记一次不正经的爬虫学习经历
0x00前言
大家好,相信点进来看的小伙伴都对爬虫非常感兴趣(绝对不是因为封面![]() ), 博主也是一样的。 最近由于疫情的原因,大家都不能出门玩耍,所以博主准备分享一些有趣的学习经历给大家。
), 博主也是一样的。 最近由于疫情的原因,大家都不能出门玩耍,所以博主准备分享一些有趣的学习经历给大家。
昨天,博主逛B站时偶然(非常偶然~)发现了一个不同寻常的教程
揍是下面这个
教程链接:
https://www.bilibili.com/video/av75562300?from=search&seid=5460455189191720379
学习完之后,可以说是收获满满啊。 所以今天也给大家安利一下这个教程,顺便也整理一下自己学的知识。
0x01准备工作
目标站点:
https://www.vmgirls.com
robots.txt
为了避免不必要的麻烦,在我们开始爬取某个网站时第一个要关注的事情是这个网站有哪些页面或者哪些信息允许我们爬取的。 那么我们如何知道网站有哪些东西是可以爬取的呢?
这里我们要了解一个协议---Robots协议
Robots协议(又称爬虫协议或者机器人协议)是网站告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
Robots协议是国际互联网界通行的道德规范,这也就是说Robots协议是一个行业的潜规则,并不是什么法律规定。
但是遵守这个潜规则能够让我们避免很多麻烦。
在这里给大家附一个GITHUB链接,这个项目收录了所有中国大陆爬虫开发者涉诉与违规相关的新闻、资料与法律法规。
https://github.com/HiddenStrawberry/Crawler_Illegal_Cases_In_China
那么我们如何查看一个网站的Robots协议呢?
要想解决这个问题我们得先知道爬虫协议是以什么形式存在的。
Robots协议是以一个robots.txt文件的形式存放在网站的根目录的,在这个文件中会明确的标出有哪些页面或信息是可以爬取的。
如果网站中不存在这个文件那么我们可以爬取所有的没有被口令保护的页面。
下面是今天我们的目标网站的协议内容

因为我们今天是爬取这个网站的图片,所以根据这个信息就可以判断我们今天的行为是被网站允许的。 所以大家可以放心操作。
0x02页面下载与解析
排除了法律风险后我们开始正式的工作
第一步 分析目标页面
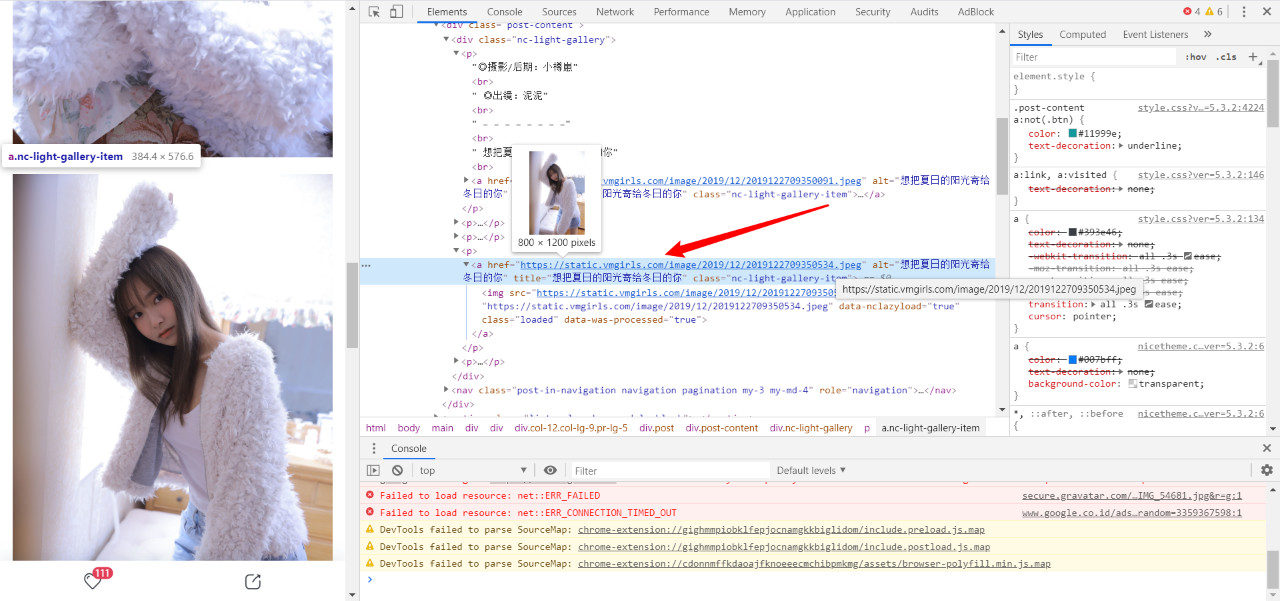
这一步的目的是找到我们要下载图片的资源链接所在的标签。
打开我们的目标网站后,首先要定位到我们想要爬取的那个页面。 下面我们以这个页面为例。


按F12查看网页的源代码,找到图片所在的标签,复制下来
第二步 下载目标页面
我们先通过requests模块把页面下载下来代码如下:
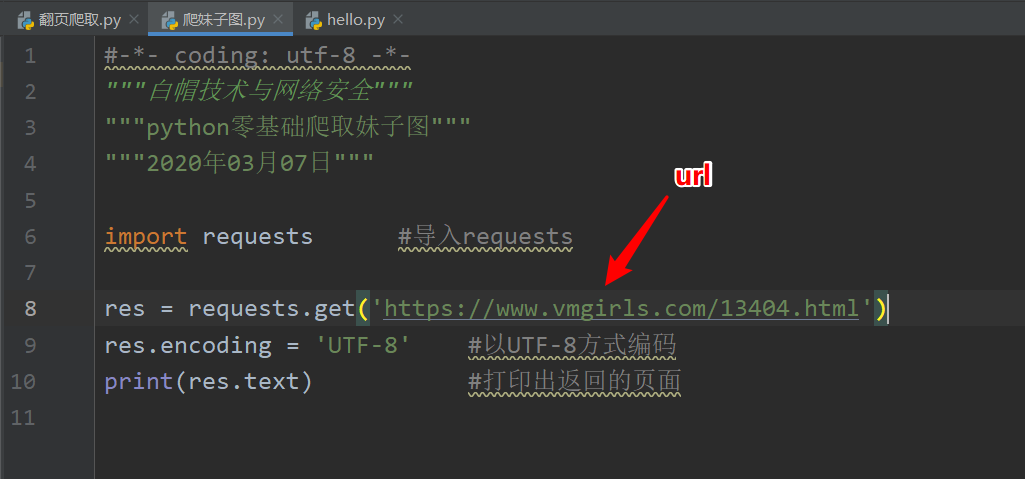
返回的结果如下:

不出意外的网站给我们返回了403页面。
这种问题很常见,因为网站检测到我们是通过python访问的,所以直接拒绝了我们的访问。
我们先查看一下请求头。
代码如下:
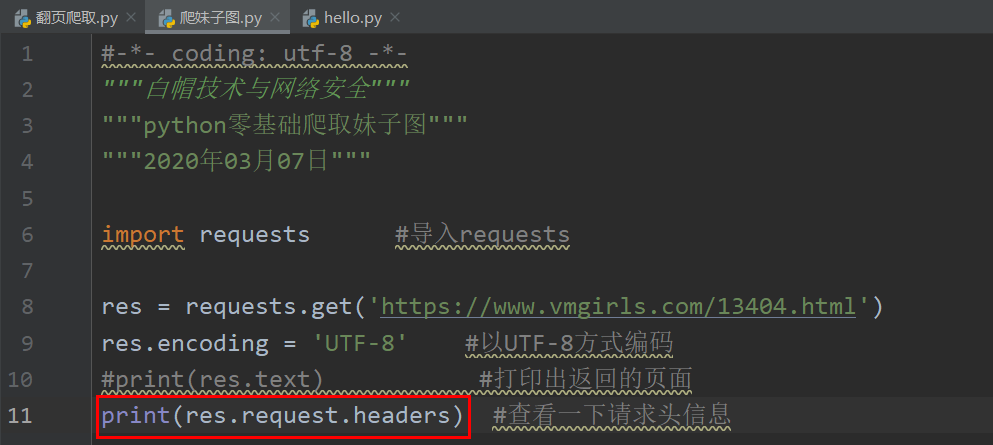
返回结果:

(不知道这个知识点的可以看我的另一篇文章《一篇有点长的HTTP协议详解》
链接:
https://blog.csdn.net/weixin_46245322/article/details/104416654)
在这里可以看到我们的User-Agent字段 告诉了人家我们是通过python访问的。 我的解决方法就是伪造一个User-Agent字段。 要想伪造我们就得先知道正常访问请求的User-Agent字段长啥样。
具体操作步骤如下:
-
浏览器页面按F12
-
选择Network栏
-
刷新一下页面
-
点击一个HTML文件
-
在Headers里找到User-Agent字段的信息
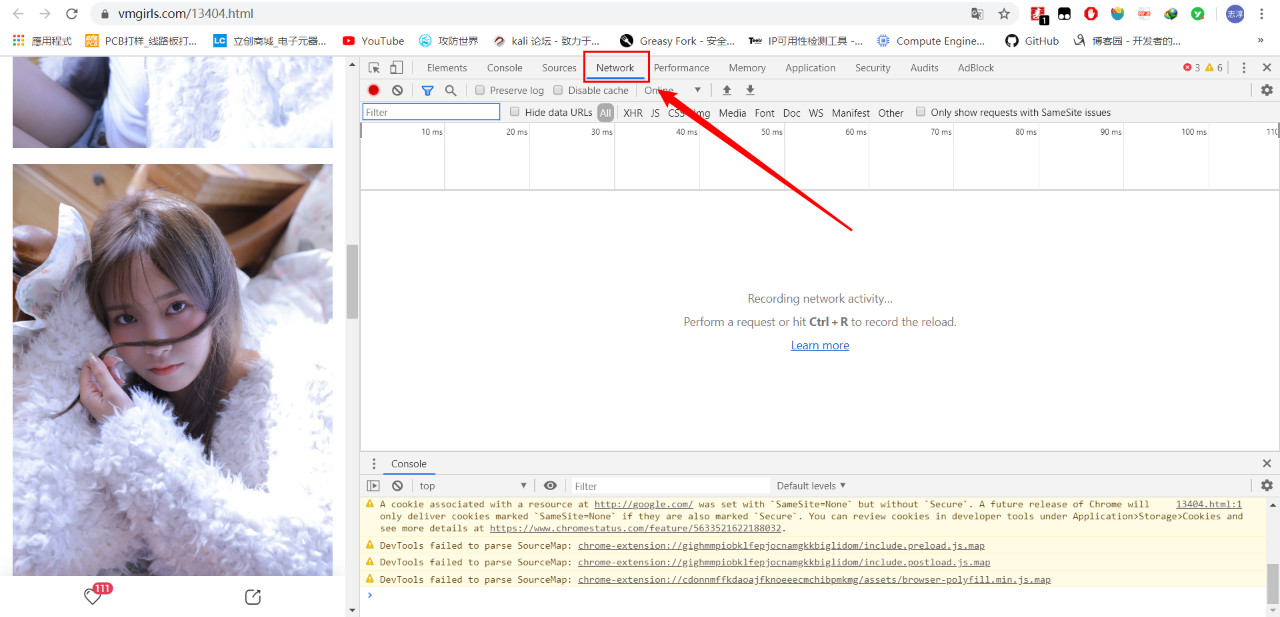

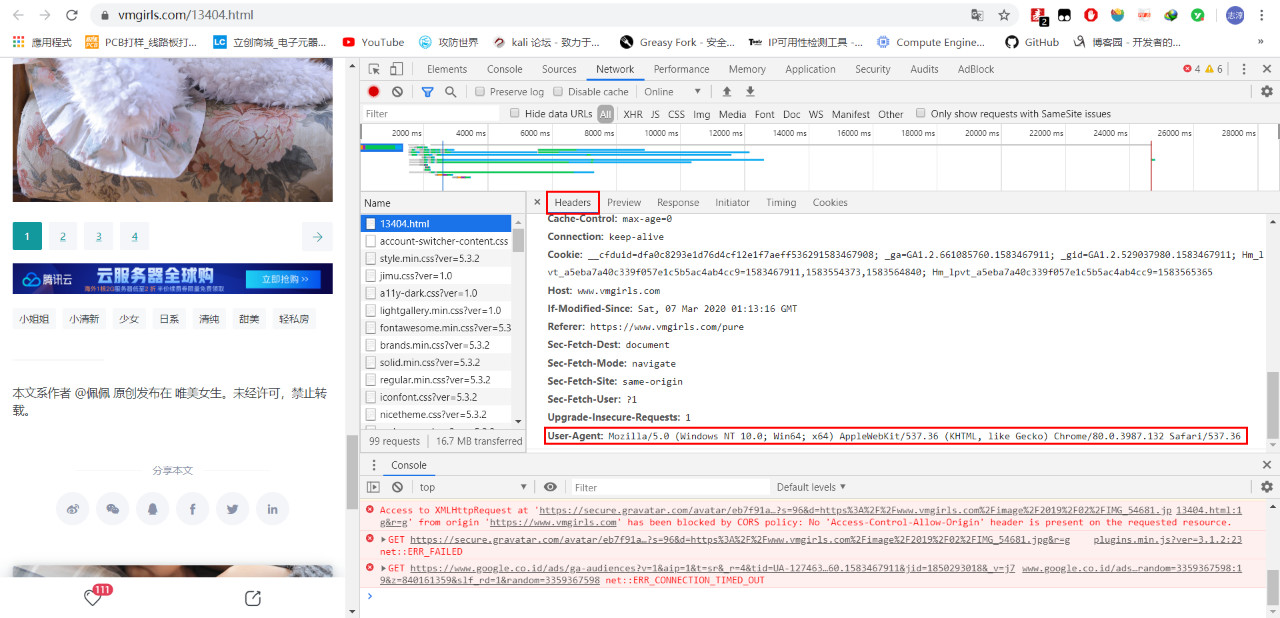
拿到这个信息后我们再回到我们的代码中,我们在请求中加入自己伪造的字段信息:

返回结果:
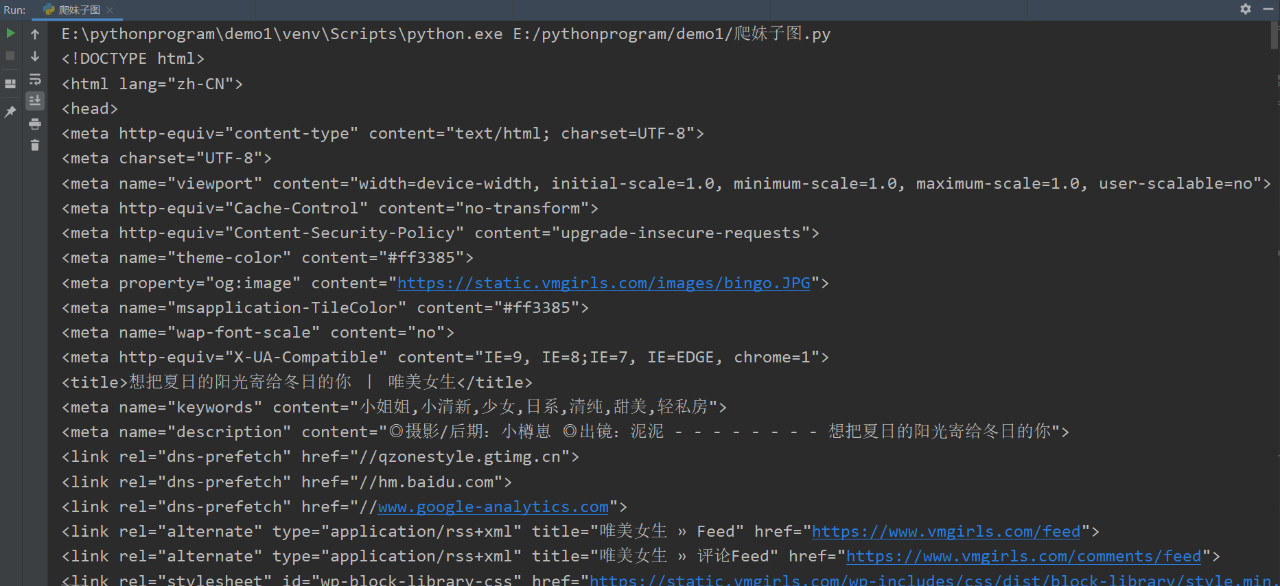
到这里我们已经可以成功把页面下载下来
第三步正则匹配获取图片链接
利用re模块进行正则匹配
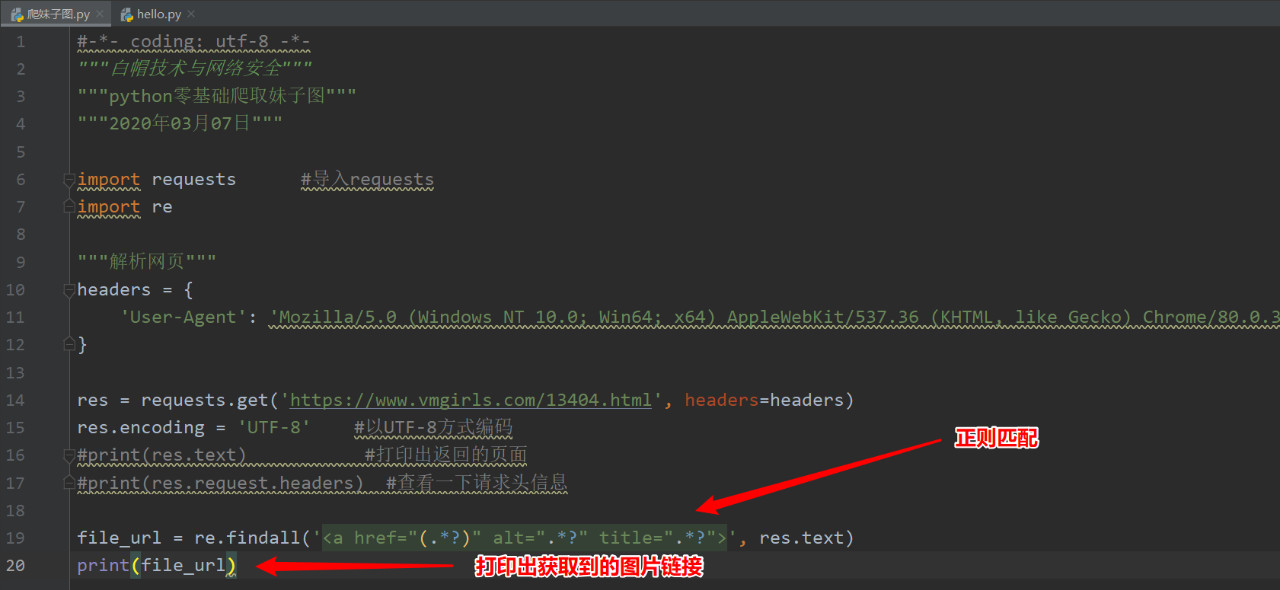
成功获取到图片链接:

0x03下载小姐姐美图
通过以上步骤我们已经可以获得图片的链接,下面我们就可以着手下载图片:
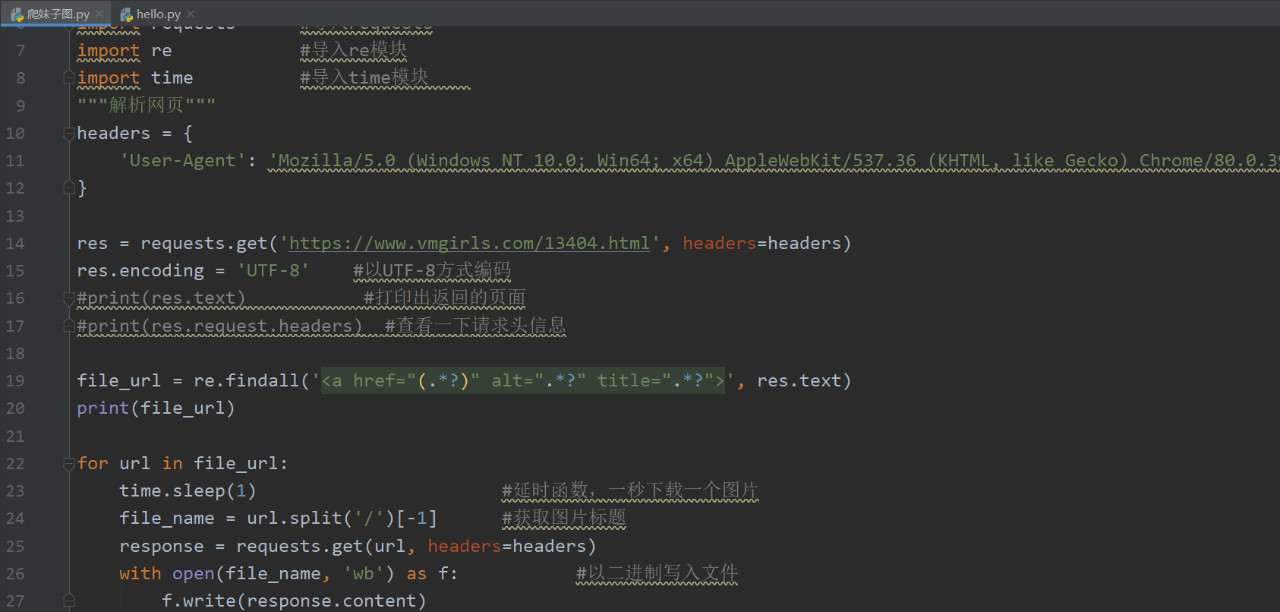
这里我们要重点说一下,我们要在循环里加一个time.sleep(1)函数,加这个函数是防止把网站爬崩溃了。
下载完成
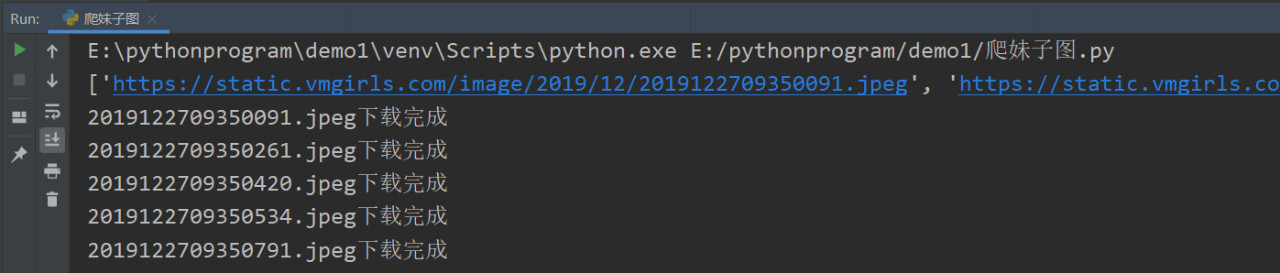
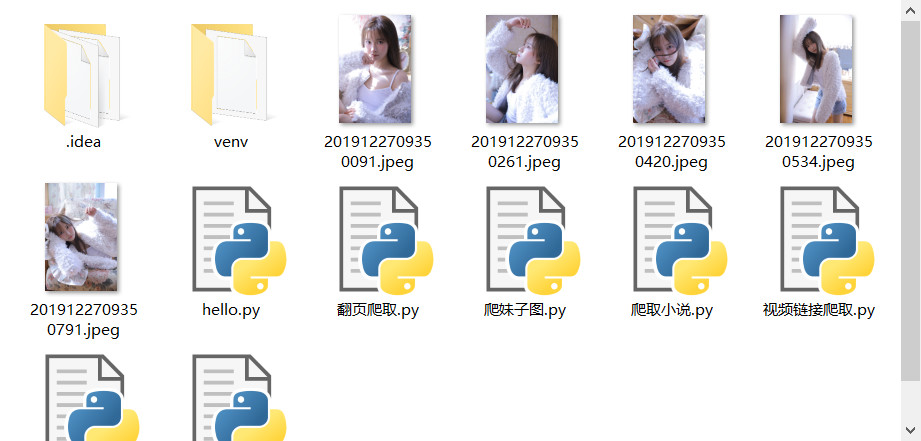
0x04总结
写到这里我们已经可以
把小姐姐下载下来了,但是这还远远不够,我们现在下载的图片只是随意的分布在程序的目录里,如何实现下载文件时自动创建文件夹并把图片存到里面呢?
并且我们下载的只是当前页面的图片,如何实现下载下一页的文件呢?
这就有待于小伙伴们自学去解决啦~
0x05代码
#-*- coding: utf-8 -*- """白帽技术与网络安全""" """python零基础爬取妹子图""" """2020年03月07日""" import requests #导入requests import re #导入re模块 import time #导入time模块 """解析网页""" headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36' } res = requests.get('https://www.vmgirls.com/13404.html', headers=headers) res.encoding = 'UTF-8' #以UTF-8方式编码 #print(res.text) #打印出返回的页面 #print(res.request.headers) #查看一下请求头信息 file_url = re.findall('<a href="(.*?)" alt=".*?" title=".*?">', res.text) print(file_url) for url in file_url: time.sleep(1) #延时函数,一秒下载一个图片 file_name = url.split('/')[-1] #获取图片标题 response = requests.get(url, headers=headers) with open(file_name, 'wb') as f: #以二进制写入文件 f.write(response.content) print(file_name+'下载完成')

本作品采用知识共享署名-非商业性使用 4.0 国际许可协议进行许可。
更多技术干货请关注“白帽技术与网络安全”公众号,限时免费领取海量视频教程


 浙公网安备 33010602011771号
浙公网安备 33010602011771号