

Python常用模块
系统os
得到当前工作目录,即当前python脚本的工作目录路径:os.getcwd() 返回指定目录下的所有文件和目录名:os.listdir() 函数用来删除一个文件:os.remove() 删除多个目录:os.removedirs(r"c:\python") 检验给出的路径是否是一个文件:os.path.isfile() 判断是否是绝对路径:os.path.isabs() 检验给出的路径是否真存在:os.path.exists() 返回一个路径的目录名和文件名:os.path.split() 例:os.path.split('/etc/hello.txt') 分离扩展名:os.path.splitext() 例:os.path.splitext('/etc/hello.py') 返回('/etc/hello', '.py')
获取路径名:os.path.abspath() 扩展(__file__打印绝对路径,但是在pycharm中是相对路径。print(os.path.abspath(__file__))
获取文件名:os.path.basename()
运行shell命令:os.system() os.system("top") subprocess.Popen
读取操作系统环境变量HOME的值:os.getenv("HOME")
返回操作系统所有的环境变量:os.environ
设置系统环境变量,仅程序运行时有效:os.environ.setdefault('HOME', '/opt/mysql')
给出当前平台使用的行终止符:os.linesep Windows使用‘\r\n’,Linux 和 Mac使用'\n'
给出正在使用的平台:os.name 对于Windows,返回nt。 而对于Linux/Unix用户,返回‘posix’
重命名:os.rename(old,new)
创建多级目录:os.makedirs(r"/etc/hello")
创建单个目录:os.mkdir(r"/hello")
获取文件属性:os.stat(file)
修改文件权限与时间戳:os.chmod(file)
获取文件大小:os.path.getsize(filename) eg. os.path.getsize("demo05.sh")
结合目录名和文件名:os.path.join(dir,filename) eg. os.path.join("/LianXi","demo.txt")
改变工作目录到dirname:os.chdir(dirname)
获取当前终端的大小:os.get_terminal_size()
杀死进程:os.kill(3306,mysql)
系统sys
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出程序exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化使用PYTHONPATH
sys.platform 返回操作系统平台
sys.stdout.write('hello:') 标准输出
val = sys.stdin.readline() 标准输入
sys.getrecursionlimit() 获取最大递归层数
sys.setrecursionlimit(2000) 设置最大递归层数
sys.getdefaultencoding() 获取解释器默认编码
sys.getfilesystemencoding 获取内存数据存到文件里的默认编码
时间处理模块time和datetime
时间的显示:
时间的转换:把字符串格式的日期转换成Python的日期类型
时间的运算:计算两个日期间的差值等
time模块
常用时间表示形式
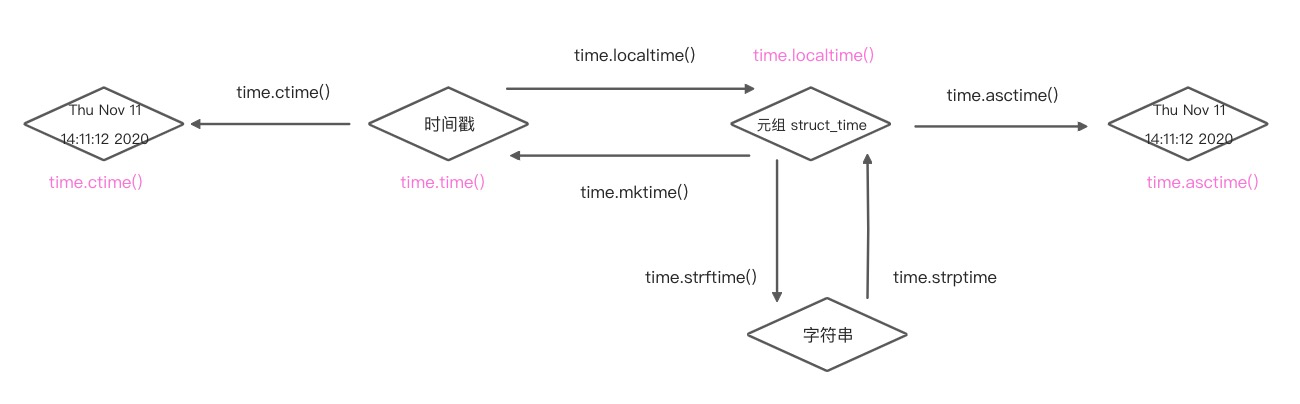
1、时间戳: time.time() 1636606604.630135
2、格式化时间字符串,“2020-02-02 02:20”
3、元组. time.struct_time(tm_year=2020,tm_mon=2,tm_mday=20)
UTC
UTC 格林威治时间,世界标准时间。在中国位UTC+8,又称东8区
time方法
time.localtime([secs]): 将一个时间戳转换为当前时区的struct_time。若secs参数未提供,则以当前时间为准
>>> import time
>>> time.time() # 获取时间戳
1636610457.195623
>>> time.localtime() # 获取struct_time
time.struct_time(tm_year=2021, tm_mon=11, tm_mday=11, tm_hour=14, tm_min=1, tm_sec=24, tm_wday=3, tm_yday=315, tm_isdst=0)
>>> time.localtime(time.time())
time.struct_time(tm_year=2021, tm_mon=11, tm_mday=11, tm_hour=14, tm_min=1, tm_sec=48, tm_wday=3, tm_yday=315, tm_isdst=0)
>>> time.localtime(12345678) # 转换时间戳格式为struct_time格式
time.struct_time(tm_year=1970, tm_mon=5, tm_mday=24, tm_hour=5, tm_min=21, tm_sec=18, tm_wday=6, tm_yday=144, tm_isdst=0)
time.gmtime([secs]): 和localtime()方法类似。gmtime()方法将时间戳转换为UTC时区(0时区)的truct_time.(注:0时区,比北京时间晚8小时)
time.time(): 返回当前时间的时间戳
time.mktime(t): 将一个struct_time转化为时间戳
>>> time.mktime(time.localtime()) 1636610935.0
time.sleep(secs): 线程推迟指定的时间运行,单位 秒
time.asctime([t]): 把一个表示时间的元组或者struct_time表示为这种形式:“Sun Oct 12:04:38 2019”。如果没有参数,将会time.localtime()作为参数传入
>>> time.asctime() 'Thu Nov 11 14:11:12 2020'
>>> time.asctime(time.localtime()) 'Thu Nov 11 14:12:46 2021'
time.ctime([secs]): 把一个时间戳(按秒计算的浮点数)转化为time.asctime()的形式。如果参数未给或者为None的时候,将会默认time.time()为参数。他的作用将相当于time.asctime(time.loacltime(secs)).
>>> time.ctime(time.time()) 'Thu Nov 11 14:13:45 2021' >>> time.ctime() 'Thu Nov 11 14:13:57 2021'
time.strftime(format[,t]): 把一个代表时间的元组或者struct_time(如由time.localtime()和time.gmtime()返回)转化为格式化的时间字符串。如果t未指定,将传入time.localtime()。
>>> time.strftime("%Y-%m-%d %H:%M:%S",time.localtime()) '2021-11-11 14:17:51'
time.strptime(string[,format]): 把一个格式化时间字符串转化为struct_time。实际上它和strftime()是逆操作。
>>> time.strptime("2021/11/11 14:17:51","%Y/%m/%d %H:%M:%S") time.struct_time(tm_year=2021, tm_mon=11, tm_mday=11, tm_hour=14, tm_min=17, tm_sec=51, tm_wday=3, tm_yday=315, tm_isdst=-1)
>>>>> time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time())) '2021-11-11 15:06:26' >>>>> time.strptime('2021-11-11 15:06:26', '%Y-%m-%d %H:%M:%S') time.struct_time(tm_year=2021, tm_mon=11, tm_mday=11, tm_hour=15, tm_min=6, tm_sec=26, tm_wday=3, tm_yday=315, tm_isdst=-1)
datetime模块
datetime模块定义了几个类
datetime.date:表示日期的类,常用的属性有year,month,day
>>> datetime.date.today() datetime.date(2021, 11, 11) >>> datetime.date.fromtimestamp(2222222) datetime.date(1970, 1, 27)
datetime.datetime:表示日期时间 now()
>>> time = datetime.datetime.now()
>>> print(time)
2021-11-12 17:45:08.649797
>>> datetime.datetime.now() datetime.datetime(2021, 11, 11, 15, 31, 34, 772694) >>> datetime.datetime.fromtimestamp(33333333333) datetime.datetime(3026, 4, 17, 19, 15, 33)
datetime.timedelta:表示时间间隔,即两个时间点的长度
>>> t1 = datetime.datetime.now() >>> t1 + datetime.timedelta(days=5,hours=5) datetime.datetime(2021, 11, 16, 20, 40, 47, 981954) >>> datetime.datetime.now() datetime.datetime(2021, 11, 11, 15, 42, 35, 307520)
>>> datetime.datetime.now() datetime.datetime(2021, 11, 11, 15, 42, 35, 307520) >>> t1.replace(year=2020) datetime.datetime(2020, 11, 11, 15, 40, 47, 981954) >>> t1.replace(year=2020,month=12,day=12,minute=12,hour=12) datetime.datetime(2020, 12, 12, 12, 12, 47, 981954)
datetime.tzinfo:与时区有关的信息
>>> import pytz >>> import datetime >>> pytz.timezone("Asia/Shanghai") <DstTzInfo 'Asia/Shanghai' LMT+8:06:00 STD> >>> datetime.datetime.now() datetime.datetime(2021, 11, 11, 15, 59, 41, 719765) >>> datetime.datetime.now(tz=pytz.timezone("Asia/Shanghai")) datetime.datetime(2021, 11, 11, 16, 0, 28, 23973, tzinfo=<DstTzInfo 'Asia/Shanghai' CST+8:00:00 STD>)
随机数random模块
>>> random.randrange(100,999) # 100-999之间随机一个数,不包含999 586 >>> random.randrange(100,999,2) # 100-999之间步长为2的随机一个数 836 >>> random.randint(100,999) # 100-99之间随机一个数,包含999 699 >>> random.random() # 随机一个浮点数 0.7751154738928453 >>> random.choice('a-zA-Z0-9') # 特定字符中的随机一个字符 '-' >>> random.sample('abcABC123',3) # 特定字符中随机3个字符 ['3', 'b', 'C'] # 生产随机字符串 >>> import string # 生产特定的字符串 >>> string. string.Formatter( string.ascii_uppercase string.octdigits string.Template( string.capwords( string.printable string.ascii_letters string.digits string.punctuation string.ascii_lowercase string.hexdigits string.whitespace >>> string.digits # 生成数字 '0123456789' >>> string.ascii_lowercase # 生成小写字母 'abcdefghijklmnopqrstuvwxyz' >>> string.ascii_uppercase # 生成大写字母 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' >>> print(string.digits + string.ascii_lowercase + string.ascii_uppercase) 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ >>> random.sample(string.digits + string.ascii_lowercase + string.ascii_uppercase,3) ['2', 'x', 'f'] >>> random.sample(string.digits + string.ascii_lowercase + string.ascii_uppercase,3) ['r', 'q', 'v'] >>> random.sample(string.digits + string.ascii_lowercase + string.ascii_uppercase,3) ['9', 'o', 'E'] >>> "".join(random.sample(string.digits + string.ascii_lowercase + string.ascii_uppercase,5)) 'gDQBM' # 洗牌 >>> range(100) range(0, 100) >>> list(range(100)) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99] >>> x = list(range(100)) >>> random.shuffle(x) # 洗牌操作,打乱 >>> print(x) [63, 51, 62, 25, 0, 17, 78, 35, 60, 81, 12, 5, 33, 56, 64, 26, 84, 28, 70, 91, 37, 43, 93, 68, 80, 41, 14, 59, 58, 40, 6, 22, 30, 97, 66, 18, 54, 8, 2, 99, 13, 87, 23, 69, 73, 92, 90, 88, 38, 86, 83, 89, 53, 19, 29, 76, 71, 11, 48, 79, 24, 44, 95, 42, 15, 52, 77, 34, 36, 3, 74, 72, 47, 9, 65, 50, 27, 55, 1, 10, 61, 21, 45, 16, 82, 49, 39, 67, 98, 46, 20, 57, 32, 85, 75, 4, 94, 31, 7, 96]
序列化pickle和json模块
pickle模块
json模块
json.dumps(要转为字符串的数据) 转数据为字符串数据
json.dump(字符串数据,文件对象) 将数据写入文件
json.load(文件对象) 读出文件
json.loads 把序列化的字符串反向解析
pickle VS json
pickle
只支持python 支持py里的所有数据类型 class -> object function datetime
json
所有语言都支持 只支持常规数据类型,str,int,dict,set,list,tuple
>>> import json >>> info = {"name":"zhangsan","age":10,"sex":"M"} >>> f = open("info.json", "w") >>> f = open("info.json", "w") >>> json.dump(info,f) >>> f2 = open("info.json", "r") >>> print(json.load(f2))
正则表达式re模块
re的匹配语法
re.match 从头开始匹配(匹配内容的首位) re.search 匹配包含 (只匹配一个) re.findall 把所有匹配到的字符放到以列表中的元素返回 re.split 一匹配到的字符当作列表分隔符 re.sub 匹配字符并替换 re.fullmatch 全部匹配
group():匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。
groups():返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
re.compile 函数
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
语法格式为:
re.compile(pattern[, flags])
参数:
pattern : 一个字符串形式的正则表达式 flags : 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为: re.I 忽略大小写 re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境 re.M 多行模式 re.S 即为 . 并且包括换行符在内的任意字符(. 不包括换行符) re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库 re.X 为了增加可读性,忽略空格和 # 后面的注释
re.match 从头开始匹配(匹配内容的首位)
>>> import re >>> re.match('www','www.baidu.com').span() (0, 3) >>> re_m = re.match('www','www.baidu.com') >>> matchObj = re.match( r'(.*) are (.*?) .*', line) >>> matchObj.group(0) 'Cats are smarter than dogs' >>> matchObj.group(1) 'Cats'
re.search 匹配包含 (匹配到第一个停止)
>>> print(re.search('www','www.baidu.com').span()) (0, 3) >>> print(re.search('com','www.baidu.com').span()) (10, 13) >>> print(re.search('com','www.baidu.com,www.taobao.com').span()) (10, 13) >>> line = "Cats are smarter than dogs" >>> searchObj = re.search( r'(.*) are (.*?) .*', line, re.M|re.I) >>> searchObj.group() 'Cats are smarter than dogs' >>> searchObj.group(1) 'Cats' >>> searchObj.group(2) 'smarter' >>> searchObj.groups() ('Cats', 'smarter')
re.findall 把所有匹配到的字符放到以列表中的元素返回
>>> import re >>> print(re.findall('com','www.baidu.com,www.taobao.com')) ['com', 'com'] >>> pattern = re.compile('www') >>> result = pattern.findall('www.baidu.com,www.taobao.com') >>> print(result) ['www', 'www'] >>> print(result.group(1)) Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'list' object has no attribute 'group' >>> print(result[0]) www
re.sub 匹配字符并替换
>>> phone = "2004-959-559 # phone" # 删除# 注释(匹配# 后内容,替换成空“”) >>> num = re.sub(r'#.*$', "", phone) >>> print ("电话号码是: ", num) 电话号码是: 2004-959-559 # 删除非数字内容(匹配非数字内容,替换成空“”) >>> num = re.sub(r'\D', "", phone) >>> print ("电话号码是 : ", num) 电话号码是 : 2004959559
re.split 字符串分割
split 方法按照能够匹配的子串将字符串分割后返回列表
re.split(正则,原数据,start_,end_)
>>> re.split('\W+', 'Hello,word!!') ['Hello', 'word', ''] >>> re.split('(\W+)', 'Hello,word!!') ['Hello', ',', 'word', '!!', '']
paramiko 登录远程服务器SSH
struct_time

