

汽车交易情况分析及价格预测1_EDA
一、数据简介
二手车交易记录,训练集数据15万条,测试集数据5万条。包括交易ID、汽车交易名称、汽车注册日期、车型编码、汽车品牌、车身类型、汽车已行驶公里、报价类型、二手车交易价格等信息。同时会对name、model、brand和regionCode等信息进行脱敏。
name - 汽车编码 regDate - 汽车注册时间 model - 车型编码
brand - 品牌 bodyType - 车身类型 fuelType - 燃油类型
gearbox - 变速箱 power - 汽车功率 kilometer - 汽车行驶公里
notRepairedDamage - 汽车有尚未修复的损坏 regionCode - 看车地区编码 seller - 销售方
offerType - 报价类型 creatDate - 广告发布时间 price - 汽车价格
v_0', 'v_1', 'v_2', 'v_3', 'v_4', 'v_5', 'v_6', 'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12', 'v_13','v_14'(根据汽车的评论、标签等大量信息得到的embedding向量)【人工构造 匿名特征】
二、数据概况
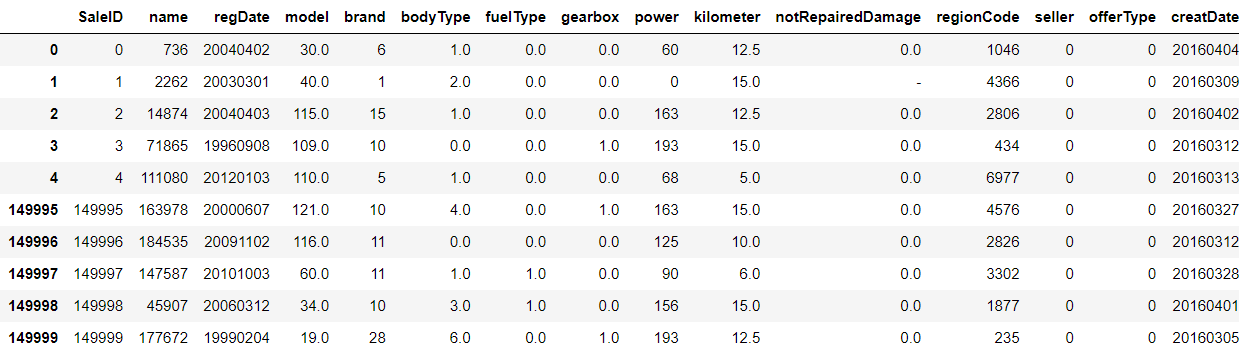
train_data.info()
三、缺失值检测
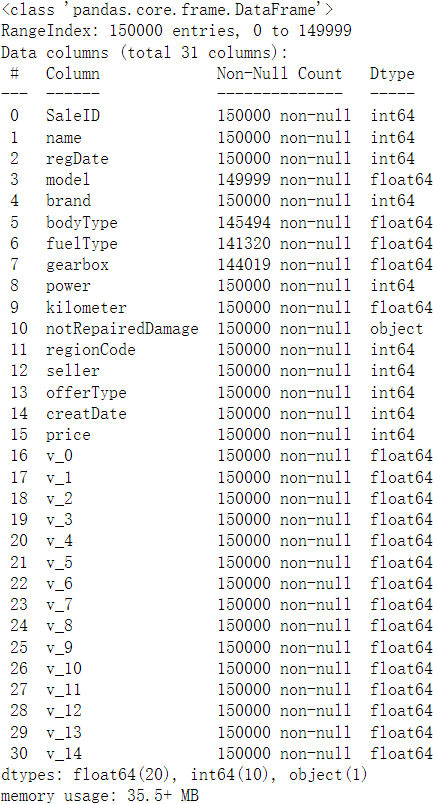
观察缺失值的个数是否真的很大,如果很小一般选择填充,如果使用lgb等树模型可以直接空缺,让树自己去优化,但如果缺失值存在的过多、可以考虑删掉
missing = train_data.isnull().sum() missing = missing[missing > 0] missing.sort_values(inplace=True) missing.plot.bar()
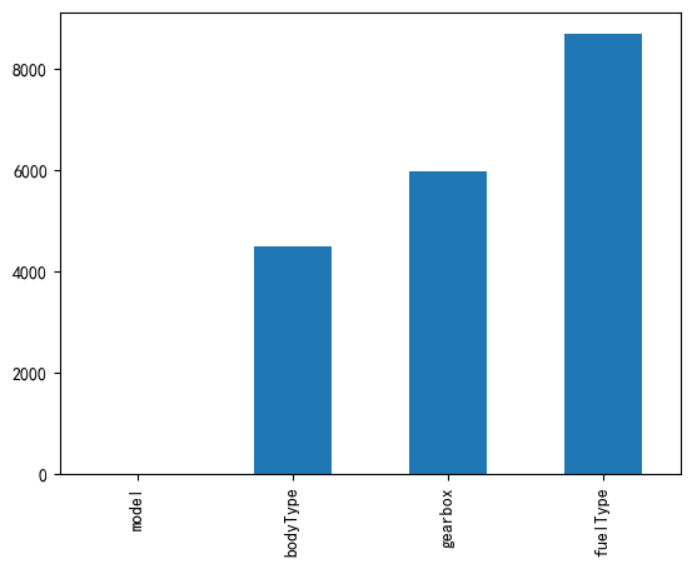
# 缺失值分布图(取出250条数据查看) msno.matrix(train_data.sample(250))
四、异常值检测
train_data['notRepairedDamage'].value_counts()

‘ - ’也为空缺值,因为很多模型对nan有直接的处理,这里我们先不做处理,先替换成nan
train_data['notRepairedDamage'].replace('-', np.nan, inplace=True)
train_data['notRepairedDamage'].value_counts()

以下两个类别特征严重倾斜,不会对预测有什么帮助,故删除
train_data["seller"].value_counts()
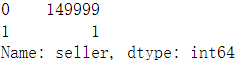
train_data["offerType"].value_counts()
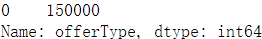
del train_data["seller"] del train_data["offerType"] del test_data["seller"] del test_data["offerType"]
五、预测值的分布
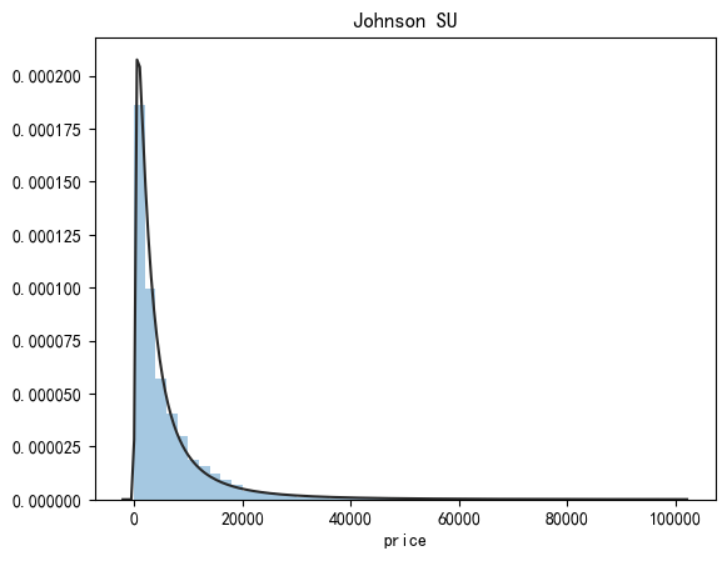
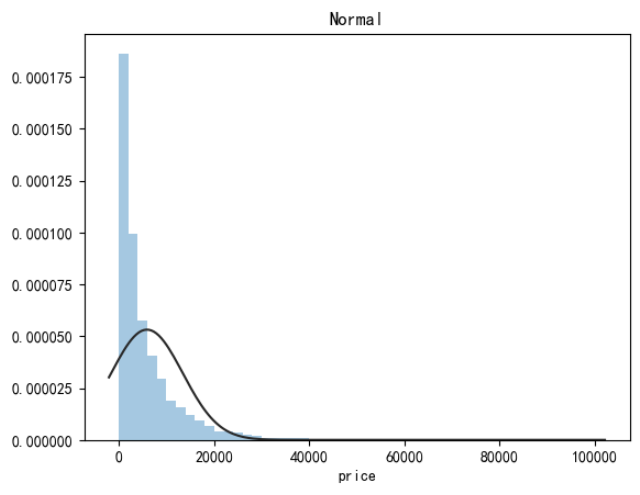
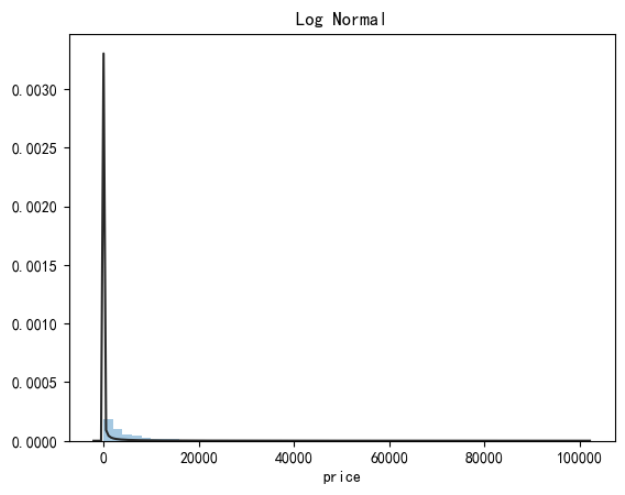
价格不服从正态分布,最佳拟合是无界约翰逊分布

#无界约翰逊分布 import scipy.stats as st y = train_data['price'] plt.figure(1) plt.title('Johnson SU') sns.distplot(y, kde=False, fit=st.johnsonsu) #正态分布 plt.figure(2) plt.title('Normal') sns.distplot(y, kde=False, fit=st.norm) #对数正态分布 plt.figure(3) plt.title('Log Normal') sns.distplot(y, kde=False, fit=st.lognorm)
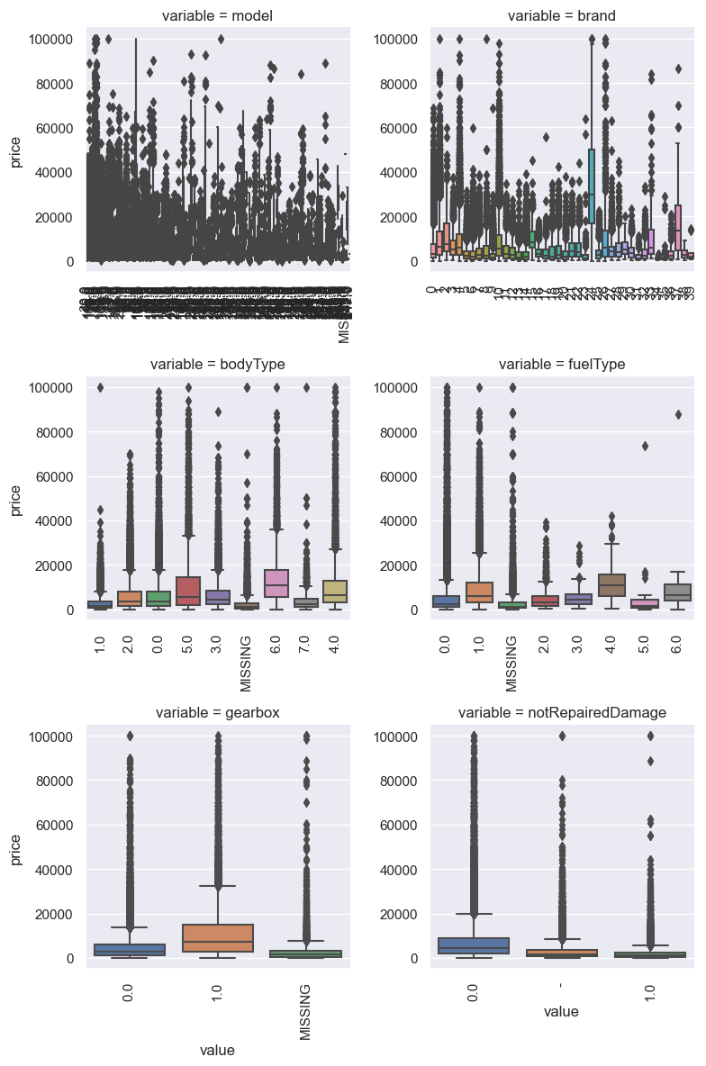
六、类别特征和数字特征分析
numeric_features = ['power', 'kilometer', 'v_0', 'v_1', 'v_2', 'v_3', 'v_4', 'v_5', 'v_6', 'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12', 'v_13','v_14' ]
categorical_features = ['name', 'model', 'brand', 'bodyType', 'fuelType', 'gearbox', 'notRepairedDamage', 'regionCode',]
1.数字特征分析
numeric_features.append('price') numeric_features
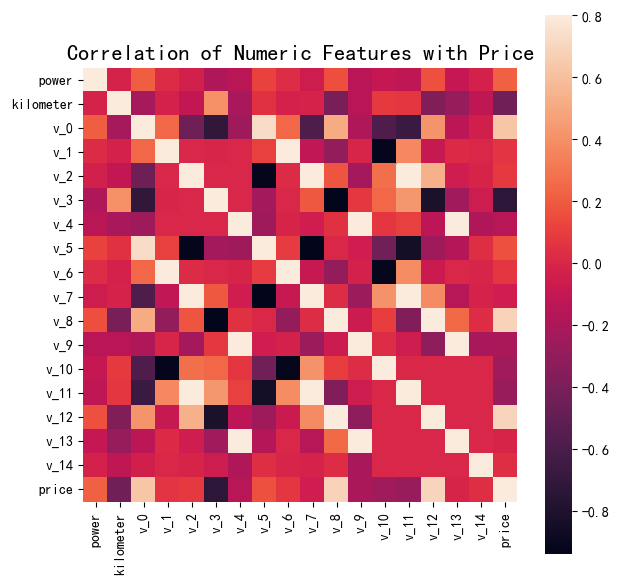
数字特征之间的相关性
price_numeric = train_data[numeric_features] correlation = price_numeric.corr() f , ax = plt.subplots(figsize = (7, 7)) plt.title('Correlation of Numeric Features with Price',y=1,size=16) sns.heatmap(correlation,square = True, vmax=0.8)
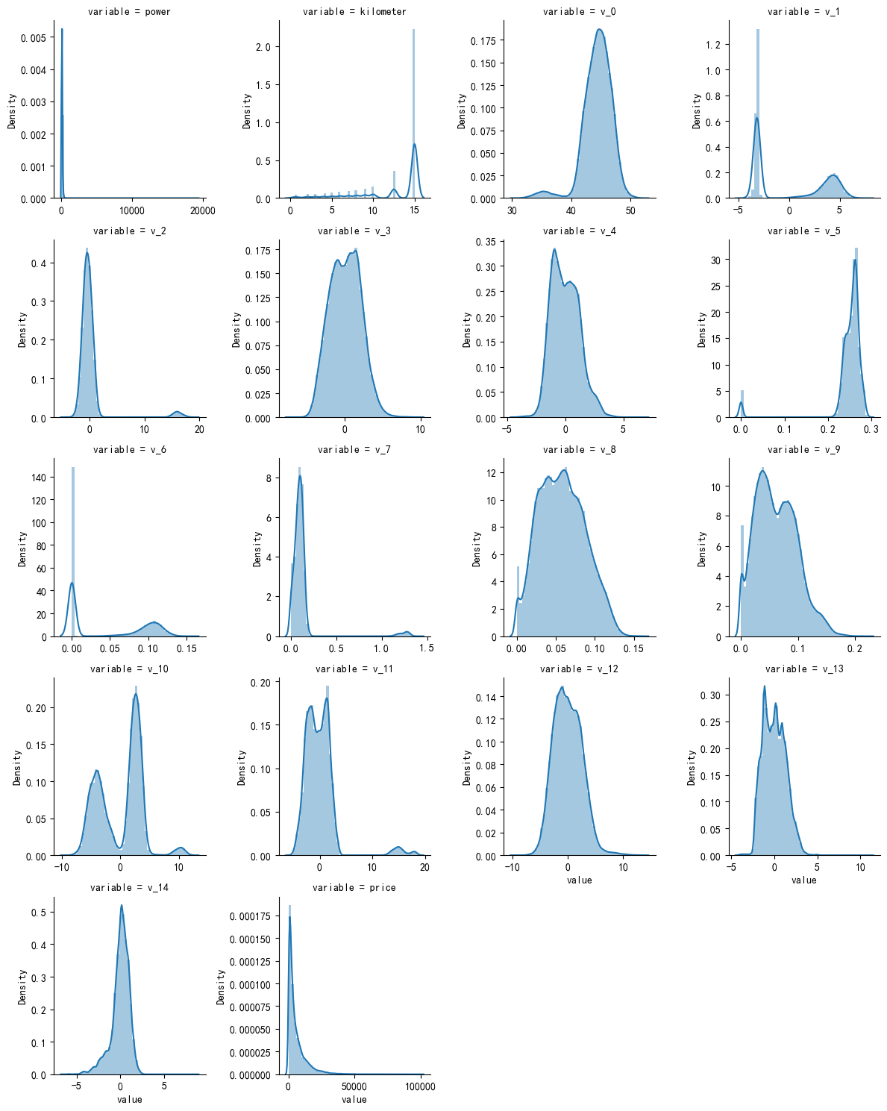
每个数字特征的分布
f = pd.melt(train_data, value_vars=numeric_features) g = sns.FacetGrid(f, col="variable", col_wrap=4, sharex=False, sharey=False) g = g.map(sns.distplot, "value")
2.类别特征分析
类别特征箱形图可视化



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY