
论文查重
论文查重算法
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/SoftwareEngineering2024 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/SoftwareEngineering2024/homework/13136 |
| 这个作业的目标 | 开发个人项目 |
github:https://github.com/0turnsole0/0turnsole0/tree/main/3122004702-task1
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 15 |
| Estimate | 估计这个任务需要多少时间 | 20 | 15 |
| Development | 开发 | 80 | 60 |
| Analysis | 需求分析 (包括学习新技术) | 120 | 100 |
| Design Spec | 生成设计文档 | 40 | 20 |
| Design Review | 设计复审 | 5 | 5 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 5 | 5 |
| Design | 具体设计 | 30 | 20 |
| Coding | 具体编码 | 15 | 15 |
| Code Review | 代码复审 | 5 | 5 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 30 |
| Reporting | 报告 | 50 | 40 |
| Test Repor | 测试报告 | 10 | 10 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 10 | 10 |
| 合计 | 450 | 360 |
设计与实现
Check完成论文查重功能
- mian函数为主要的执行函数
- generateWordsFrequency用来生成单词频率映射
- calculateSimilarity用来计算相似度
- writeToFile用来将结果写入文件
CheckTest用于单元测试
性能改进
这个进行优化或可能存在性能不足的地方有以下几点:
- 读取文件操作:程序中使用的文件读取操作是同步的,也就是阻塞的。如果读取大文件,这可能会导致程序在等待操作完成时无法进行其他任务。为此,可以将文件读取操作改为异步的,例如使用Java NIO(非阻塞I/O)库。
- 计算相似度:在计算文件的单词频率向量大小时,程序对每个文件都进行了完全独立的计算。这在文件数量增加、复杂性增加时可能会成为性能瓶颈。可以考虑使用并行处理方法,如Java流(Java 8 及以后)中并行流的使用,让计算任务在多核心的机器上并行执行,从而提高性能。
- 错误处理:当前的错误处理方式只是简单的输出堆栈信息。这并不是一个很好的做法,可能需要更复杂的错误处理和恢复策略。对于文件操作,应当处理各种可能的异常,例如文件未找到、无法读取、无法写入等等。对于其他可能的异常(如算法异常、类型转换异常、资源耗尽等),也应当有相应的处理方式。
- 代码重用和模块化:代码中有几个重复的代码块,例如读取文件和处理IO异常的部分。这些部分可以被重构为单独的方法,以增强代码的重用性和可读性。
- 对于HashMap,在并发环境下可能会存在线程安全的问题。如果需要提供线程安全性,可以考虑使用并发集合类,比如ConcurrentHashMap。
单元测试
测试函数,主要针对论文查重的三个方法进行测试


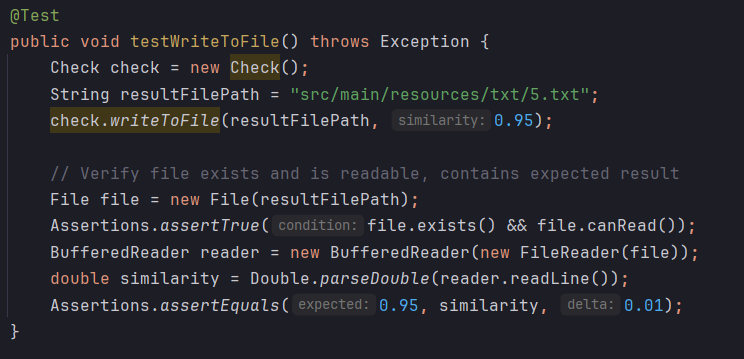
单元测试使用的工具是Junit,需要导入相关的依赖
覆盖率

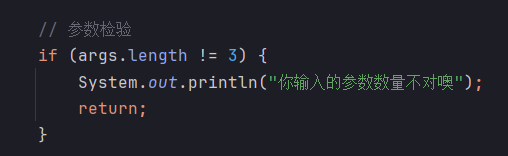
异常处理
检查输入的文件数量是否正常
posted on 2024-03-14 13:59 0turnsole0 阅读(13) 评论(0) 编辑 收藏 举报

