汽车交易情况分析及价格预测2_特征工程
一、特征构造
# 训练集和测试集放在一起,方便构造特征 train['train']=1 test_data['train']=0 data = pd.concat([train, test_data], ignore_index=True, sort=False)
增加新特征:使用时间
data['used_time'] = (pd.to_datetime(data['creatDate'], format='%Y%m%d', errors='coerce') -pd.to_datetime(data['regDate'], format='%Y%m%d', errors='coerce')).dt.days
增加新特征:城市
data['city'] = data['regionCode'].apply(lambda x : str(x)[:-3])

增加新特征:某品牌的销售统计量
train_gb = train_data.groupby("brand") all_info = {} for kind, kind_data in train_gb: info = {} kind_data = kind_data[kind_data['price'] > 0] info['brand_amount'] = len(kind_data) info['brand_price_max'] = kind_data.price.max() info['brand_price_median'] = kind_data.price.median() info['brand_price_min'] = kind_data.price.min() info['brand_price_sum'] = kind_data.price.sum() info['brand_price_std'] = kind_data.price.std() info['brand_price_average'] = round(kind_data.price.sum() / (len(kind_data) + 1), 2) all_info[kind] = info brand_fe = pd.DataFrame(all_info).T.reset_index().rename(columns={"index": "brand"}) data = data.merge(brand_fe, how='left', on='brand')

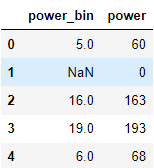
数据分桶
bin = [i*10 for i in range(31)] data['power_bin'] = pd.cut(data['power'], bin, labels=False) data[['power_bin', 'power']].head()
# 删掉原始数据 data = data.drop(['SaleID','creatDate', 'regDate', 'regionCode'], axis=1) print(data.shape) data.columns

二、数据导出
不同模型对数据集的要求不同
用于树模型
data.to_csv('data_for_tree.csv', index=0)
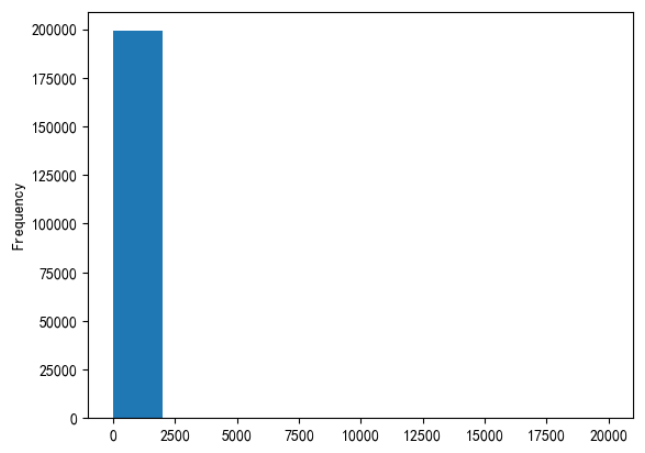
用于LR NN 之类的模型
#观察power的分布 data['power'].plot.hist()
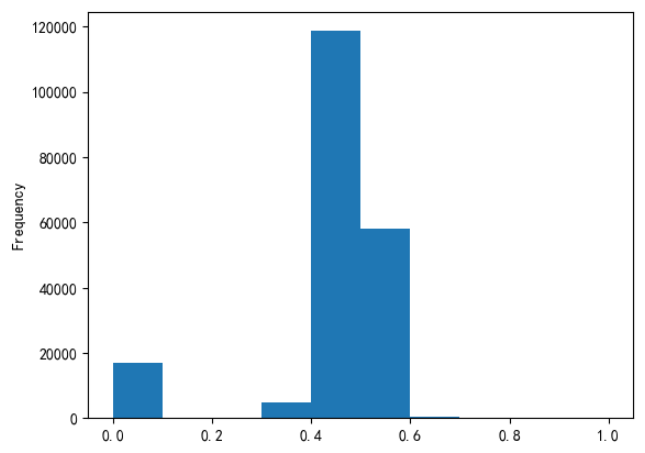
#对其取 log,做归一化 from sklearn import preprocessing min_max_scaler = preprocessing.MinMaxScaler() data['power'] = np.log(data['power'] + 1) data['power'] = ((data['power'] - np.min(data['power'])) / (np.max(data['power']) - np.min(data['power']))) data['power'].plot.hist()
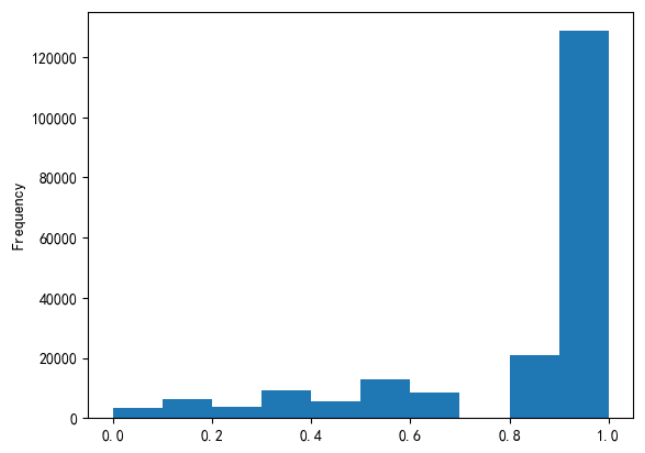
# 对km做归一化 data['kilometer'] = ((data['kilometer'] - np.min(data['kilometer'])) / (np.max(data['kilometer']) - np.min(data['kilometer']))) data['kilometer'].plot.hist()
# 对类别特征进行 OneEncoder data = pd.get_dummies(data, columns=['model', 'brand', 'bodyType', 'fuelType', 'gearbox', 'notRepairedDamage', 'power_bin']) # 这份数据给 LR 使用 data.to_csv('data_for_lr.csv', index=0)


