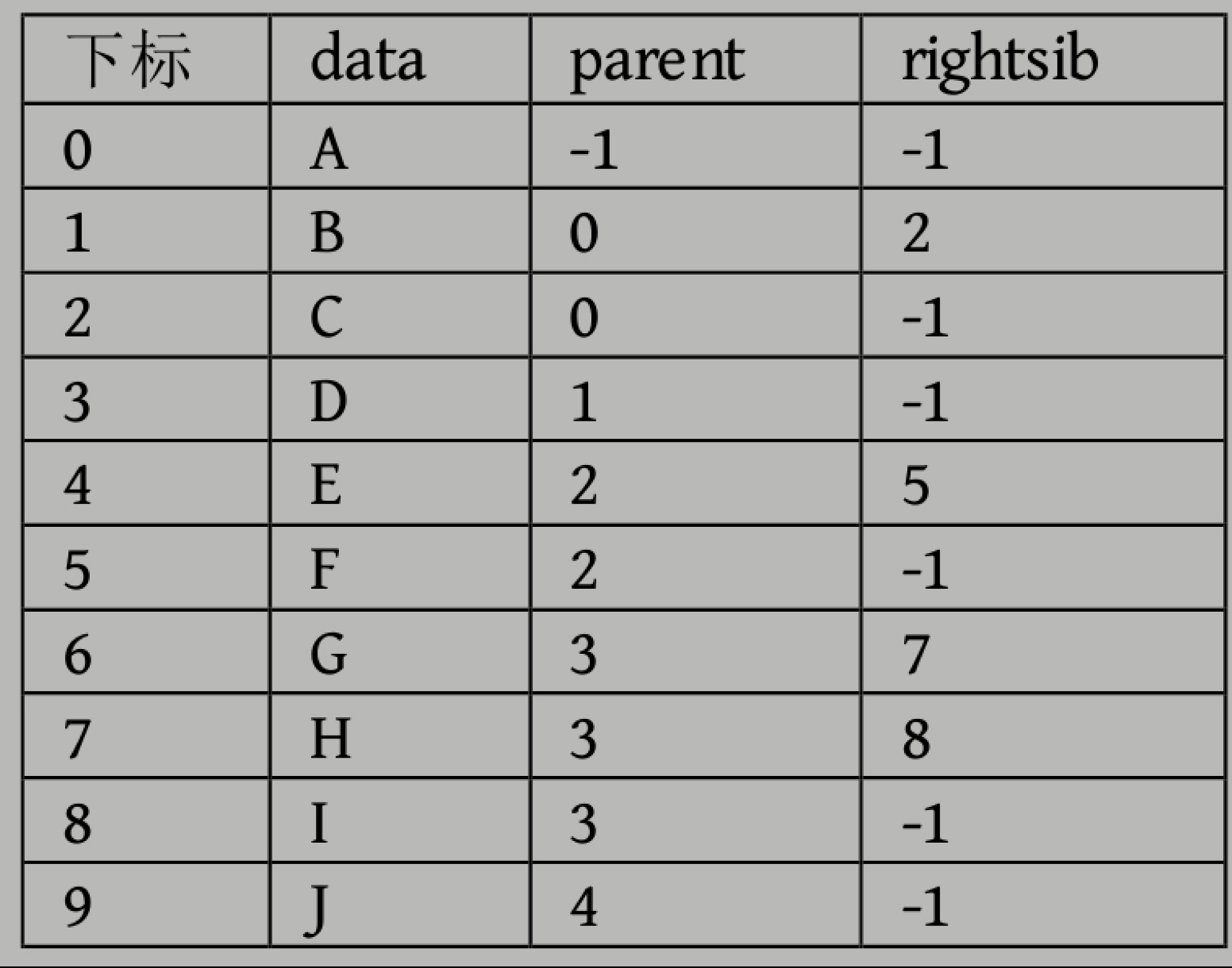
存儲結構的設計是一個非常靈活的過程。一個存儲結構設計得是否合理,取決於基於該存儲結構的運算是否適合、是否方便,時間复雜度好不好等。
二叉树的特点是什么?
每個結點最多有兩棵子樹,所以二叉樹中不存在度大於2的結點。註意不是只有兩棵子樹,而是最多有。沒有子樹或者有一棵子樹都是可以的。
左子樹和右子樹是有順序的,次序不能任意顛倒。就像人有雙手、雙腳,但顯然左手、左腳和右手、右腳是不一樣的,右手戴左手套、右腳穿左鞋都會极其別扭和難受。
即使樹中某結點只有一棵子樹,也要區分它是左子樹還是右子樹。下圖中,樹1和樹2是同一棵樹,但它們卻是不同的二叉樹。就好像你一不小心,摔傷了手,傷的是左手還是右手,對你的生活影響度是完全不同的。

特殊二叉树之斜树是什么树?
顧名思義,斜樹一定要是斜的,但是往哪斜還是有講究。所有的結點都只有左子樹的二叉樹叫左斜樹。所有結點都是只有右子樹的二叉樹叫右斜樹。這兩者統稱為斜樹。
斜樹有很明顯的特點,就是每一層都只有一個結點,結點的個數與二叉樹的深度相同。
有人會想,這也能叫樹呀,與我們的線性表結構不是一樣嗎。對的,其實線性表結構就可以理解為是樹的一種极其特殊的表現形式。
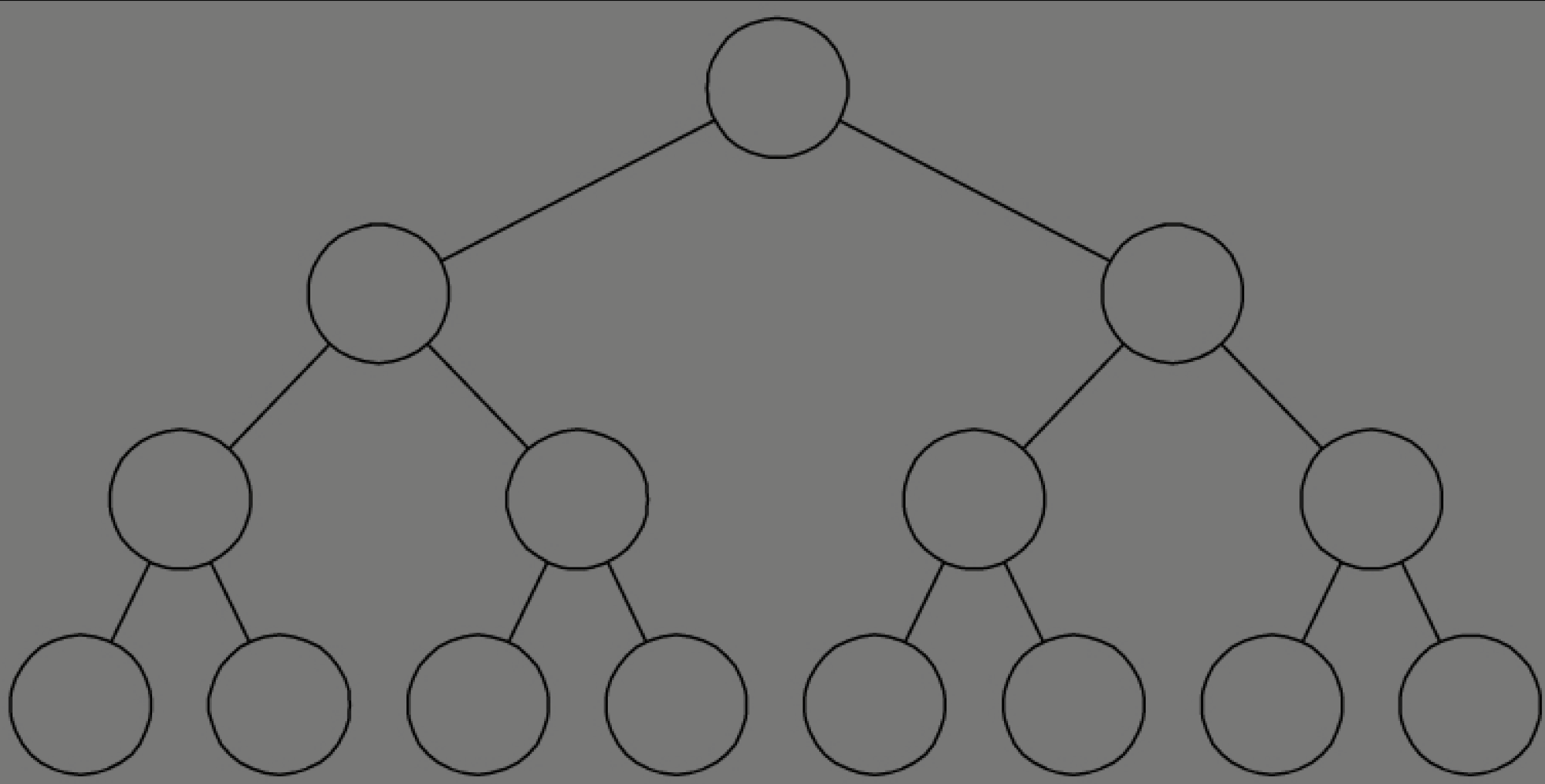
特殊二叉树之满二叉树是怎么一回事?
滿二叉樹的特點有:
(1)葉子只能出現在最下一層。出現在其他層就不可能達成平衡。
(2)非葉子結點的度一定是2。否則就是“缺胳膊少腿”了。
(3)在同樣深度的二叉樹中,滿二叉樹的結點個數最多,葉子數最多。
完全二叉树的特点是什么?
這是一種有些理解難度的特殊二叉樹。
首先從字面上要區分,“完全”和“滿”的差異,滿二叉樹一定是一棵完全二叉樹,但完全二叉樹不一定是滿的。
其次,完全二叉樹的所有結點與同樣深度的滿二叉樹,它們按層序編號相同的結點,是一一對應的。這里有個關鍵詞是按顺序編號,按照满二叉树的顺序来编号,如果那个位置空了,也要编上。
完全二叉樹的特點:
(1)葉子結點只能出現在最下兩層。
(2)最下層的葉子一定集中在左部連續位置。
(3)倒數二層,若有葉子結點,一定都在右部連續位置。
(4)如果結點度為1,則該結點只有左孩子,即不存在只有右子樹的情況。
(5)同樣結點數的二叉樹,完全二叉樹的深度最小。
完全二叉树的判断方法是什么?
看著樹的示意圖,心中默默給每個結點按照滿二叉樹的結構逐層順序編號,如果編號出現空檔,就説明不是完全二叉樹,否則就是。
例如
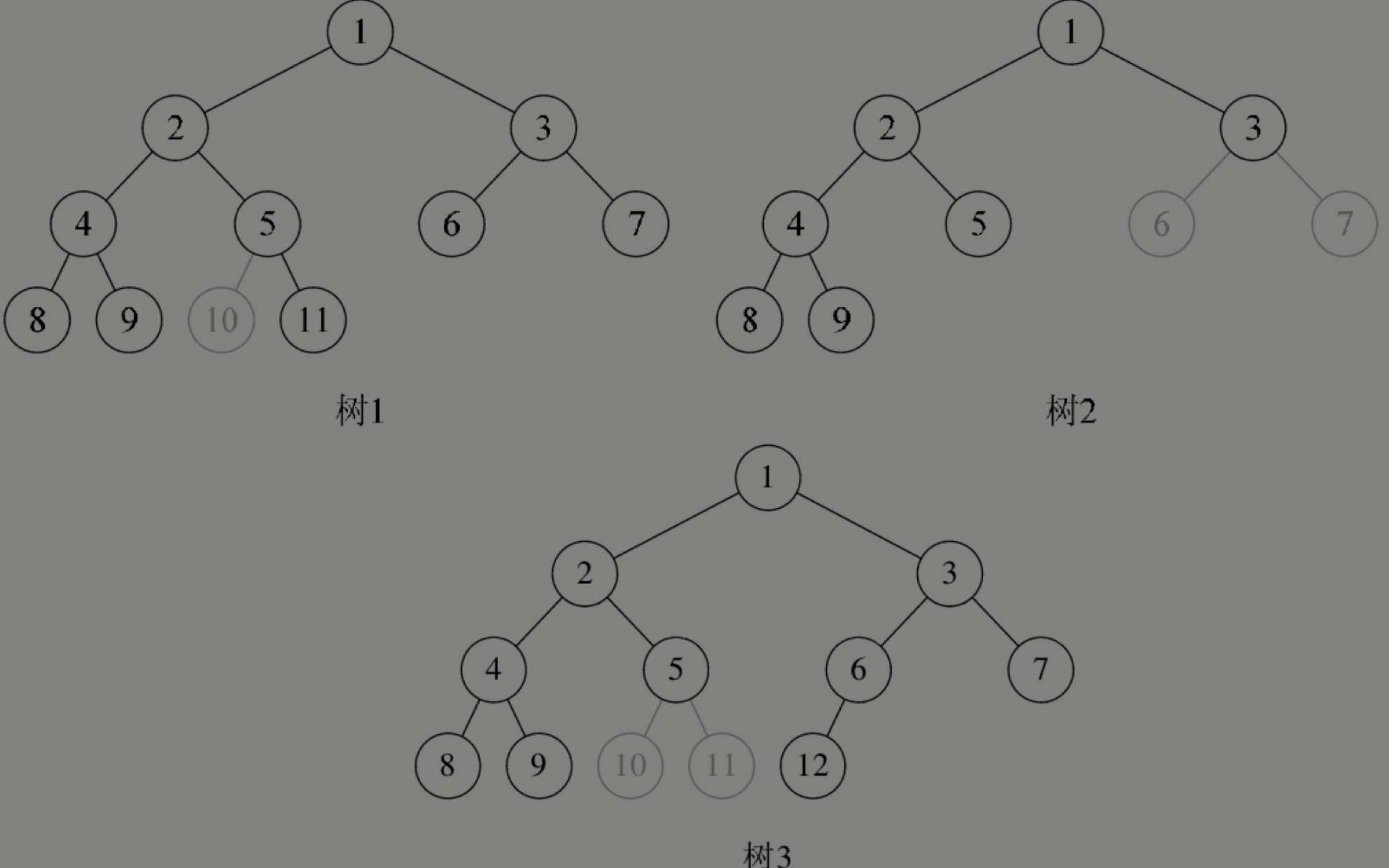
像上圖中的樹1,因為5結點沒有左子樹,卻有右子樹,那就使得按層序編號的第10個編號空檔了。同樣道理,圖中的樹2,由於3結點沒有子樹,所以使得6、7編號的位置空檔了。圖中的樹3又是因為5編號下沒有子樹造成第10和第11位置空檔。
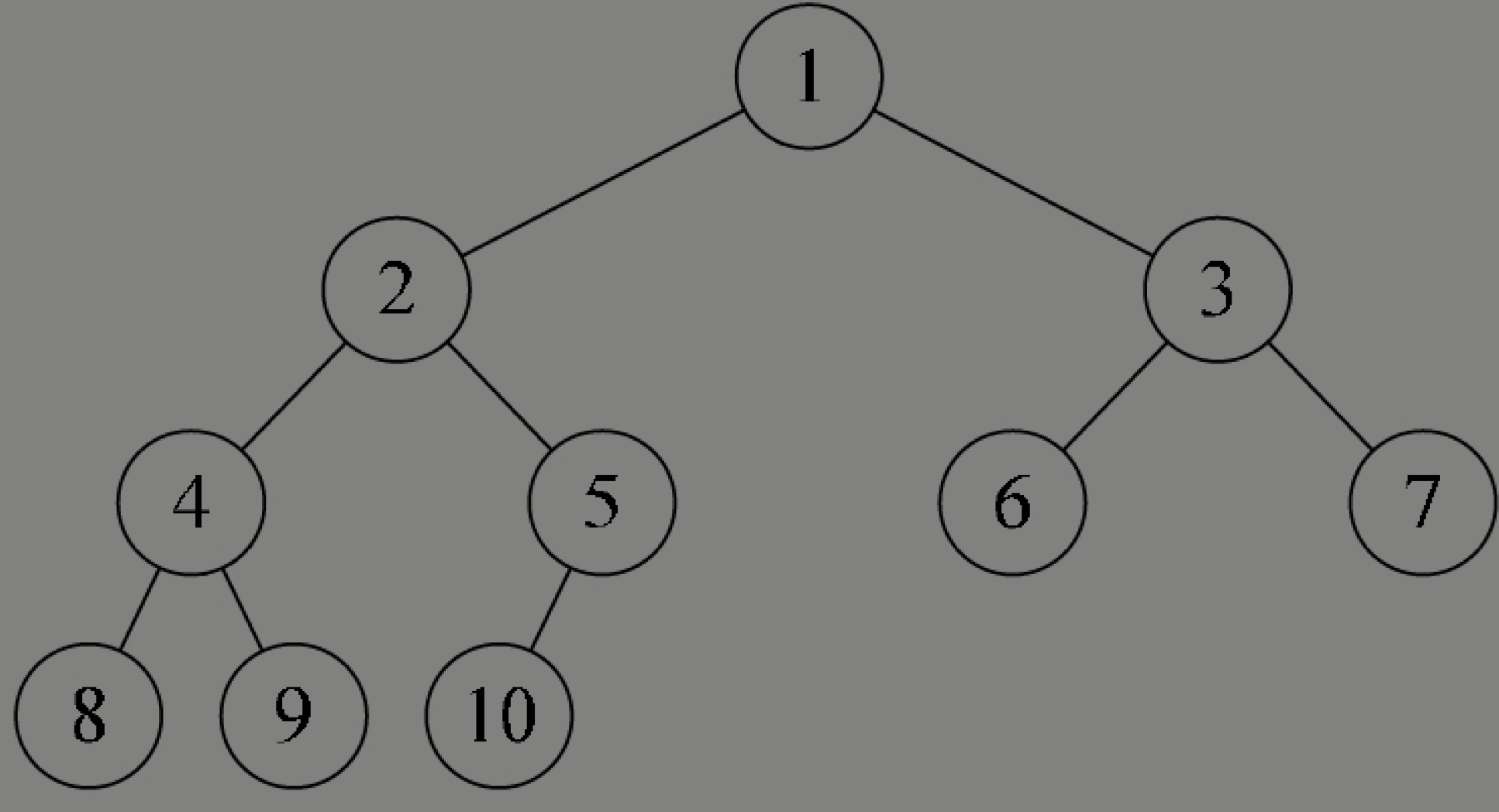
只有下圖中的樹,尽管它不是滿二叉樹,但是編號是連續的,所以它是完全二叉樹。
二叉树的性质是什么?
性質1:在二叉樹的第i層上至多有2i-1個結點(i≥1)。
性質2:深度為k的二叉樹至多有2k-1個結點(k≥1)。
深度為k意思就是有k層的二叉樹,我們先來看看簡單的。
性質3:對任何一棵二叉樹T,如果其終端結點數為n0,度為2的結點數為n2,則n0=n2+1。
終端結點數其實就是葉子結點數,而一棵二叉樹,除了葉子結點外,剩下的就是度為1或2的結點數了,我們設n1為度是1的結點數。則樹T結點總數n=n0+n1+n2。
性質4:具有n個結點的完全二叉樹的深度為(
表示不大於x的最大整數)。
由滿二叉樹的定義我們可以知道,深度為k的滿二叉樹的結點數n一定是2k-1。因為這是最多的結點個數。
性質5:如果對一棵有n個結點的完全二叉樹(其深度為)的結點按層序編號(從第1層到第
層,每層從左到右),對任一結點i(1≤i≤n)有:
1.如果i=1,則結點i是二叉樹的根,無雙親;如果i>1,則其雙親是結點。
2.如果2i>n,則結點i無左孩子(結點i為葉子結點);否則其左孩子是結點2i。
3.如果2i+1>n,則結點i無右孩子;否則其右孩子是結點2i+1。
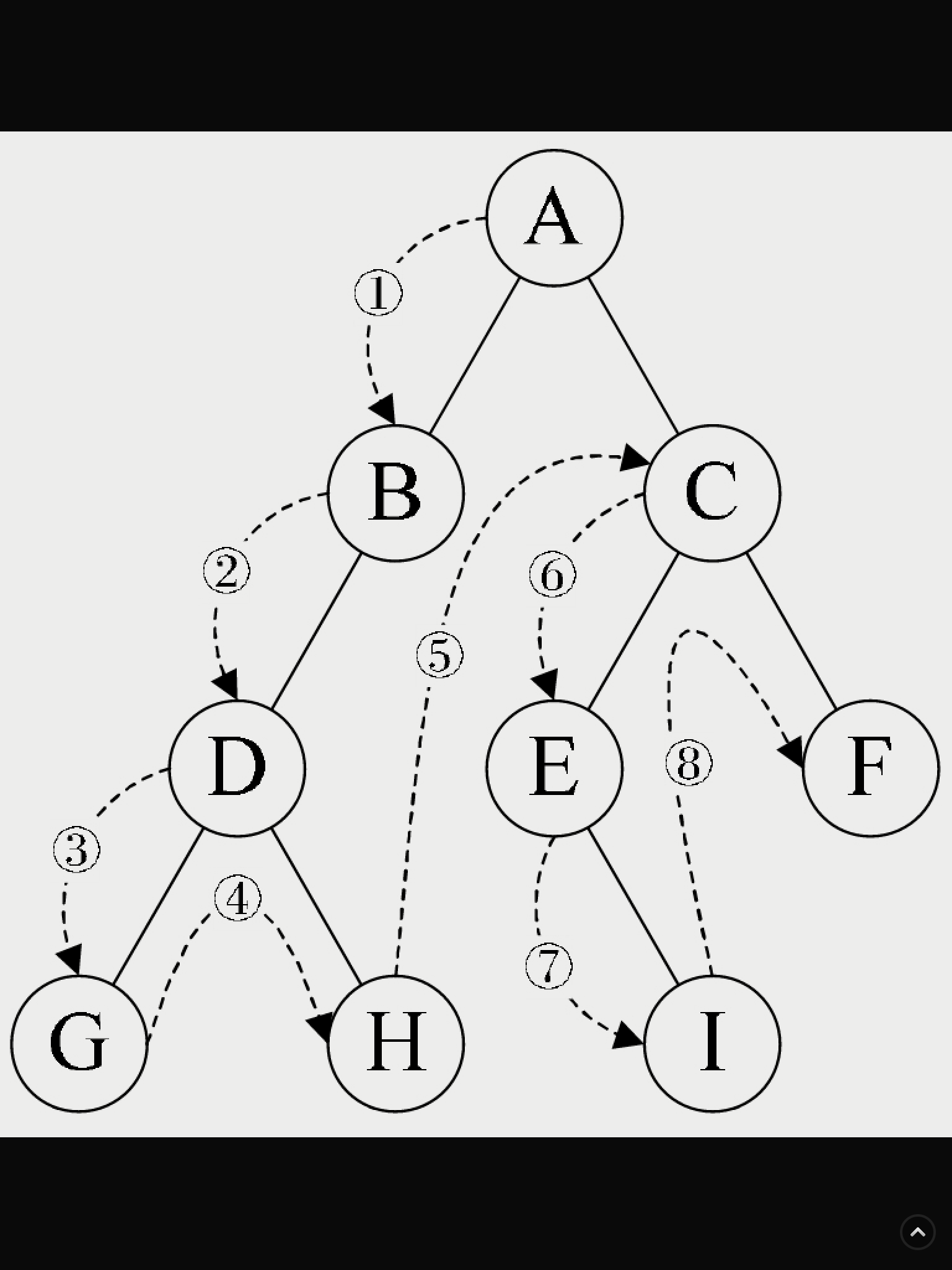
二叉树遍历方法之前序遍历是怎么回事?
規則是若二叉樹為空,則空操作返回,否則先訪問根結點,然後前序遍历左子樹,再前序遍历右子樹。
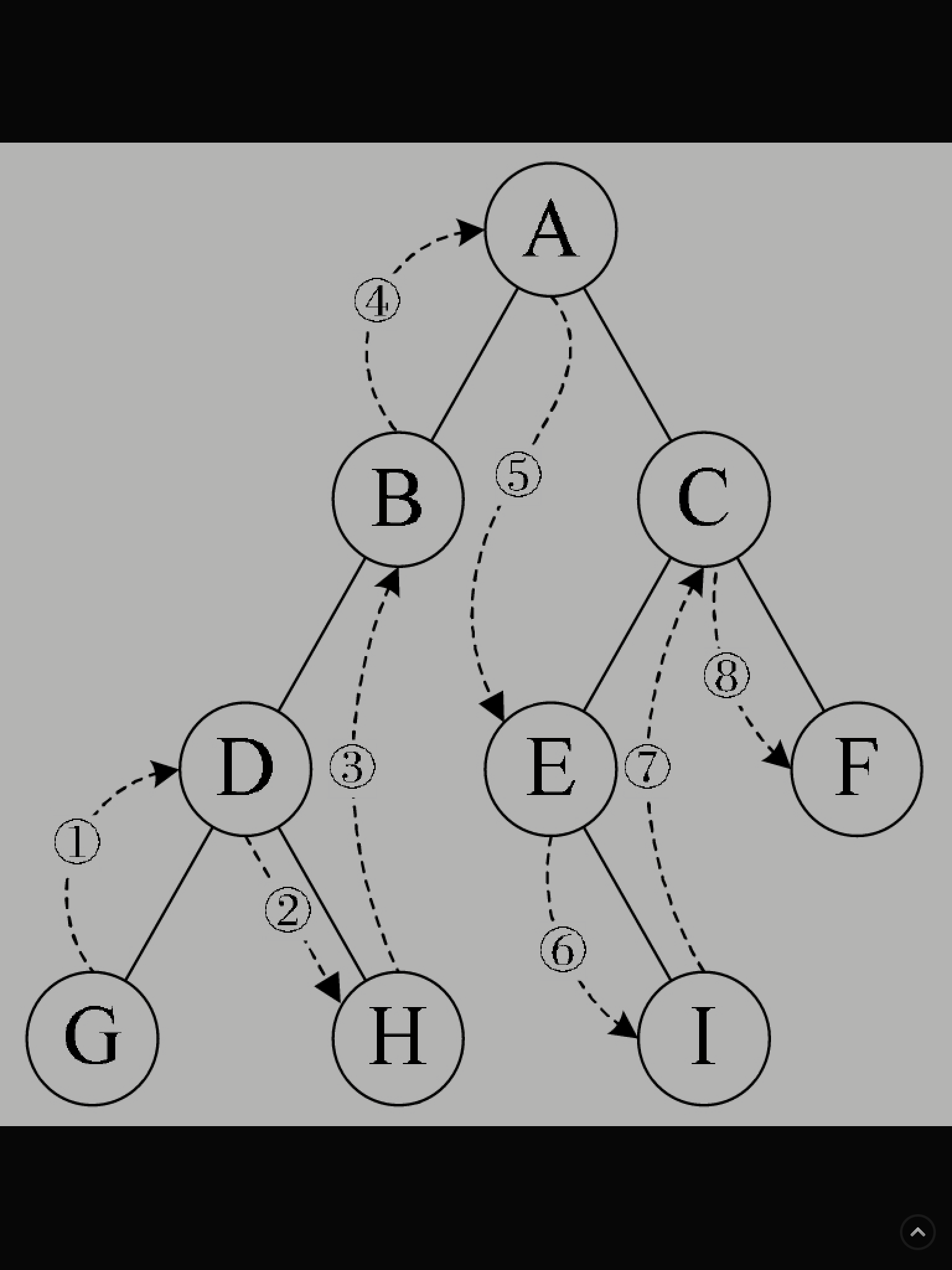
二叉树的中序遍历算法是怎么回事?
規則是若樹為空,則空操作返回,否則從根結點開始(註意并不是先訪問根結點),中序遍历根結點的左子樹,然後是訪問根結點,最後中序遍历右子樹。
二叉树的后序遍历算法是怎么回事?
規則是若樹為空,則空操作返回,否則從左到右先葉子後結點的方式遍历訪問左右子樹,最後是訪問根結點。
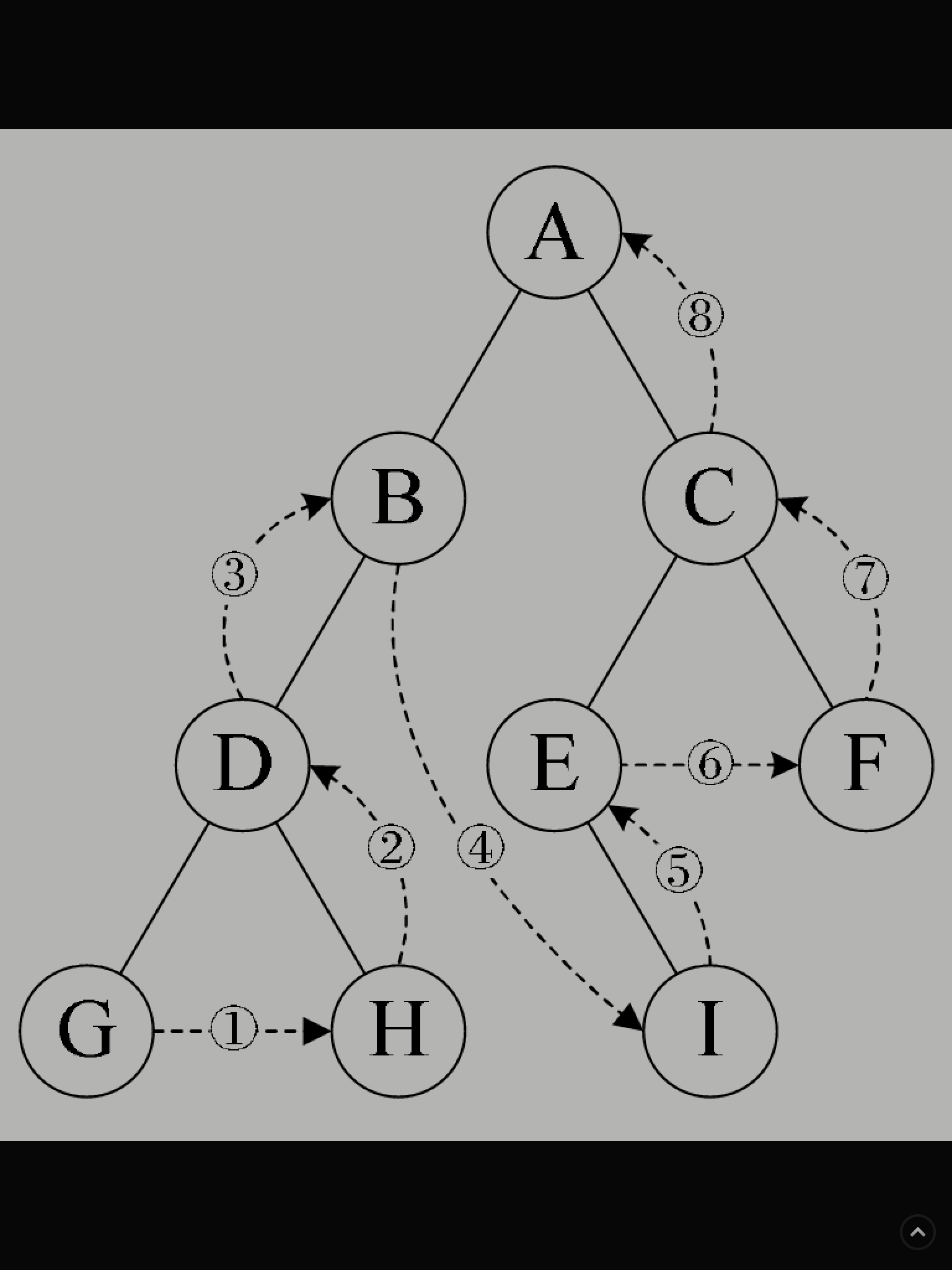
二叉树的层序遍历是怎么回事?
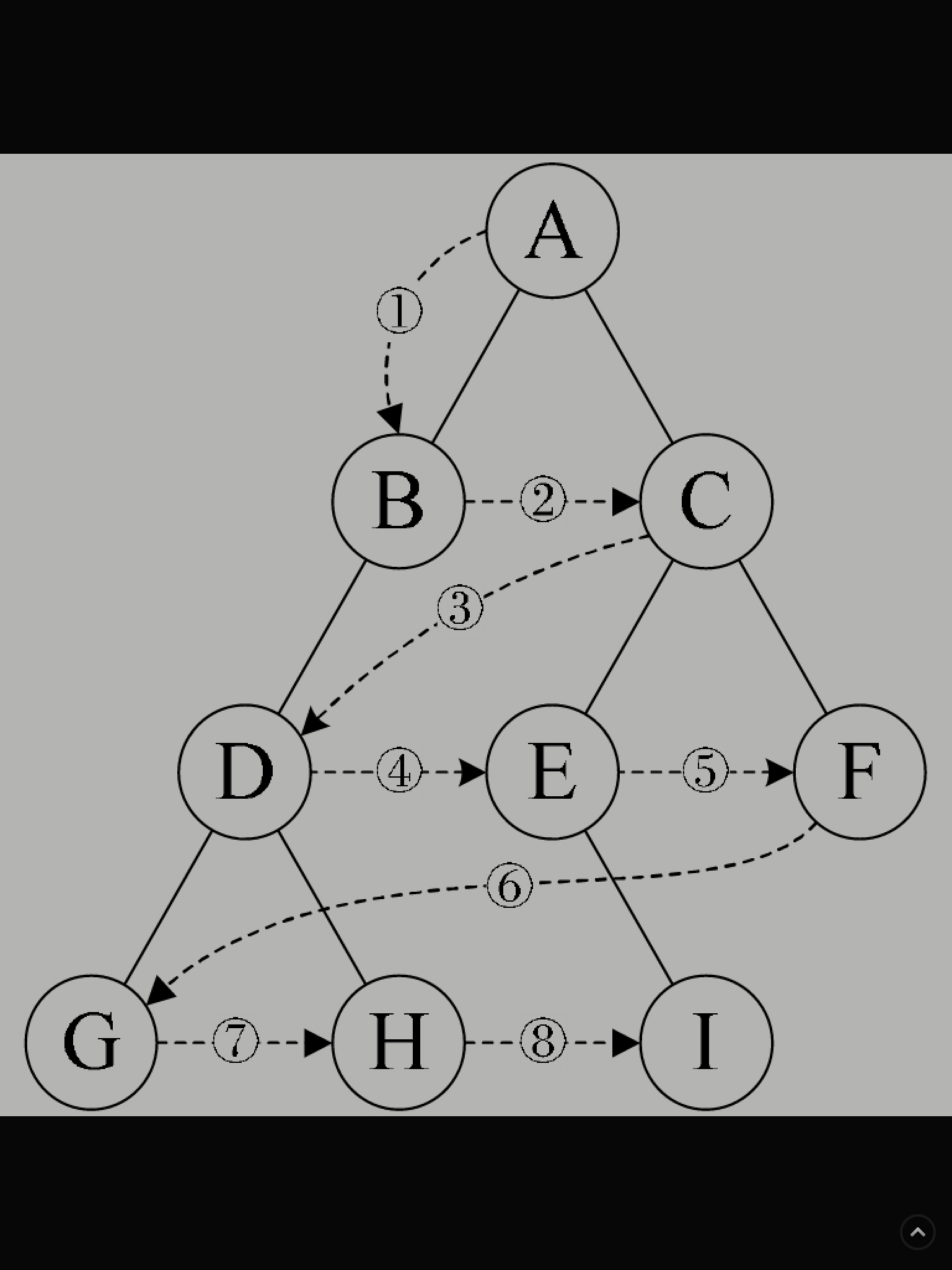
規則是若樹為空,則空操作返回,否則從樹的第一層,也就是根結點開始訪問,從上而下逐層遍历,在同一層中,按從左到右的順序對結點逐個訪問。
二叉树的特殊性质是什么?
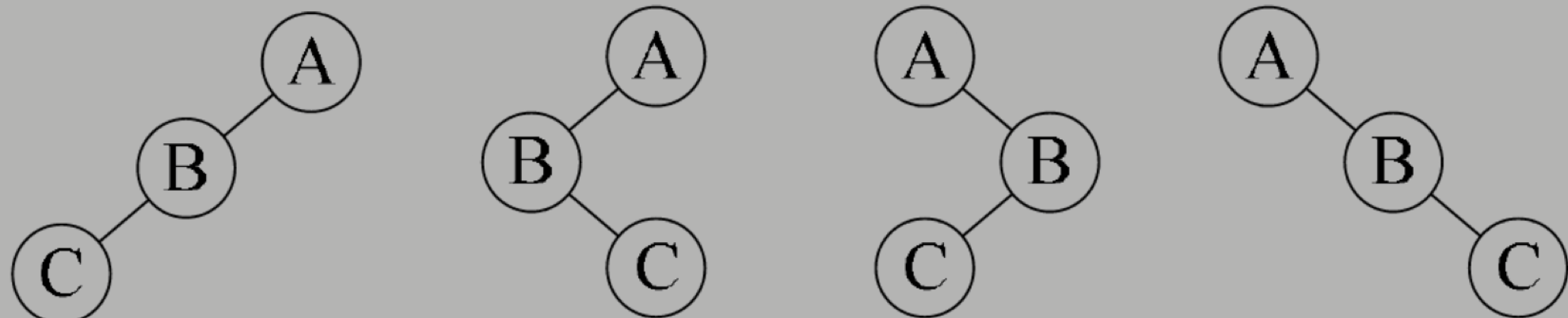
已知前序遍历序列和中序遍历序列,可以唯一確定一棵二叉樹。
已知後序遍历序列和中序遍历序列,可以唯一確定一棵二叉樹。
但要註意了,已知前序和後序遍历,是不能確定一棵二叉樹的,原因也很簡單,比如前序序列是ABC,後序序列是CBA。我們可以確定A一定是根結點,但接下來,我們無法知道,哪個結點是左子樹,哪個是右子樹。這棵樹可能有如圖所示的四種可能。
一棵樹如何經過三個步驟轉換為一棵二叉樹?
只有长子才是左边的树,其他都是右边的树。
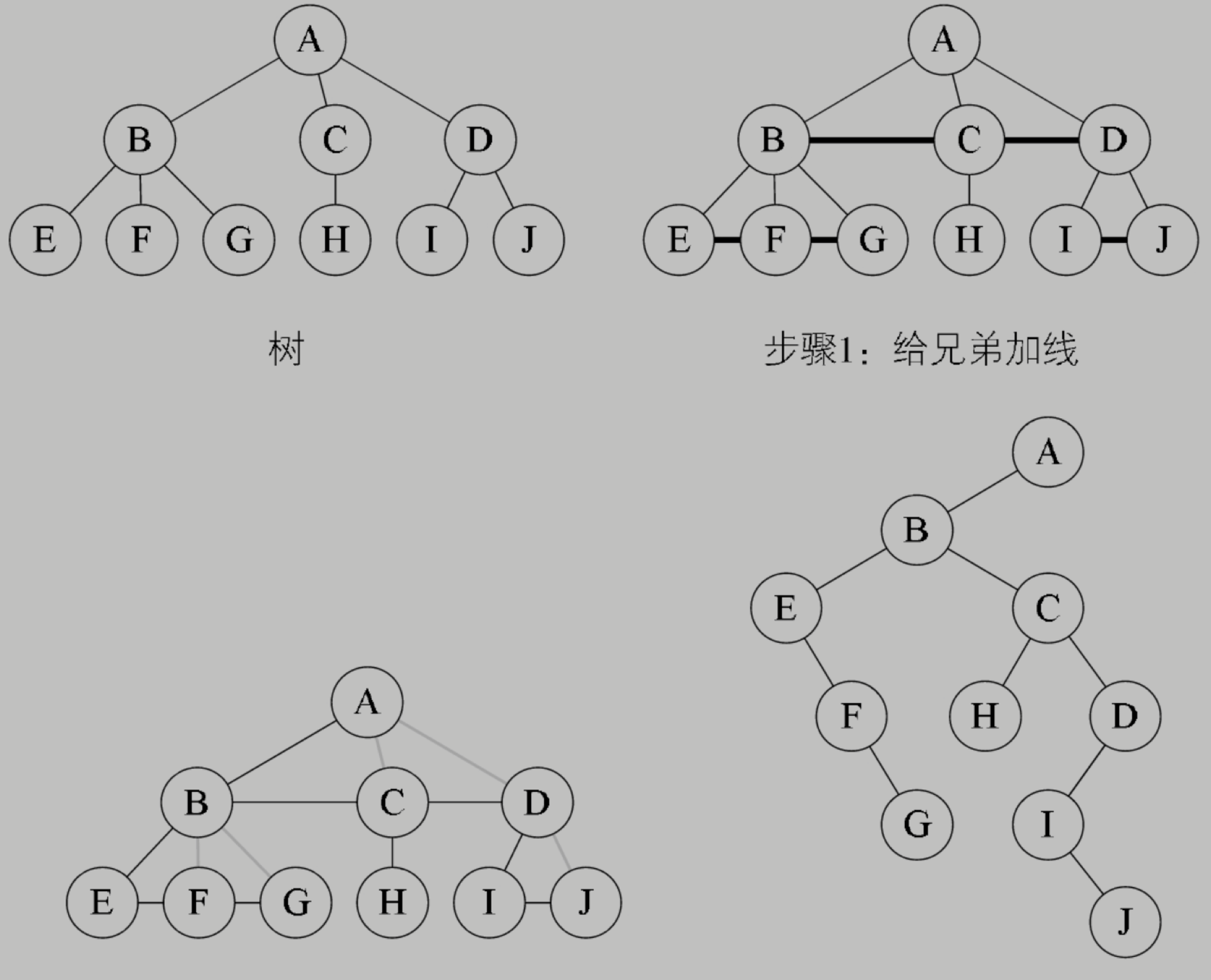
如何将森林转化为一颗二叉树?
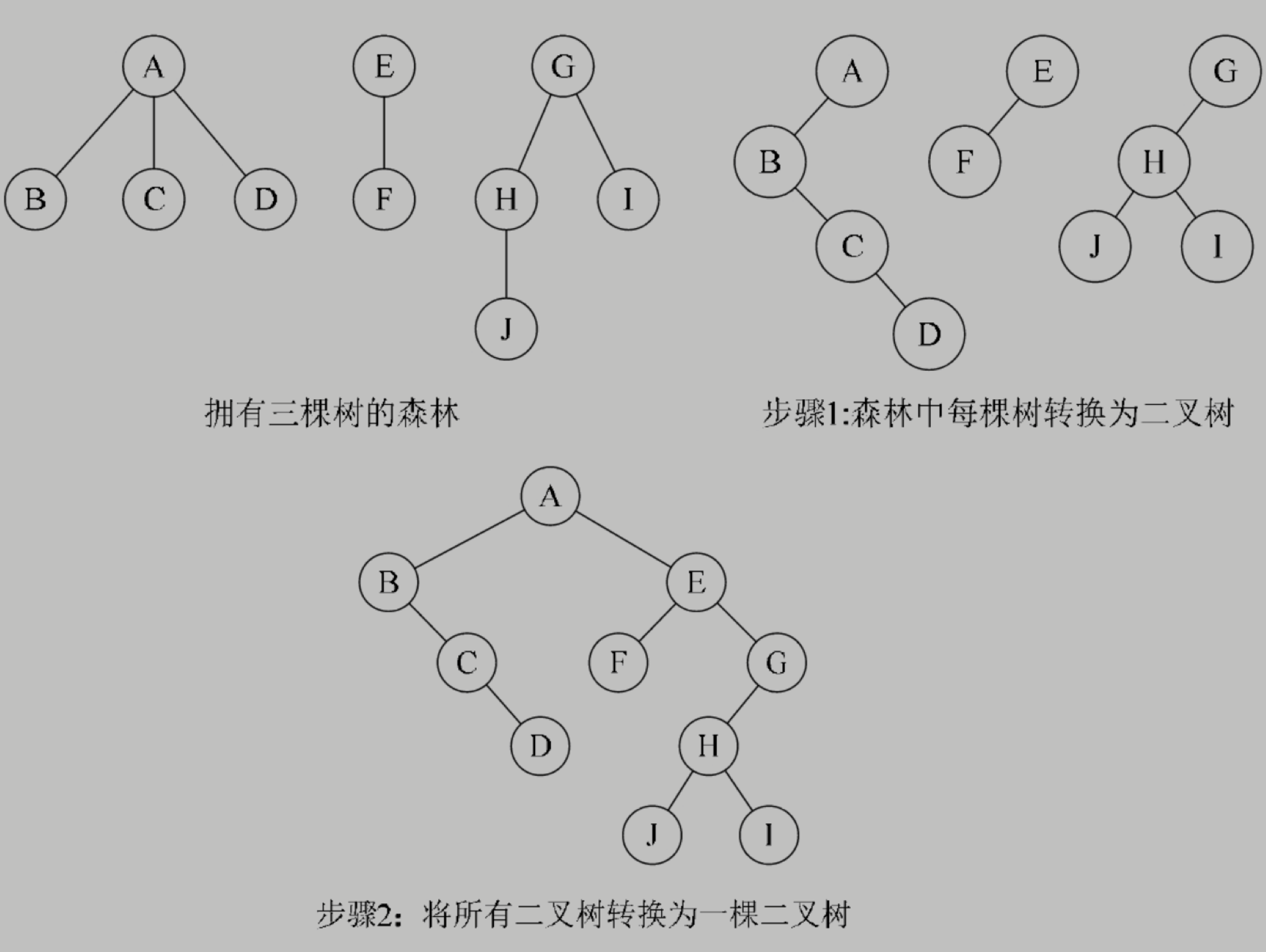
如何将树转换为二叉树?
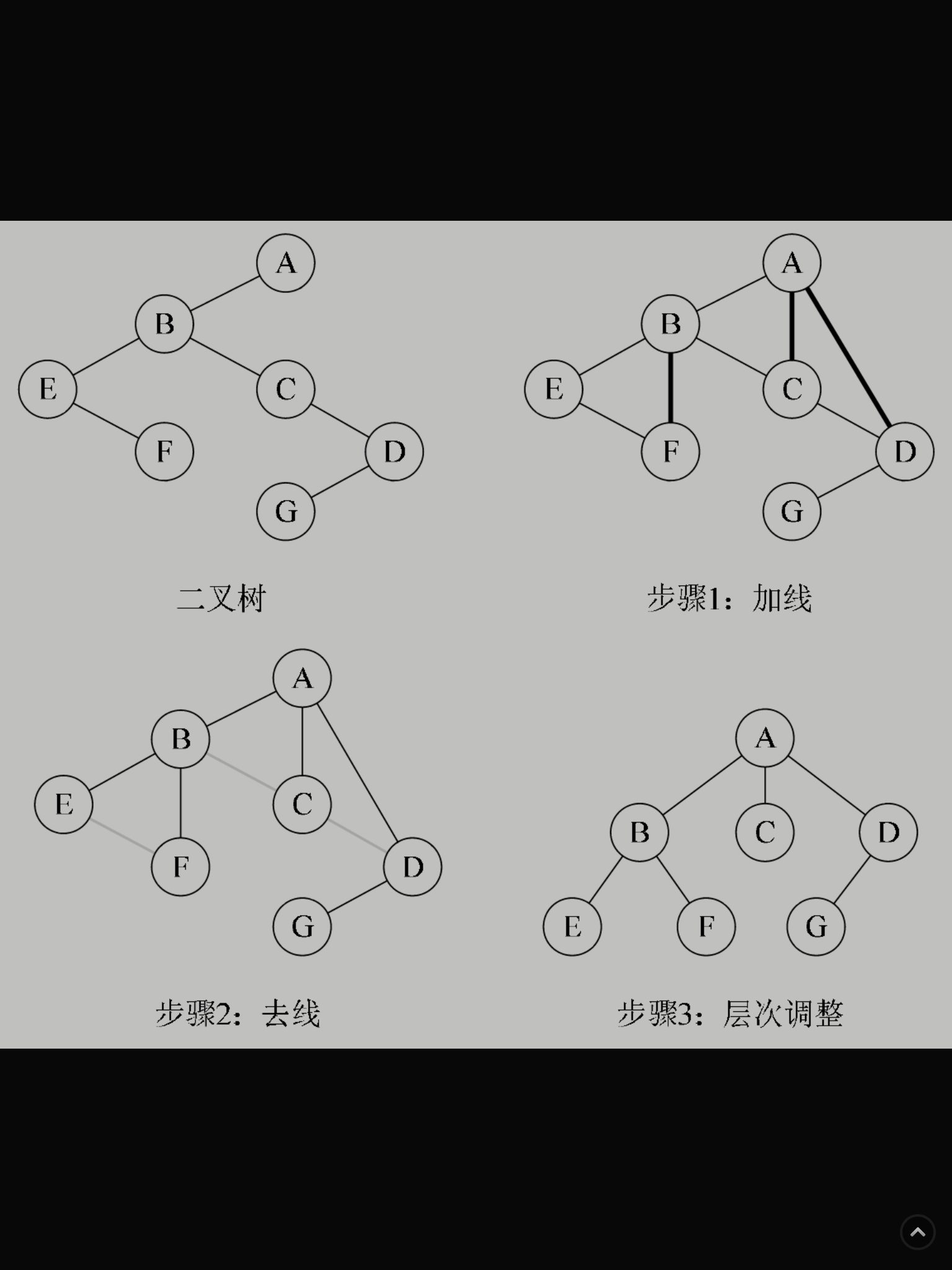
如何将树转换为森林?
那么如果是转换成森林,步骤如下:
从根结点开始,若右孩子存在,则把与右孩子结点的连线删除,再查看分离后的二叉树,若右孩子存在,则连线删除……,直到所有右孩子连线都删除为止,得到分离的二叉树。
再将每棵分离后的二叉树转换为树即可。

图的定义是什么?
圖(Graph)是由頂點的有窮非空集合和頂點之間邊的集合組成,通常表示為:G(V,E),其中,G表示一個圖,V是圖G中頂點的集合,E是圖G中邊的集合。
图的常识有哪些?
線性表中我們把數據元素叫元素,樹中將數據元素叫結點,在圖中數據元素,我們則稱之為頂點(Vertex)。
線性表中可以沒有數據元素,稱為空表。樹中可以沒有結點,叫做空樹。那麼對於圖呢?
在圖結構中,不允許沒有頂點。在定義中,若V是頂點的集合,則強調了頂點集合V有窮非空。
線性表中,相鄰的數據元素之間具有線性關系,樹結構中,相鄰兩層的結點具有層次關系,而圖中,任意兩個頂點之間都可能有關系,頂點之間的邏輯關系用邊來表示,邊集可以是空的。
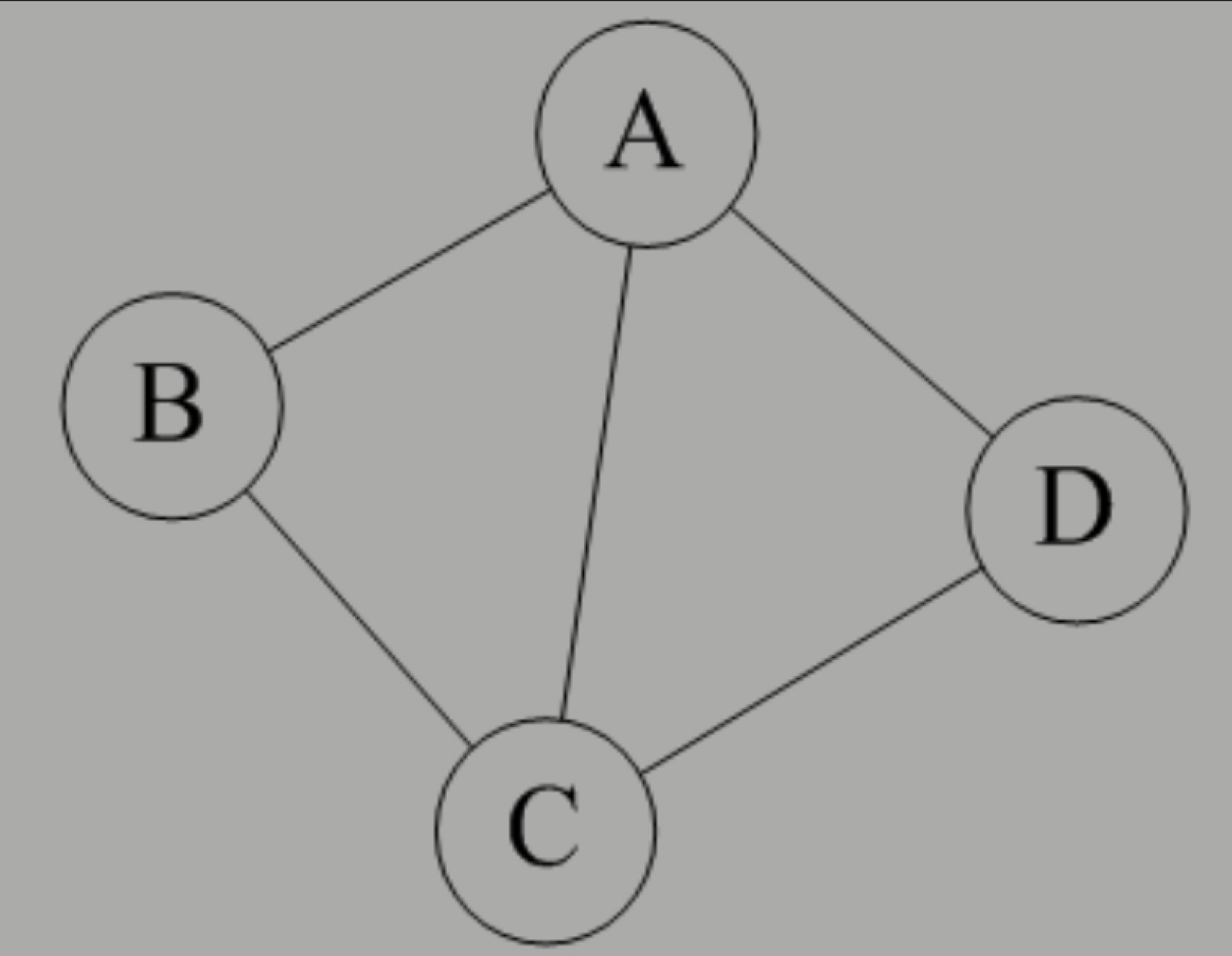
无序对和无向边是怎样?
無向邊:若頂點vi到vj之間的邊沒有方向,則稱這條邊為無向邊(Edge),用無序偶對(vi,vj)來表示。
如果圖中任意兩個頂點之間的邊都是無向邊,則稱該圖為無向圖(Undirected graphs)。
下圖就是一個無向圖,由於是無方向的,連接頂點A與D的邊,可以表示成無序對(A,D),也可以寫成(D,A)。
對於圖中的無向圖G1來説,G1=(V1,{E1}),其中頂點集合V1={A,B,C,D};邊集合E1={(A,B),(B,C),(C,D),(D,A),(A,C)}
有向边和有向图分别是什么?
有向边:若从顶点vi到vj的边有方向,则称这条边为有向边,也称为弧(Arc)。
用有序偶<vi,vj>来表示,vi称为弧尾(Tail),vj称为弧头(Head)。
如果图中任意两个顶点之间的边都是有向边,则称该图为有向图(Directed graphs)。
下图就是一个有向图。连接顶点A到D的有向边就是弧,A是弧尾,D是弧头,<A,D>表示弧,注意不能写成<D,A>。
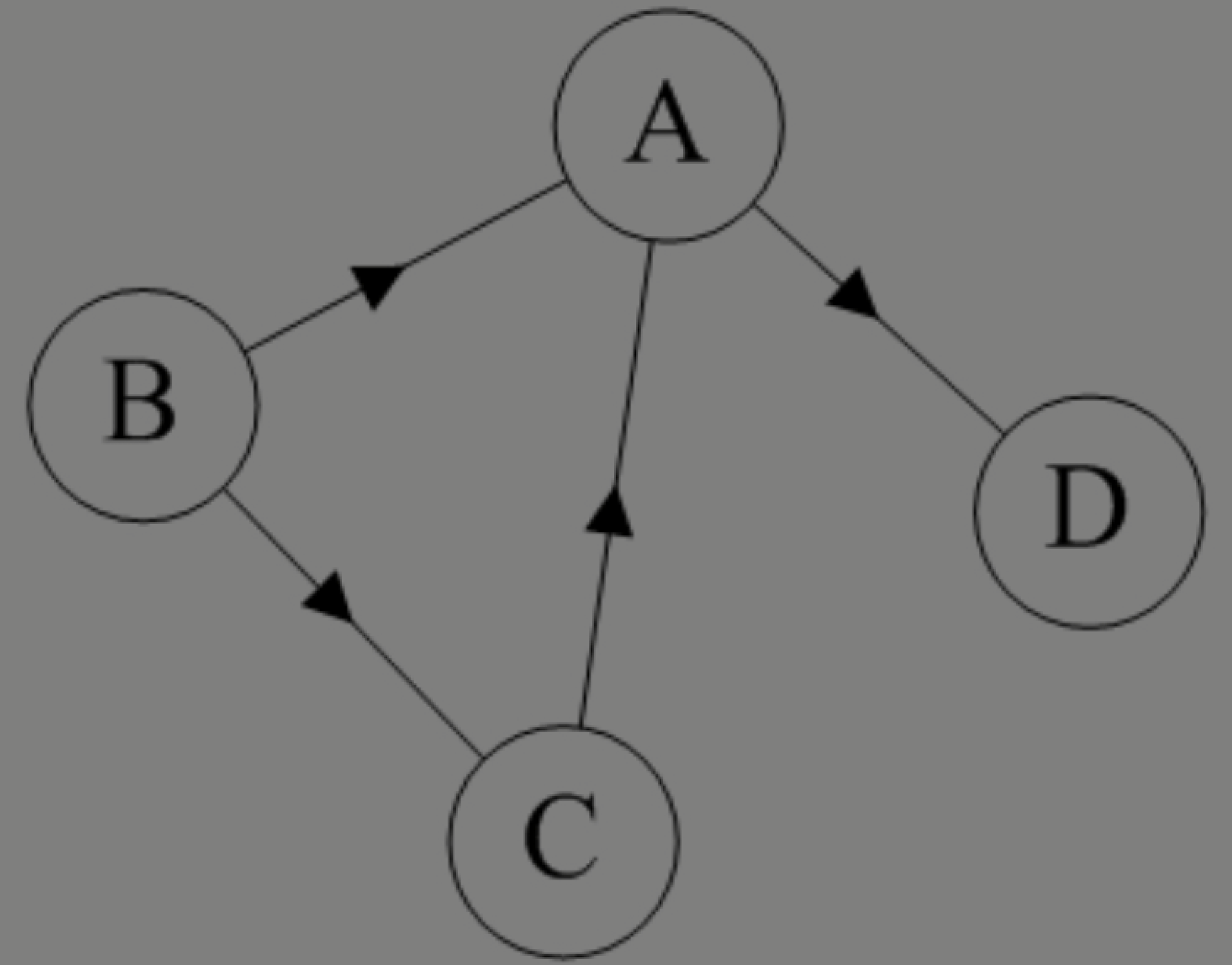
对于图中的有向图G2来说,G2=(V2,{E2}),其中顶点集合V2={A,B,C,D};弧集合E2={<A,D>,<B,A>,<C,A>,<B,C>}。
简单图是什么?
在图中,若不存在顶点到其自身的边,且同一条边不重复出现,则称这样的图为简单图。显然图中的两个图就不属于我们要讨论的范围。
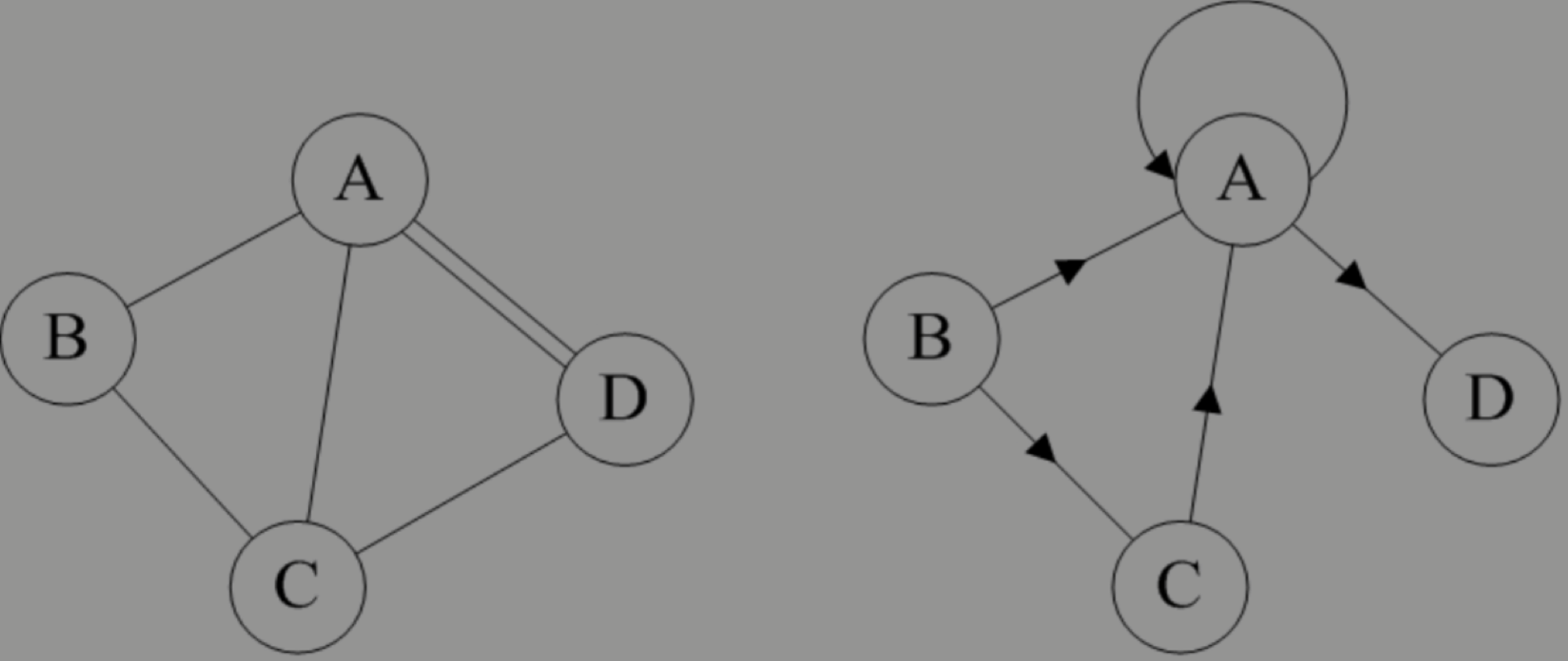
看清楚了,无向边用小括号“()”表示,而有向边则是用尖括号“<>”表示。
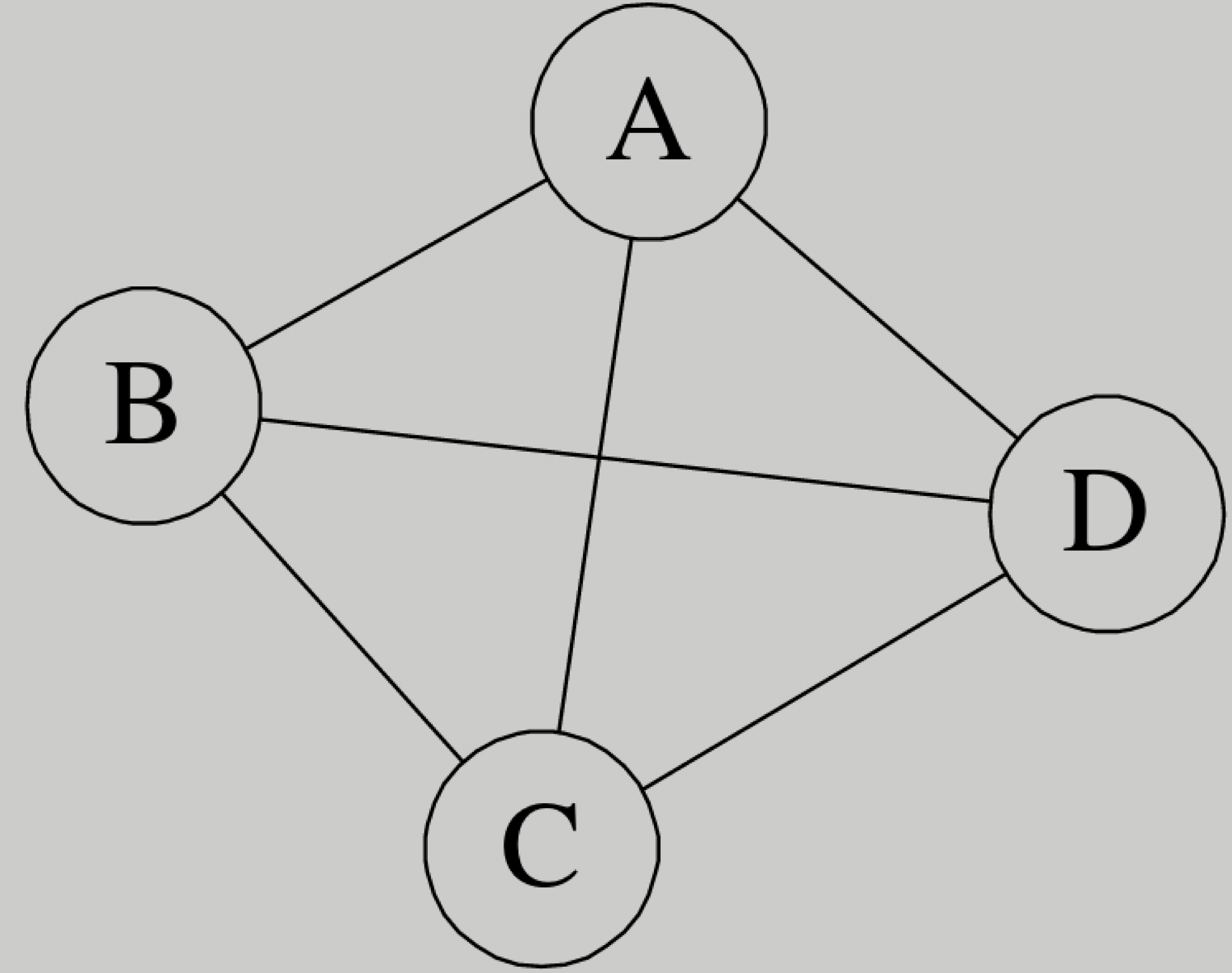
无向完全图是什么?
在无向图中,如果任意两个顶点之间都存在边,则称该图为无向完全图。含有n个顶点的无向完全图有条边。比如图7-2-5就是无向完全图,因为每个顶点都要与除它以外的顶点连线,顶点A与BCD三个顶点连线,共有四个顶点,自然是4×3,但由于顶点A与顶点B连线后,计算B与A连线就是重复,因此要整体除以2,共有6条边。
有向完全图的定义是什么?
在有向图中,如果任意两个顶点之间都存在方向互为相反的两条弧,则称该图为有向完全图。含有n个顶点的有向完全图有n×(n-1)条边,如图所示。

有向图和无向图的结论是什么?
对于具有n个顶点和e条边数的图,无向图0≤e≤n(n-1)/2,有向图0≤e≤n(n-1)
有向图和无向图的结论是什么?
对于具有n个顶点和e条边数的图,无向图0≤e≤n(n-1)/2,有向图0≤e≤n(n-1)
稀疏图和稠密图还有网的定义是什么?
有很少条边或弧的图称为稀疏图,反之称为稠密图。这里稀疏和稠密是模糊的概念,都是相对而言的。
比如我去上海世博会那天,参观的人数差不多50万人,我个人感觉人数实在是太多,可以用稠密来形容。可后来听说,世博园里人数最多的一天达到了103万人,啊,50万人是多么的稀疏呀。
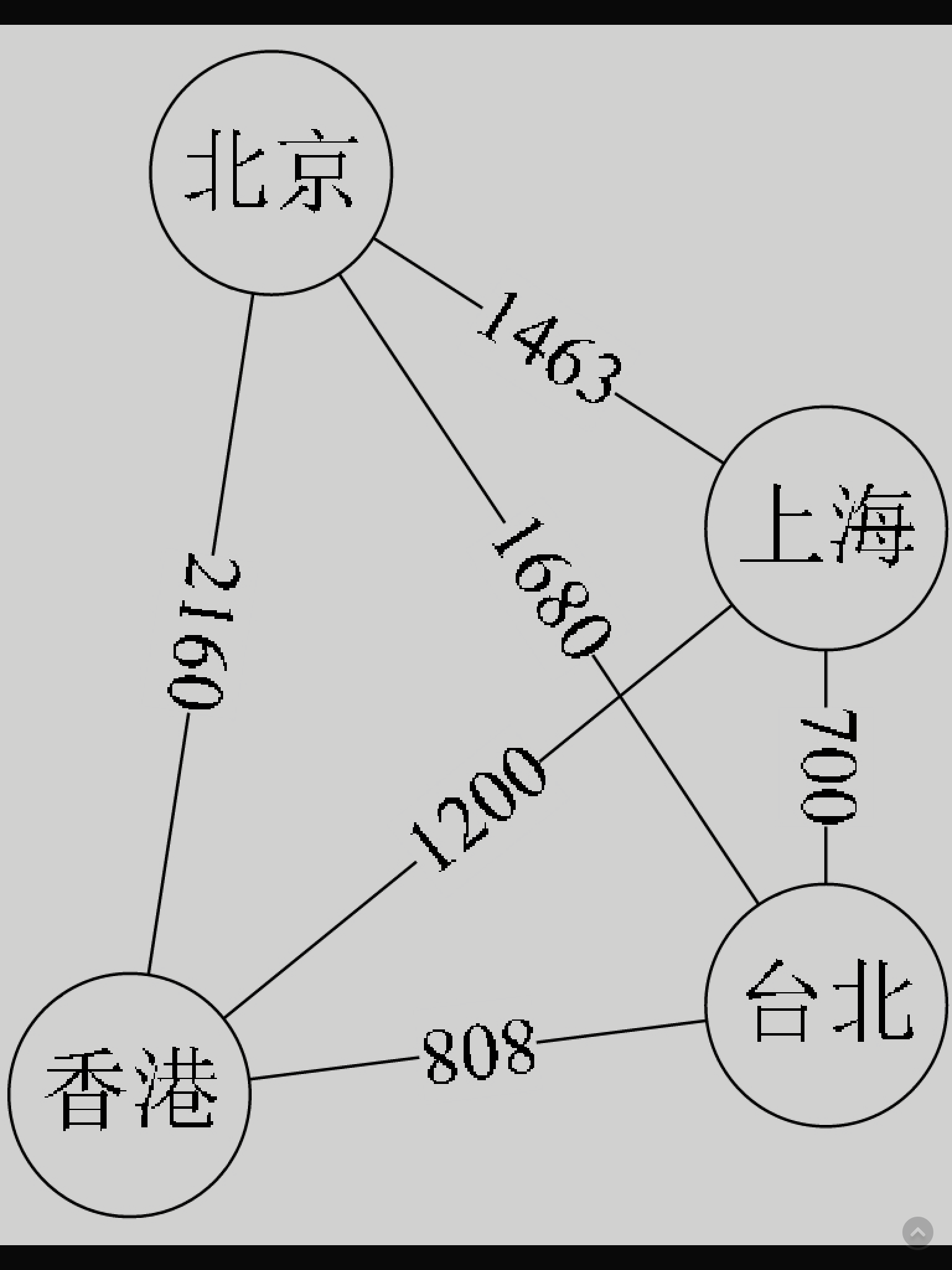
有些图的边或弧具有与它相关的数字,这种与图的边或弧相关的数叫做权(Weight)。
这些权可以表示从一个顶点到另一个顶点的距离或耗费。这种带权的图通常称为网(Network)。
图7-2-7就是一张带权的图,即标识中国四大城市的直线距离的网,此图中的权就是两地的距离。
图与子图的概念是什么?
出度和入度是怎么回事?
对于有向图G=(V,{E}),如果弧<v,v'>∈E,则称顶点v邻接到顶点v',顶点v'邻接自顶点v。
弧<v,v'>和顶点v,v'相关联。以顶点v为头的弧的数目称为v的入度(InDegree),记为ID(v);
以v为尾的弧的数目称为v的出度(OutDegree),记为OD(v);顶点v的度为TD(v)=ID(v)+OD(v)。
顶点到其他点之间是有不同的去法的
例如图7-2-9中就列举了顶点B到顶点D四种不同的路径。
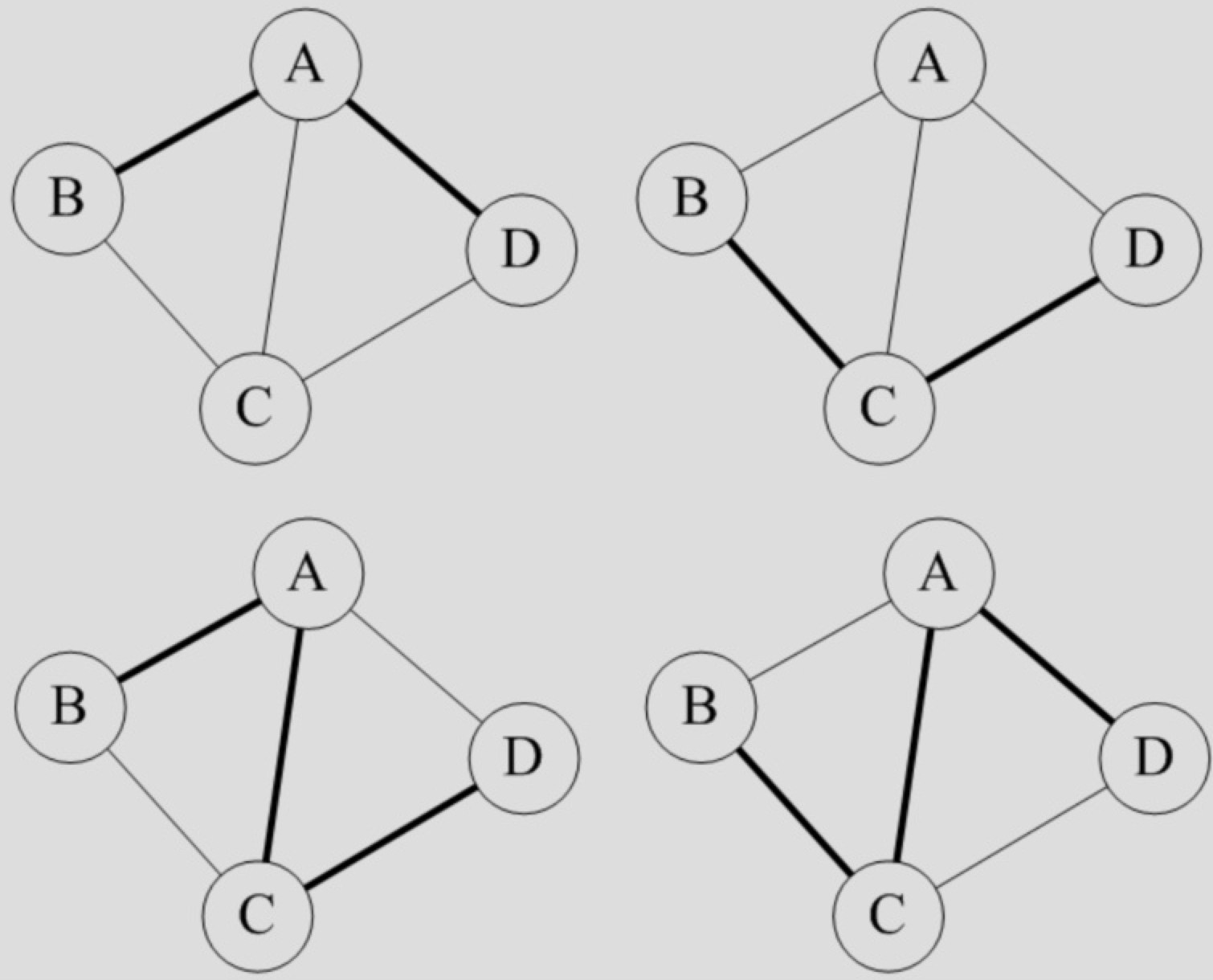
如果G是有向图,则路径也是有向的
图的路径是怎样的?
树中根结点到任意结点的路径是唯一的,但是图中顶点与顶点之间的路径却是不唯一的。
路径的长度是路径上的边或弧的数目。
简单环和简单路径是怎样的?
第一个顶点和最后一个顶点相同的路径称为回路或环(Cycle)。序列中顶点不重复出现的路径称为简单路径。除了第一个顶点和最后一个顶点之外,其余顶点不重复出现的回路,称为简单回路或简单环。
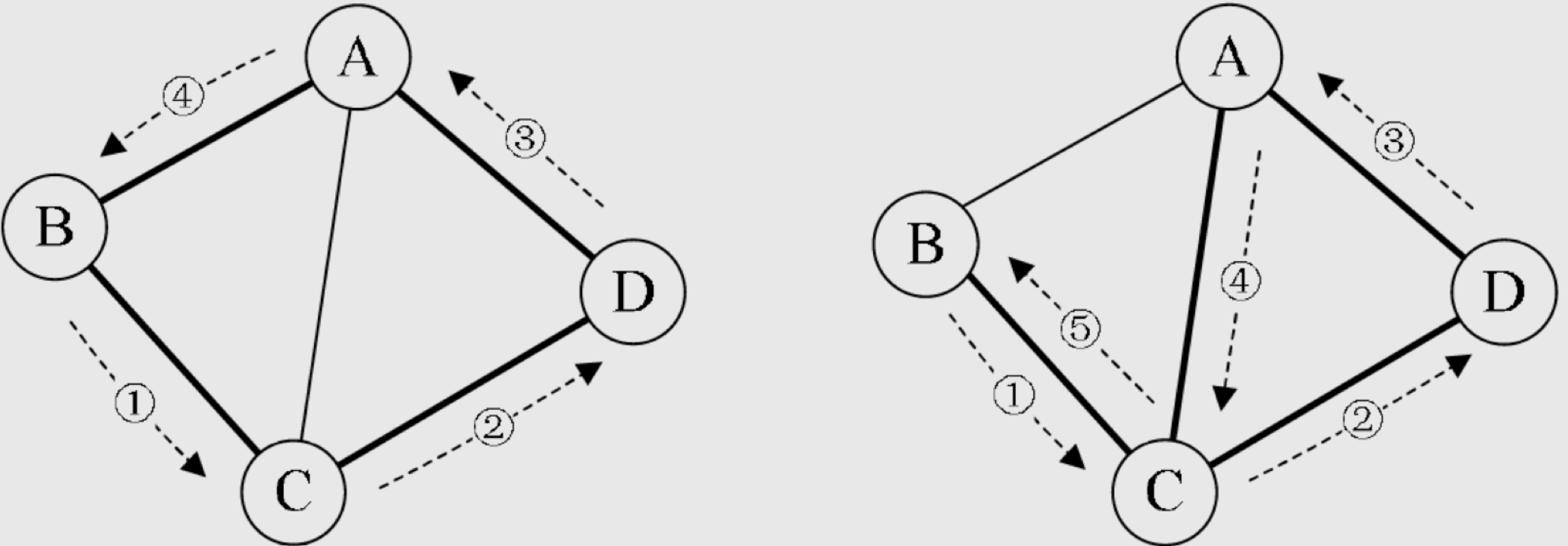
什么是联通?什么又是联通图?
在无向图G中,如果从顶点v到顶点v'有路径,则称v和v'是连通的。
如果对于图中任意两个顶点vi、vj∈V,vi和vj都是连通的,则称G是连通图(Connected Graph)。
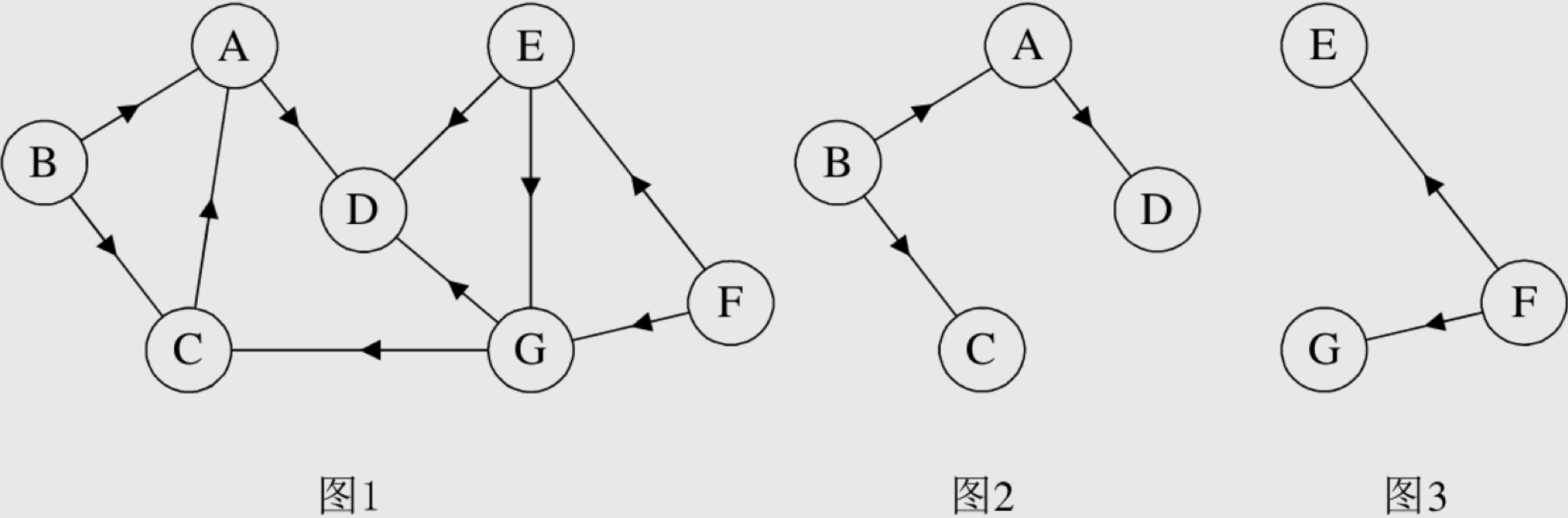
联通分量是怎么定义?
无向图中的极大连通子图称为连通分量。注意连通分量的概念,它强调:
要是子图;
子图要是连通的;
连通子图含有极大顶点数;
具有极大顶点数的连通子图包含依附于这些顶点的所有边。
图1是一个无向非连通图。但是它有两个连通分量,即图2和图3。而图4,尽管是图1的子图,但是它却不满足连通子图的极大顶点数(图2满足)。因此它不是图1的无向图的连通分量。

强联通图和强联通分量是怎么回事?
在有向图G中,如果对于每一对vi、vj∈V、vi≠vj,从vi到vj和从vj到vi都存在路径,则称G是强连通图。有向图中的极大强连通子图称做有向图的强连通分量。例如图7-2-13,图1并不是强连通图,因为顶点A到顶点D存在路径,而D到A就不存在。图2就是强连通图,而且显然图2是图1的极大强连通子图,即是它的强连通分量。
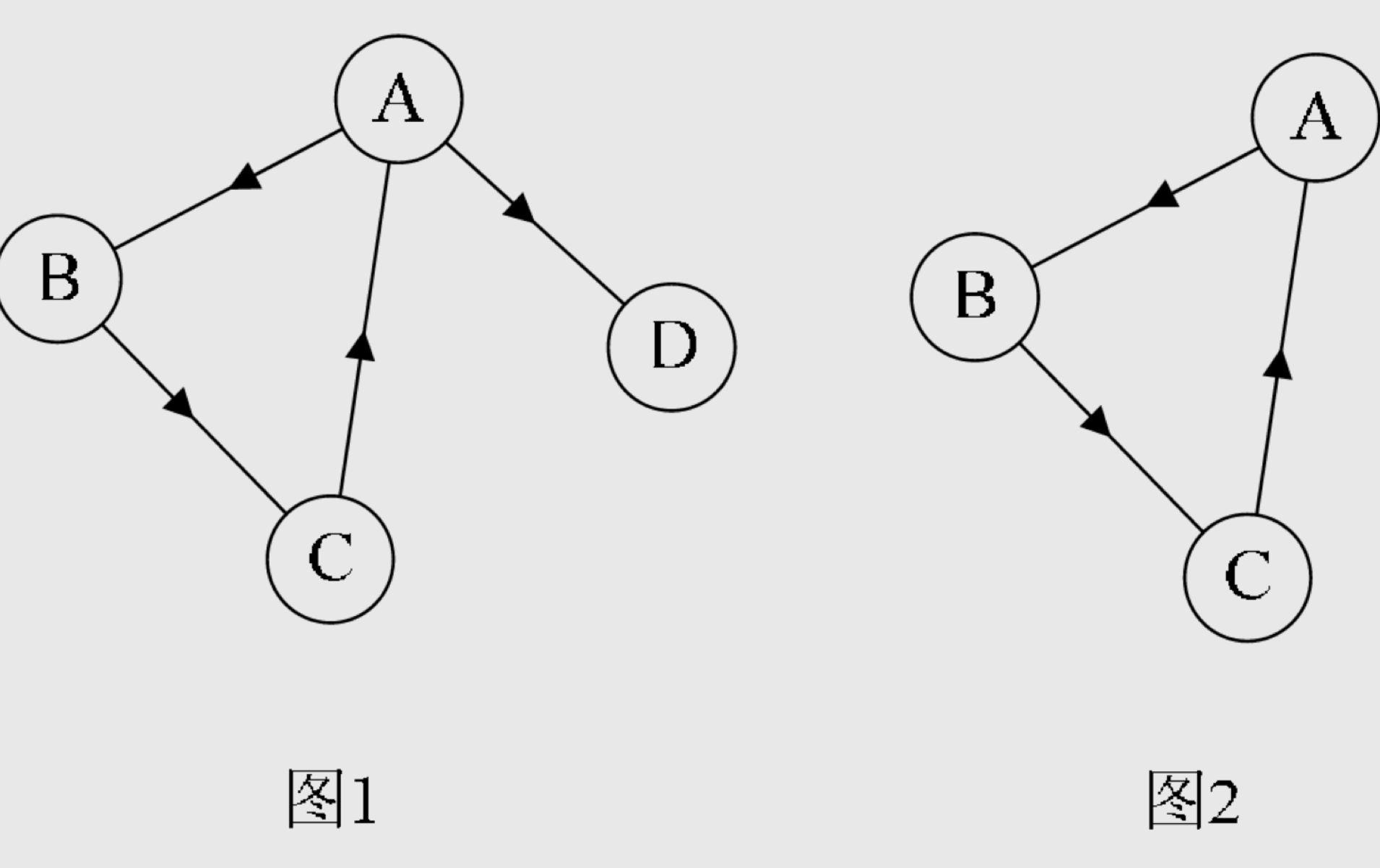
连通图的生成树是什么?
所谓的一个连通图的生成树是一个极小的连通子图,它含有图中全部的n个顶点,但只有足以构成一棵树的n-1条边。
比如图7-2-14的图1是一普通图,但显然它不是生成树,当去掉两条构成环的边后,比如图2或图3,就满足n个顶点n-1条边且连通的定义了。
它们都是一棵生成树。从这里也可知道,如果一个图有n个顶点和小于n-1条边,则是非连通图,如果它多于n-1边条,必定构成一个环,因为这条边使得它依附的那两个顶点之间有了第二条路径。
比如图2和图3,随便加哪两顶点的边都将构成环。不过有n-1条边并不一定是生成树,比如图4。

有向树是什么?
如果一个有向图恰有一个顶点的入度为0,其余顶点的入度均为1,则是一个有向树。
对有向树的理解比较容易,所谓入度为0其实就相当于树中的根结点,其余顶点入度为1就是说树的非根结点的双亲只有一个。
一个有向图的生成森林由若干棵有向树组成,含有图中全部顶点,但只有足以构成若干棵不相交的有向树的弧。
如图7-2-15的图1是一棵有向图。去掉一些弧后,它可以分解为两棵有向树,如图2和图3,这两棵就是图1有向图的生成森林。
图的术语总结
图按照有无方向分为无向图和有向图。
无向图由顶点和边构成,有向图由顶点和弧构成。
弧有弧尾和弧头之分。
图按照边或弧的多少分稀疏图和稠密图。
如果任意两个顶点之间都存在边叫完全图,有向的叫有向完全图。
若无重复的边或顶点到自身的边则叫简单图。
图中顶点之间有邻接点、依附的概念。
无向图顶点的边数叫做度,有向图顶点分为入度和出度。
图上的边或弧上带权则称为网。
图中顶点间存在路径,两顶点存在路径则说明是连通的,如果路径最终回到起始点则称为环,当中不重复叫简单路径。
若任意两顶点都是连通的,则图就是连通图,有向则称强连通图。
图中有子图,若子图极大连通则就是连通分量,有向的则称强连通分量。
无向图中连通且n个顶点n-1条边叫生成树。
有向图中一顶点入度为0其余顶点入度为1的叫有向树。
一个有向图由若干棵有向树构成生成森林。
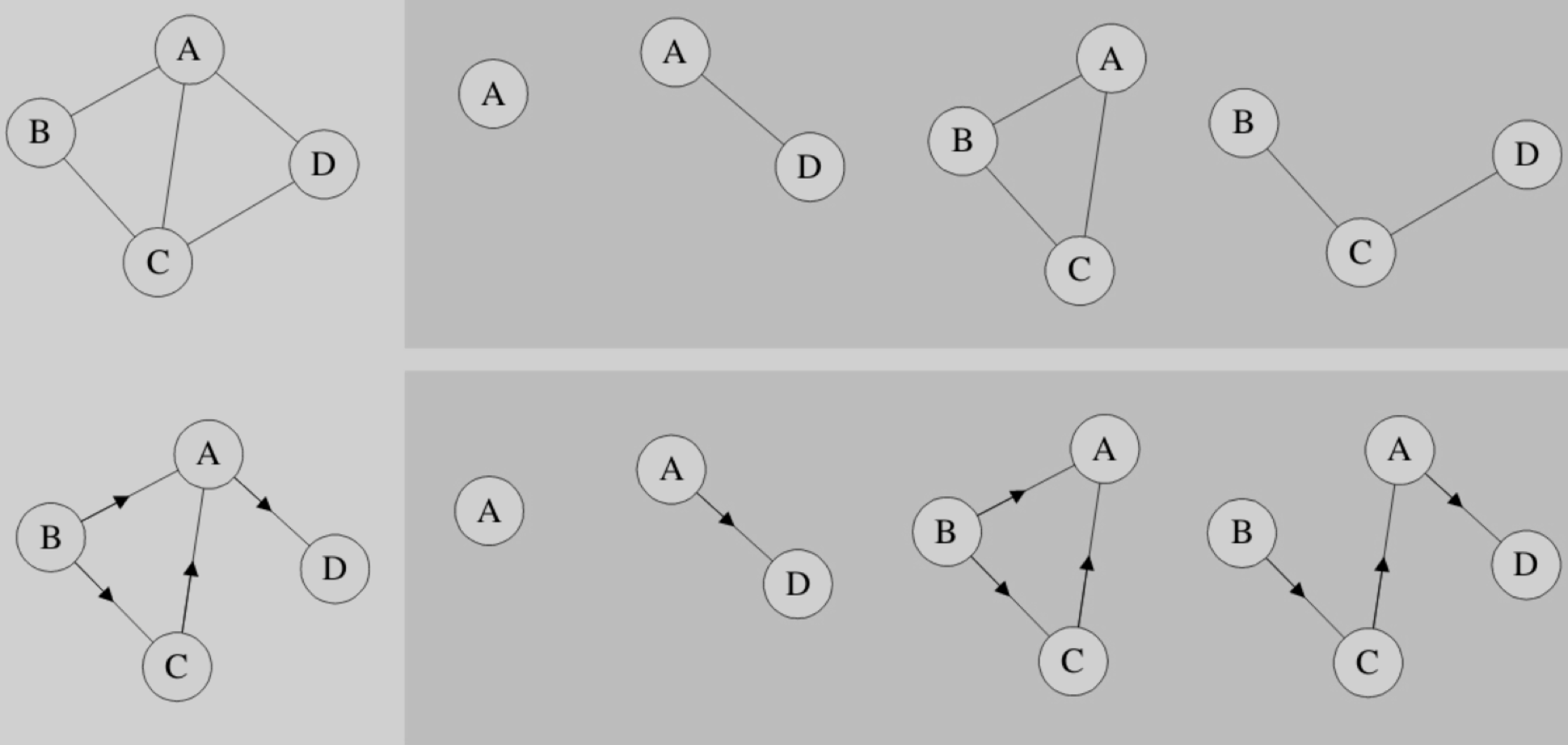
千变万化的图
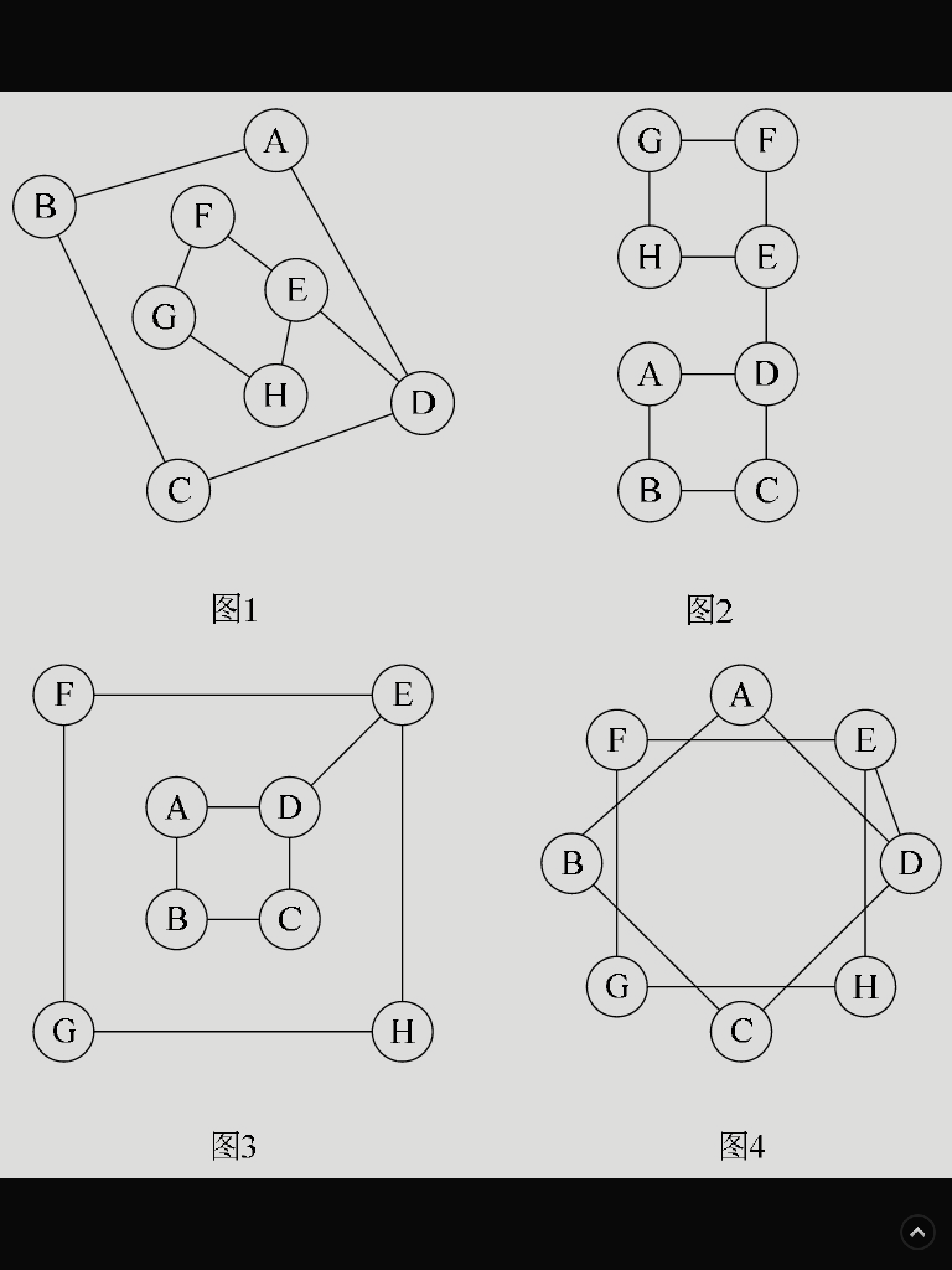
其实从图的逻辑结构定义来看,图上任何一个顶点都可被看成是第一个顶点,任一顶点的邻接点之间也不存在次序关系。比如图7-4-1中的四张图,仔细观察发现,它们其实是同一个图,只不过顶点的位置不同,就造成了表象上不太一样的感觉。
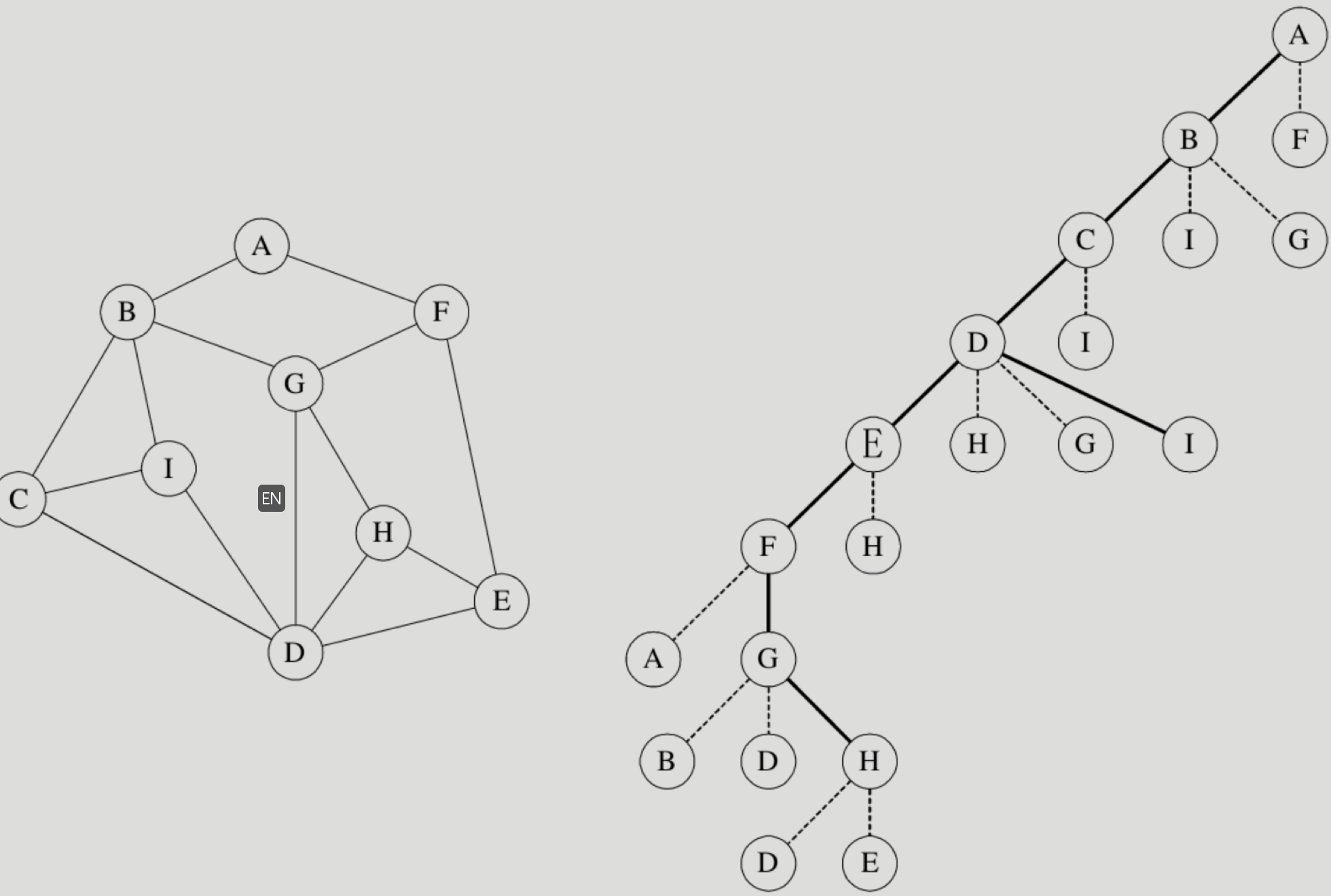
深度优先遍历是什么?
深度优先遍历(Depth_First_Search),也有称为深度优先搜索,简称为DFS。
深度优先遍历就像走迷宫,先走定一个最外围的方向,边走边做记号,直到将全部空间都做上记号,就遍历完成了,只不过他做记号的流程,是一路走到尽的做,所以才叫深度优先遍历。
比如下面的图,先从 a 找到 f 再继续找发现回来 a 了,而 a 已经找过了,所以倒退回去刚才的 f 继续找,然后再退回去 e 直到最后退回到 a ,遍历完全。
广度优先遍历是什么鬼?
广度优先遍历(Breadth_First_Search),又称为广度优先搜索,简称BFS。
还是以找钥匙的例子为例。小孩子不太可能把钥匙丢到大衣柜顶上或厨房的油烟机里去,深度优先遍历意味着要彻底查找完一个房间才查找下一个房间,这未必是最佳方案。所以不妨先把家里的所有房间简单看一遍,看看钥匙是不是就放在很显眼的位置,如果全走一遍没有,再把小孩在每个房间玩得最多的地方或各个家俱的下面找一找,如果还是没有,那看一下每个房间的抽屉,这样一步步扩大查找的范围,直到找到为止。事实上,我在全屋查找的第二遍时就在抽水马桶后面的地板上找到了。
如果说图的深度优先遍历类似树的前序遍历,那么图的广度优先遍历就类似于树的层序遍历了。

左图是如何转换成右图的?
通过观察,是按照第一级后代来确认下一个层级的。
什么是最小成本?和最小生成树有什么关系?
所谓的最小成本,就是n个顶点,用n-1条边把一个连通图连接起来,并且使得权值的和最小。
最小生成树,就是为了让权重和变成最小。
找连通网的最小生成树,经典的有两种算法,普里姆算法和克鲁斯卡尔算法。
对比两个算法,克鲁斯卡尔算法主要是针对边来展开,边数少时效率会非常高,所以对于稀疏图有很大的优势;而普里姆算法对于稠密图,即边数非常多的情况会更好一些。
最短路径是怎样?
在网图和非网图中,最短路径的含义是不同的。由于非网图它没有边上的权值,所谓的最短路径,其实就是指两顶点之间经过的边数最少的路径;
而对于网图来说,最短路径,是指两顶点之间经过的边上权值之和最少的路径,并且我们称路径上的第一个顶点是源点,最后一个顶点是终点。
显然,我们研究网图更有实际意义,就地图来说,距离就是两顶点间的权值之和。而非网图完全可以理解为所有的边的权值都为1的网。
如何求最短路径?
迪杰斯特拉(Dijkstra)算法可以解决从某个源点到其余各顶点的最短路径问题。
如果你面临需要求所有顶点至所有顶点的最短路径问题时,弗洛伊德(Floyd)算法应该是不错的选择。
AOV 网是什么?
在一个表示工程的有向图中,用顶点表示活动,用弧表示活动之间的优先关系,这样的有向图为顶点表示活动的网,我们称为AOV网(Activity On Vertex Network)。AOV网中的弧表示活动之间存在的某种制约关系。
比如演职人员确定了,场地也联系好了,才可以开始进场拍摄。另外就是AOV网中不能存在回路。刚才已经举了例子,让某个活动的开始要以自己完成作为先决条件,显然是不可以的。
拓扑排序是怎么回事?
所谓拓扑排序,其实就是对一个有向图构造拓扑序列的过程。
构造时会有两个结果,如果此网的全部顶点都被输出,则说明它是不存在环(回路)的AOV网;
如果输出顶点数少了,哪怕是少了一个,也说明这个网存在环(回路),不是AOV网。
一个不存在回路的AOV网,我们可以将它应用在各种各样的工程或项目的流程图中,满足各种应用场景的需要,所以实现拓扑排序的算法就很有价值了。
拓扑排序主要是为解决一个工程能否顺序进行的问题
对AOV网进行拓扑排序的基本思路是:
从AOV网中选择一个入度为0的顶点输出,然后删去此顶点,并删除以此顶点为尾的弧,继续重复此步骤,直到输出全部顶点或者AOV网中不存在入度为0的顶点为止。
查找表的分类有哪些?
查找表按照操作方式来分有两大种:静态查找表和动态查找表。
静态查找表(Static Search Table):只作查找操作的查找表。它的主要操作有:
(1)查询某个“特定的”数据元素是否在查找表中。
(2)检索某个“特定的”数据元素和各种属性。
按照我们大多数人的理解,查找,当然是在已经有的数据中找到我们需要的。静态查找就是在干这样的事情
动态查找表(Dynamic Search Table):在查找过程中同时插入查找表中不存在的数据元素,或者从查找表中删除已经存在的某个数据元素。显然动态查找表的操作就是两个:
(1)查找时插入数据元素。
(2)查找时删除数据元素。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号