法务咨询问题分类
法务咨询问题分类
今天成功运行了法务咨询问题分类的代码;
问题模型: 法务咨询数据库一共有20万条训练数据,要做的是13类型咨询问题多分类问题.本项目采用的方式为:
| 训练数据规模 | 测试集规模 | 模型 | 训练时长 | 训练集准确率 | 测试集准确率 |
|---|---|---|---|---|---|
| 4W | 1W | CNN | 15*20s | 0.984 | 0.959 |
| 4W | 1W | LSTM | 51*20s | 0.838 | 0.717 |
3, 效果: 执行 python question_classify.py
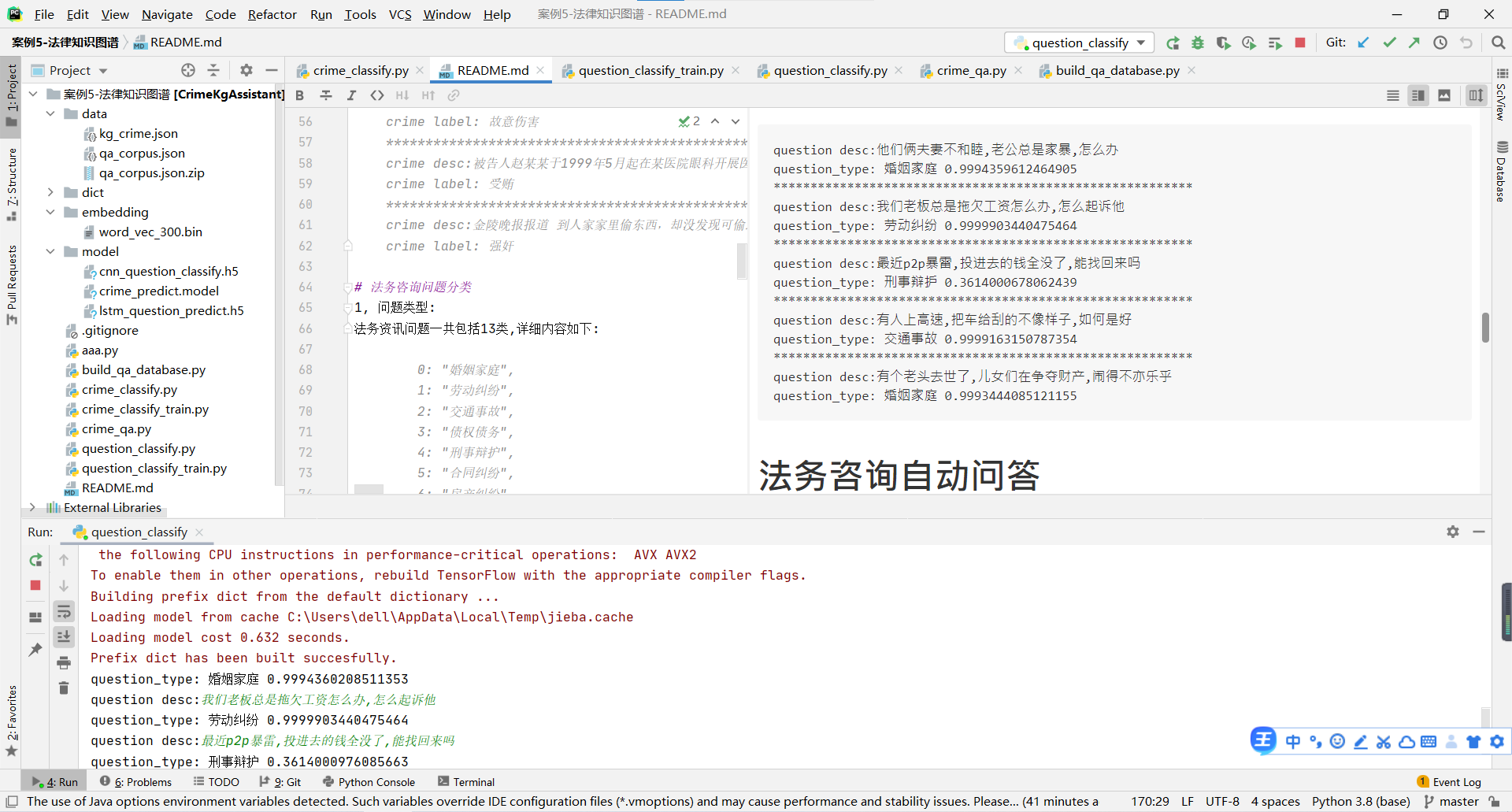
question desc:他们俩夫妻不和睦,老公总是家暴,怎么办
question_type: 婚姻家庭 0.9994359612464905
*********************************************************
question desc:我们老板总是拖欠工资怎么办,怎么起诉他
question_type: 劳动纠纷 0.9999903440475464
*********************************************************
question desc:最近p2p暴雷,投进去的钱全没了,能找回来吗
question_type: 刑事辩护 0.3614000678062439
*********************************************************
question desc:有人上高速,把车给刮的不像样子,如何是好
question_type: 交通事故 0.9999163150787354
*********************************************************
question desc:有个老头去世了,儿女们在争夺财产,闹得不亦乐乎
question_type: 婚姻家庭 0.9993444085121155
运行过程中会报各种各样的错误在网上查询就好了
下面是代码部分:
#!/usr/bin/env python3
# coding: utf-8
# File: question_classify.py
# Author: lhy<lhy_in_blcu@126.com,https://huangyong.github.io>
# Date: 18-11-11
import os
import tensorflow
import numpy as np
import jieba.posseg as pseg
from keras.models import Sequential, load_model
from keras.layers import Conv1D, GlobalAveragePooling1D, MaxPooling1D, Dense, Dropout, LSTM, Bidirectional
class QuestionClassify(object):
def __init__(self):
self.label_dict = {
0: "婚姻家庭",
1: "劳动纠纷",
2: "交通事故",
3: "债权债务",
4: "刑事辩护",
5: "合同纠纷",
6: "房产纠纷",
7: "侵权",
8: "公司法",
9: "医疗纠纷",
10: "拆迁安置",
11: "行政诉讼",
12: "建设工程"
}
cur = '/'.join(os.path.abspath(__file__).split('/')[:-1])
self.embedding_path = os.path.join(cur, 'embedding/word_vec_300.bin')
self.embdding_dict = self.load_embedding(self.embedding_path)
self.max_length = 60
self.embedding_size = 300
self.lstm_modelpath = 'model/lstm_question_classify.h5'
self.cnn_modelpath = 'model/cnn_question_classify.h5'
return
'''加载词向量'''
def load_embedding(self, embedding_path):
embedding_dict = {}
count = 0
for line in open(embedding_path,encoding='utf-8'):
line = line.strip().split(' ')
if len(line) < 300:
continue
wd = line[0]
vector = np.array([float(i) for i in line[1:]])
embedding_dict[wd] = vector
count += 1
if count % 10000 == 0:
print(count, 'loaded')
print('loaded %s word embedding, finished' % count, )
return embedding_dict
'''对文本进行分词处理'''
def seg_sent(self, s):
wds = [i.word for i in pseg.cut(s) if i.flag[0] not in ['w', 'x']]
return wds
'''基于wordvector,通过lookup table的方式找到句子的wordvector的表示'''
def rep_sentencevector(self, sentence):
word_list = self.seg_sent(sentence)[:self.max_length]
embedding_matrix = np.zeros((self.max_length, self.embedding_size))
for index, wd in enumerate(word_list):
if wd in self.embdding_dict:
embedding_matrix[index] = self.embdding_dict.get(wd)
else:
continue
len_sent = len(word_list)
embedding_matrix = self.modify_sentencevector(embedding_matrix, len_sent)
return embedding_matrix
'''对于OOV词,通过左右词的词向量作平均,作为词向量表示'''
def modify_sentencevector(self, embedding_matrix, len_sent):
context_window = 2
for indx, vec in enumerate(embedding_matrix):
left = indx - context_window
right = indx + context_window
if left < 0:
left = 0
if right > len(embedding_matrix) - 1:
right = -2
context = embedding_matrix[left:right + 1]
if vec.tolist() == [0] * 300 and indx < len_sent:
context_vector = context.mean(axis=0)
embedding_matrix[indx] = context_vector
return embedding_matrix
'''对数据进行onehot映射操作'''
def label_onehot(self, label):
one_hot = [0] * len(self.label_dict)
one_hot[int(label)] = 1
return one_hot
'''构造CNN网络模型'''
def build_cnn_model(self):
model = Sequential()
model.add(Conv1D(64, 3, activation='relu', input_shape=(self.max_length, self.embedding_size)))
model.add(Conv1D(64, 3, activation='relu'))
model.add(MaxPooling1D(3))
model.add(Conv1D(128, 3, activation='relu'))
model.add(Conv1D(128, 3, activation='relu'))
model.add(GlobalAveragePooling1D())
model.add(Dropout(0.5))
model.add(Dense(13, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.summary()
return model
'''构造LSTM网络'''
def build_lstm_model(self):
model = Sequential()
model.add(LSTM(32, return_sequences=True, input_shape=(
self.max_length, self.embedding_size))) # returns a sequence of vectors of dimension 32
model.add(LSTM(32, return_sequences=True)) # returns a sequence of vectors of dimension 32
model.add(LSTM(32)) # return a single vector of dimension 32
model.add(Dense(13, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
return model
'''问题分类'''
def predict(self, sent):
model = load_model(self.cnn_modelpath)
sentence_vector = np.array([self.rep_sentencevector(sent)])
res = model.predict(sentence_vector)[0].tolist()
prob = max(res)
label = self.label_dict.get(res.index(prob))
return label,prob
if __name__ == '__main__':
handler = QuestionClassify()
os.environ["CUDA_VISIBLE_DEVICES"] = "3"
while (1):
sent = input('question desc:')
label,prob = handler.predict(sent)
print('question_type:', label,prob)
下面是结果展示:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号