
apply() 函数家族介绍
apply() 函数算是R语言中很基础的一个函数,同时还有 sapply() lapply() tapply() 函数精简了 apply() 函数的用法。
apply() 函数是一个很R语言的函数,可以起到很好的替代冗余的for循环的作用,R语言中的循环操作for和while都是基于R语言本身来实现的,而向量操作是基于底层的C语言函数实现的,所以使用apply()函数家族进行向量计算时高性价比的。
apply() 函数可以面向数据框、列表、向量等,同时任何函数都可以传递给 apply() 函数。
apply() 函数
apply()函数的用法如下
apply(X, MARGIN, FUN) 其中: X:一个数据或者矩阵 MARGIN:两个数值1或者2决定对哪一个维度进行函数的计算,MARGIN没有默认值 MARGIN = 1 基于行进行操作 MARGIN = 2 基于列进行操作 MARGIN = c(1, 2) 对行和列都进行操作 FUN:使用哪种操作,内置的函数有mean() medium() sum() min() max() 当然还有用户自定义的函数

lapply() 函数
lapply() 函数中多出来的 l 代表的意思是 list。所以 lapply() 和 apply() 的区别在于输出格式,lapply() 的输出格式是一个 list,所以 lapply() 函数不需要 MARGIN 参数。
lapply(X, FUN)
其中:
X:一个向量或者一个对象
FUN:对X中的每个元素进行操作的函数
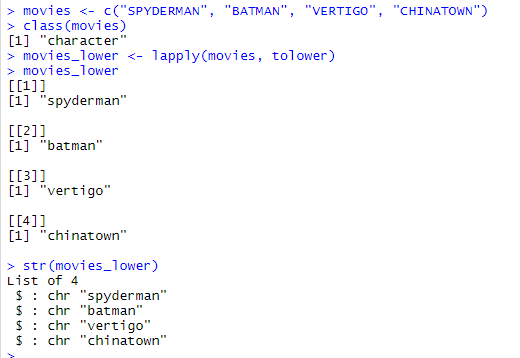
由于 lapply() 的输出结果是以 list 形式给出的,为了方便,我们使用 unlist() 函数进行整合。

sapply() 函数
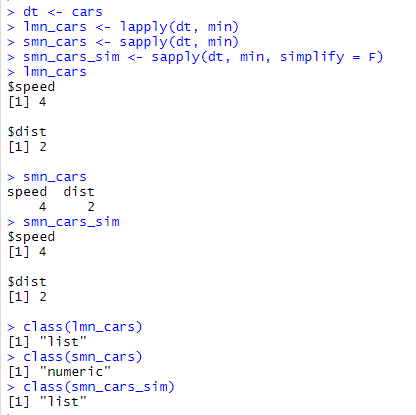
sapply() 函数做的事情和 lapply() 函数是一样的,可以理解为是一个简化的 lapply(),返回的是一个向量(vector),使得对解读更加友好,其使用方法和 lapply() 一样。
sapply() 多了两个参数:
simplify:simplify = T 可以将输出结果数组化;simplify = F 此时输出结果和 lapply() 一样
use.NAMES = T 可以设置字符串的为字符名
tapply() 函数
tapply() 函数是一个拓展函数,可以对一个向量里面进行分组统计操作。
类似于 dplyr 包中的 group_by() + summarise()
tapply(X, INDEX, FUN = NULL)
其中
X:一个对象,一般是向量
INDEX:一个包含分类因子的列表(list)
FUN:对X里面每个元素进行操作的函数
数据分析的一部分工作就是分组进行统计,举例来说,根据一个特性来对一个群体进行分组计算平均值。

使用 dplyr 包的操作如下



 浙公网安备 33010602011771号
浙公网安备 33010602011771号