
分治的思想构造决策树----其实就是C4.8(j48)的原理补充
Constructing Decision Tree:决策树可以通过递归来构建,首先选择一个属性作为根节点,并对该属性的每一个值新建一个分支。这样就把案例集合分割成子集,属性的每个值一个子集。如此,就可以对每个分支进行递归重复操作。直到任何时候节点上的所有实例具有相同的分类,才停止树的扩张。
问题a:如何决定先选择哪个属性分类? Which is the best choice?(以weather数据为例)
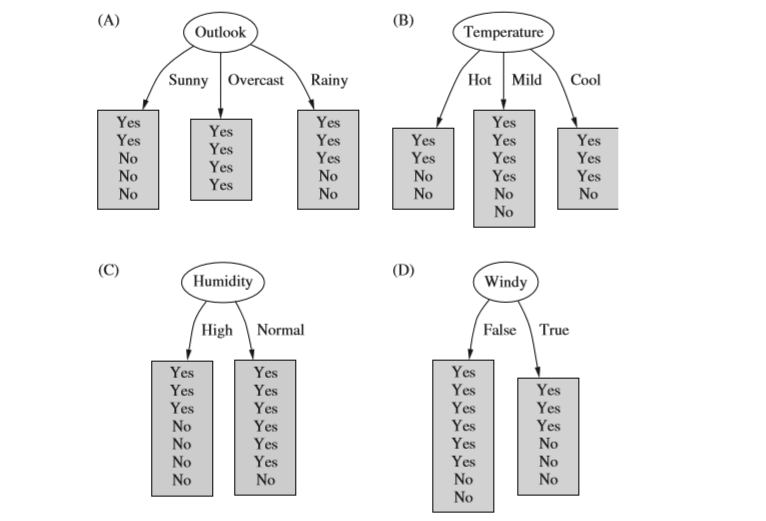
解决方法: 1.所有的yes和no类都在叶子上显示,如果每一片叶子都有唯一的类 yes或者no,那么就不用再分割啦。 因为我们找到了最小树,
如果我们对于每一个节点纯度有评估,我们可以选择那个产生最纯的子节点的属性
2.上图A中每个节点的信息(熵)值如下图,Info([2,3])表示的是Sunny中两个yes,三个no中,要确定一个新的实例是yes类还是no类,所需要的总的信息。
信息熵:表示为了精确的确定一个新的实例是yes类还是no类,所需要的总的信息。

计算分割之后的总的信息熵,包括各个新建的分支。
Info(OutLook)after=5/14*Info([2,3])+4/14*Info([4,0])+5/14*Info([3,2])=0.693bits
分割之前OutLook的信息熵为
Info(OutLook)=Info([9,5])=0.940bits
信息增量
Gain(OutLook)=Info(OutLook)-Info(OutLook)after=0.247bits
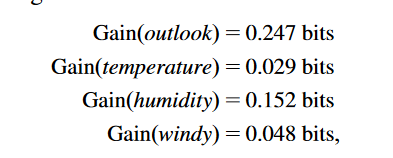
3.从上面图可知outLook属性先分裂,分裂后的图如下:
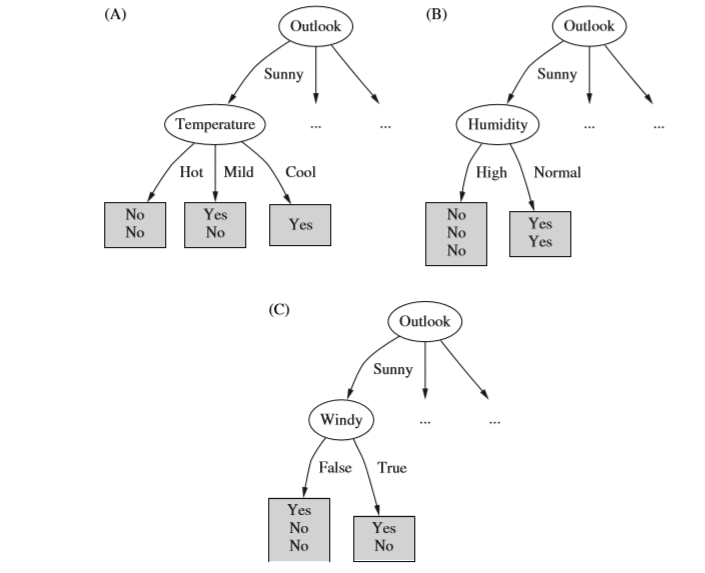
4.一直重复上述步骤,最后得到的决策树为
问题b:多分支属性问题?如果在某个属性中,数据集中的每一个实例都有不同的值,这将产生Overfitting问题?
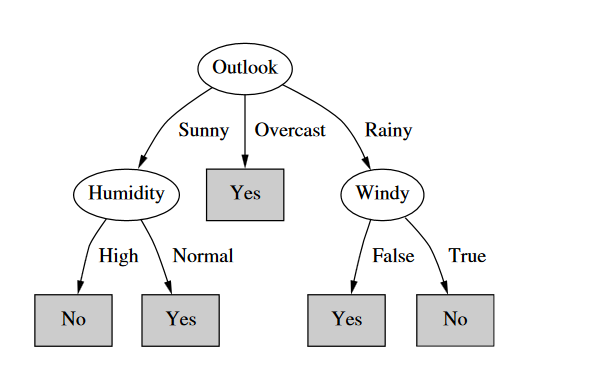
问题描述 1.为天气数据加一个IDCode属性(数据集中的每一个实例都有不同的值),最后产生的决策树如下
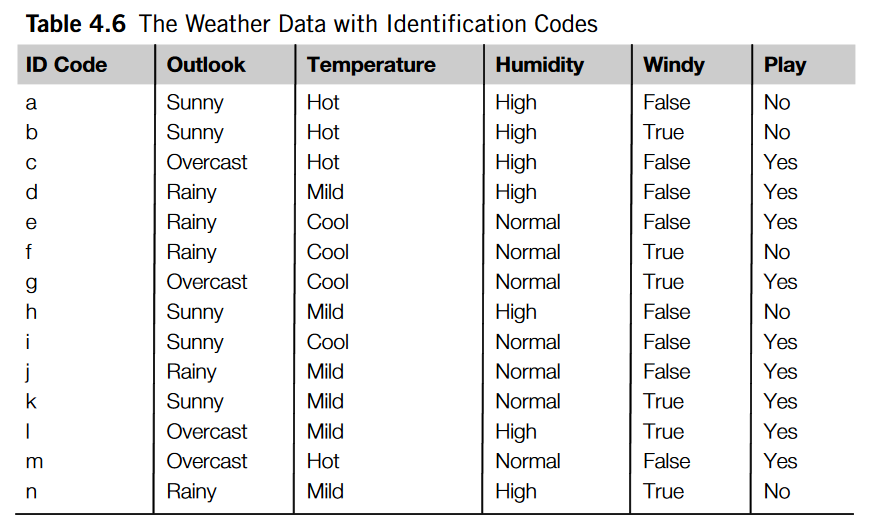
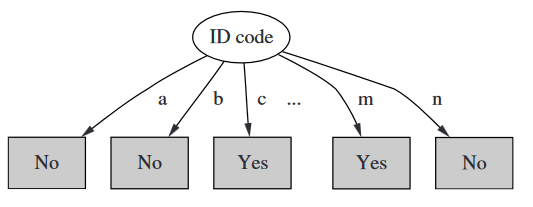
2.可以计算出分裂后的信息熵变成0啦。而最初信息熵为Info([9,5])=0.940bits,最终增益信息绝对是最大的。
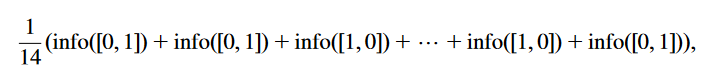
问题解决方法:为解决上面问题,我们引入了固有信息熵的概念,就是指不考虑类时的信息熵。
选择分裂属性时是用Gain ratio=Gain/Split info (增益比例=原增益信息/固有信息熵)
引入此概念后,上述的固有信息熵为 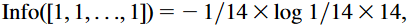
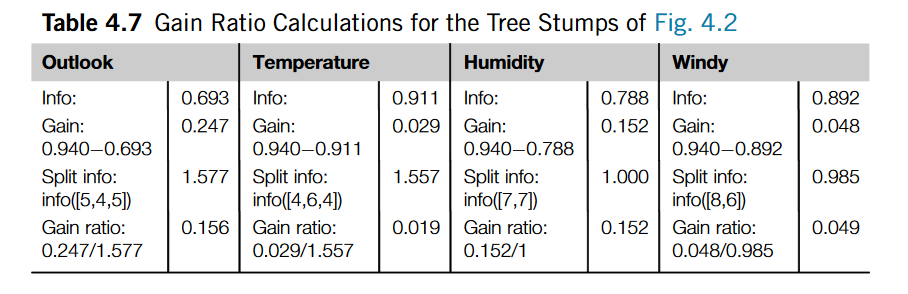
从上面图片可知按照Gain ratio(增益比例)来选,还是先分裂OutLook属性 。 0.156>0.152>0.049>0.029
