AC自动机
前置
掌握KMP、trie树、了解状态机、自动机。
AC自动机
先回顾一下KMP算法:通过next数组快速匹配模式串和匹配串,但多个模式串该怎么办呢?
然后考虑字典树:将字典中每个词加入trie树,然后匹配文章。但这样的匹配需要一定的分隔符,往往难以取到连句的中间单词。
比如:heis ,由于没分隔,通过设计可以取到he,但取不到is。
AC自动机简单直观来说是在trie树上做KMP,用于解决多个模式串在文章中的匹配。
将模式串加入字典树之后建立fail数组,解决失配时状态转移,或者后缀多匹配。
有限自动机(DFA)
是有限状态机的一种特殊情况,简单来讲就是一张有向图网络,每个点代表一个状态,每条有向边代表一种状态转移。
不多赘述,可自行搜索,直奔主题(doge)
Fail数组
之前说了AC自动机是在trie树上做KMP,将模式串加入trie树,失配之后像KMP一样找最长后缀,因此需要fail数组充当next数组。
trie树,实际上是一张图,也是一个状态机,每个节点代表一个单词前缀序列,可以通过下一个字母匹配来转移。
在传统trie树匹配中,失配就是直接回到原点,而AC自动机实际上是将trie树改变结构,面对失配通过fail指针跳转更加灵活。
fail指针如何构建?
-
构建好trie树
-
bfs遍历trie树
在遍历过程中,对于每个节点x的子节点trie[x] [y]
如果不为空,则fail[trie[x] [y]] = trie[fail[x]] [y]
如果为空,则转移到fail[x]的子节点去,就是trie[x] [y] = trie[fali[x] [y]
-
注意:在bfs遍历的时候初始是将0节点的子节点加入队列,如果一开始只是0入队,会导致每个节点fail指向自己,就像kmp的next数组如果从第一个开始处理,每个next[i] = i,导致错误。
这一部分的理解可以结合后面的完整代码。
为什么这样构建
这就是AC自动机最关键的部分。
想象一下,我们匹配过程就是在trie树上游走,如果下一个字母节点对应,则向下游走,如果不对应,我们走到后缀一致。
每个对应节点的后缀一定会与他父节点的后缀相关,如果父节点的失配转移到的后缀节点有对应相同字母的子节点,那这个节点一定是对应节点的后缀。
而对空节点的处理,则是为了简化状态,这里失配,不需要通过fail转移,直接转移到后缀的子节点。
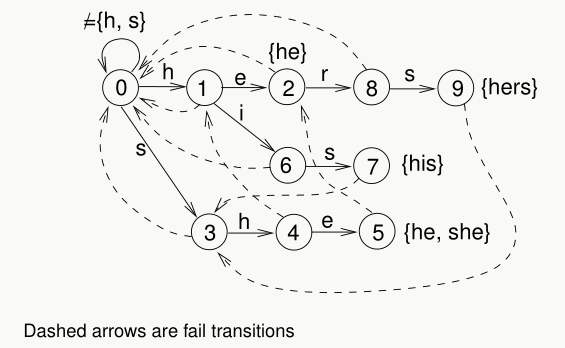
可以参考一下这张图片理解。
匹配
文章根据每个字母在自动机上做状态转移,由于空节点被简化处理,因此转移完全不需要fail数组,直接按节点转移。但匹配过程不要忘记了fail数组跳转得到的匹配后缀。
代码
#include <bits/stdc++.h>
using namespace std;
char s[1000010];
int tr[2000010][30];
int cnt = 0;
int e[2000010];
int fail[2000010];
//构建trie树
void insert(char *s)
{
int pos = 0;
for (int i = 0; s[i]; ++i)
{
if (!tr[pos][s[i] - 'a'])
tr[pos][s[i] - 'a'] = ++cnt;
pos = tr[pos][s[i] - 'a'];
}
e[pos]++;
}
//bfs构建fail
queue<int> q;
void build()
{
for (int i = 0; i < 26; ++i)
if (tr[0][i])
q.push(tr[0][i]);
while (!q.empty())
{
int x = q.front();
q.pop();
for (int i = 0; i < 26; ++i)
if (tr[x][i])
fail[tr[x][i]] = tr[fail[x]][i], q.push(tr[x][i]);
else
tr[x][i] = tr[fail[x]][i];
}
}
//匹配
int match(char *s)
{
int ans = 0;
int pos = 0;
for (int i = 0; s[i]; ++i)
{
pos = tr[pos][s[i] - 'a'];
//遍历相同后缀匹配
for (int j = pos; j && e[j] != -1; j = fail[j])
ans += e[j],
e[j] = -1;
}
return ans;
}
int main()
{
int n;
cin >> n;
for (int i = 1; i <= n; ++i)
cin >> s, insert(s);
build();
cin >> s;
cout << match(s);
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号