unittest框架数据驱动
一、目录
数据驱动概述
环境准备
使用unittest和ddt驱动
使用数据文件驱动
使用Excel驱动
使用XML驱动
使用MySQL驱动
二、数据驱动概述
数据驱动的定义:
- 相同的测试脚本使用不同的测试数据来执行
- 测试数据和测试行为完全分离
- 是一种测试脚本设计模式
实施数据驱动测试步骤:
- 编写测试脚本,脚本需要支持从程序对象、文件或数据库读入测试数据。
- 将测试脚本使用测试数据存入程序对象、文件或数据库等外部介质中。
- 运行脚本过程中,循环调用存储在外部介质中的测试数据。
- 验证所有的测试结果是否符合预期结果。
安装:
在线安装
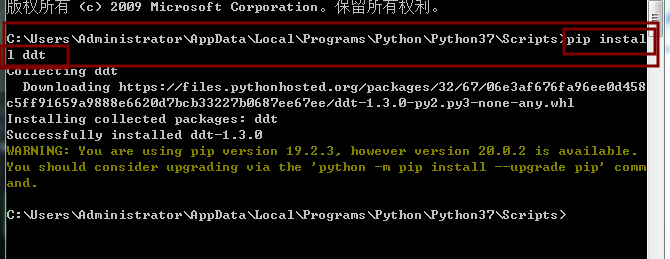
离线安装
下载安装包:https://pypi.python.org/pypi/ddt
在CMD中切换至解压后目录,执行python setup.py install
数据驱动使用说明:
- 头部导入ddt模块(import ddt)
- 在测试类前声明使用ddt(@ddt.ddt)
- 在测试方法前使用@ddt.data()添加测试数据
- 多组测试数据以逗号隔开如@ddt.data(1,2,3)
- 每组数据中的数据与测试方法中定义的形参个数及顺序一一对应
- 使用@ddt.unpack进行修饰
- 测试过程中将测试数据传给测试方法中的形参。
实例:
import ddt import unittest @ddt.ddt class DoubanTest(unittest.TestCase): def setUp(self): pass def tearDown(self): pass @ddt.data([1,2,3,6],[2,3,4,9],[3,4,5,12]) # @ddt.data([1,2,3,6]) @ddt.unpack def test_add(self,testdata1,testdata2,testdate3,exceptdata): sum=0 sum=testdata1+testdata2+testdate3 self.assertEqual(sum,exceptdata) if __name__ =='__main__': unittest.main()
二、数据文件驱动
语法:@ddt.file_data('data.json') 走data.json文件中获取数据
实例:
data.json
‘“data.json”’ [ "QQ||QQ_百度搜索", "微信||微信_百度搜索", "钉钉||钉钉_百度搜索" ]
run_test.py
import ddt,time import unittest from selenium import webdriver @ddt.ddt class Douban(unittest.TestCase): @classmethod def setUpClass(self): self.driver = webdriver.Chrome() @classmethod def tearDownClass(self): self.driver.quit() def setUp(self): self.driver.get('http://www.baidu.com') def tearDown(self): pass @ddt.file_data('data.json') @ddt.unpack def test_baidu(self,value): can,yu = value.split('||') print(can,yu) time.sleep(2) self.driver.find_element_by_id('kw').send_keys(can) time.sleep(2) self.driver.find_element_by_id('su').click() time.sleep(2) self.assertEqual(self.driver.title,yu) if __name__ == '__main__': unittest.main()
三、Excel驱动
安装:pip install openpyxl
思路:
- 先获取excle文件的路径和文件名
- 获取表名
- 根据表的列和行读取数据
测试Excel文件

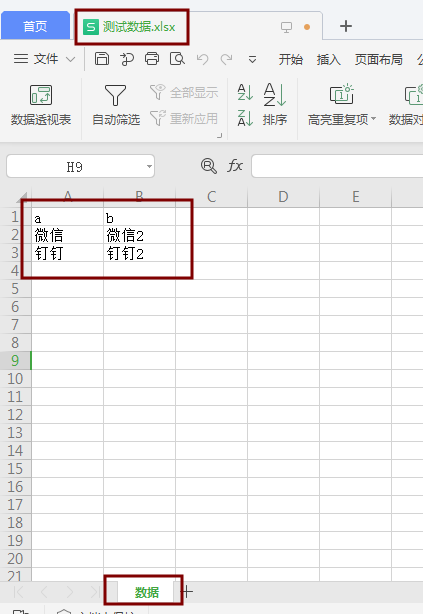
Excel_test.py
from openpyxl import load_workbook class ParseExcel(): def __init__(self, excelPath, sheetName): self.wb = load_workbook(excelPath) self.sheet = self.wb.get_sheet_by_name(sheetName) self.maxRowNum = self.sheet.max_row def getDatasFromSheet(self): dataList = [] for line in self.sheet.rows[1:]: tmpList=[] tmpList.append(line[0].value) tmpList.append(line[1].value) dataList.append(tmpList) # print(line) return dataList if __name__ == '__main__': excelPath='E:/data/测试数据.xlsx' sheetName = '数据' pe = ParseExcel(excelPath,sheetName) for i in pe.getDatasFromSheet(): print(i[0]) print(i[1])
DataDiver.py
from selenium import webdriver from Excal_data.Excal_text import ParseExcel import unittest,time,logging,traceback,ddt #初始化日志对象 logging.basicConfig( #此处省略 ) excelPath = 'E:/data/测试数据.xlsx' sheetName = '数据' excel = ParseExcel(excelPath,sheetName) @ddt.ddt class TestDemo(unittest.TestCase): # def setUp(self): # self.driver = webdriver.Firefox() # # def tearDown(self): # self.driver.quit() @ddt.data( * excel.getDatasFromSheet()) def test_dataDrivenByFile(self,data): testData,expectData = tuple(data) print(testData,expectData) # 打印获取的两个数据 # 根据上面的获得数据建立下面逻辑
四、XML驱动
安装:Python自带不用安装
TestData.XML
<?xml version='1.0' encoding='utf-8'?> <bookList type='technology'> <book> <name>钉钉</name> <author>阿里</author> </book> <book> <name>微信</name> <author>腾讯</author> </book> </bookList>
XmlUtil.py
from xml.etree import ElementTree class ParseXML(): def __init__(self, xmlPath): self.xmlPath = xmlPath def getRoot(self): tree = ElementTree.parse(self.xmlPath) return tree.getroot() def findNodeByName(self, parentNode, nodeName): nodes = parentNode.findall(nodeName) return nodes def getNodeOfChildText(self, node): childrenTextDict = {i.tag: i.text for i in list(node.iter())[1:]} # childrenTextDict={} # for i in list(node.iter())[1:]: # childrenTextDict[i.tag] = i.text return childrenTextDict def getDataFromXml(self): root = self.getRoot() books = self.findNodeByName(root, "book") dataList = [] for book in books: childrenText = self.getNodeOfChildText(book) dataList.append(childrenText) return dataList if __name__ == '__main__': xml = ParseXML("./TestData.xml") datas = xml.getDataFromXml() for i in datas: print(i["name"])
XmlDriver.py
from selenium import webdriver from XML_data.XmlUtil import ParseXML from selenium.common.exceptions import NoSuchElementException import unittest,time,os,logging,traceback,ddt #初始化日志对象 logging.basicConfig( #此处省略 ) currentPath = os.path.dirname(os.path.abspath(__file__)) dataFilePath = os.path.join(currentPath,"TestData.xml") xml = ParseXML(dataFilePath) @ddt.ddt class TestDemo(unittest.TestCase): # def setUp(self): # self.driver = webdriver.Firefox() # # def tearDown(self): # self.driver.quit() @ddt.data( * xml.getDataFromXml()) def test_dataDrivenByXML(self,data): testData,expectData = data["name"],data["author"] print(testData,expectData) # self.driver.get("http://www.baidu.com/") # time.sleep(3) # # 根据上面的获得数据建立下面逻辑
五、MySQL驱动
思路:连接数据库 - 根据数据库的表获取数据 - unittest框架ddt获取数据 - 处理数据格式
准备:数据库相关准备和操作
环境准备
- 下载mysql安装包
- 设置用户名密码(user:root passwd:1234)
- 安装mysql for python插件
-
- 将下载好文件放在pip下
- 在cmd下切换至pip所在目录下
- 执行pip install mysql***.whl
- 安装完成后进入python,输入import MySQLdb
- 不报错即为安装成功
数据库操作
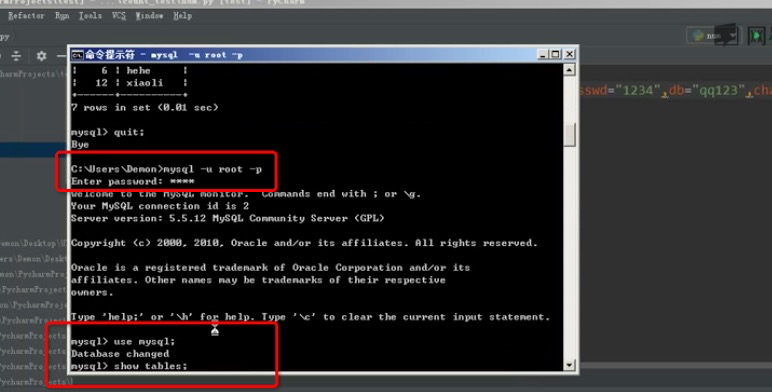
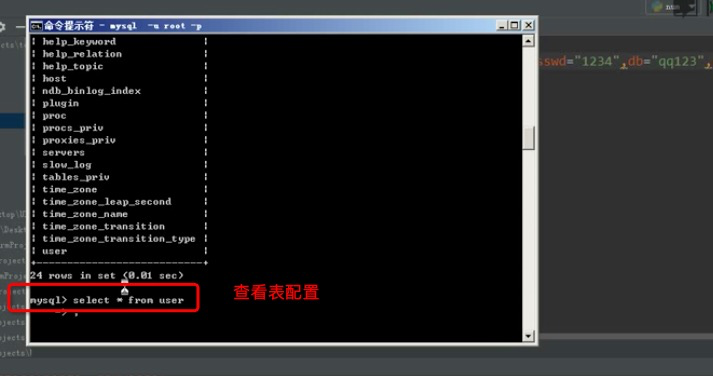
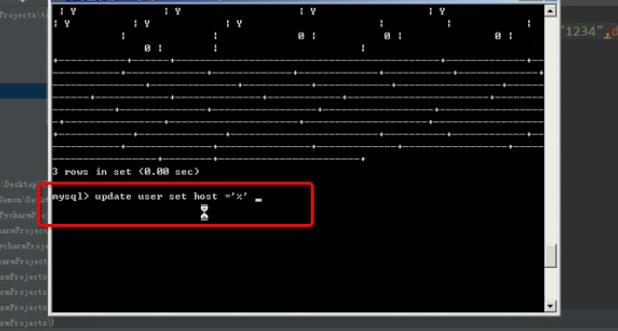
更改数据库host
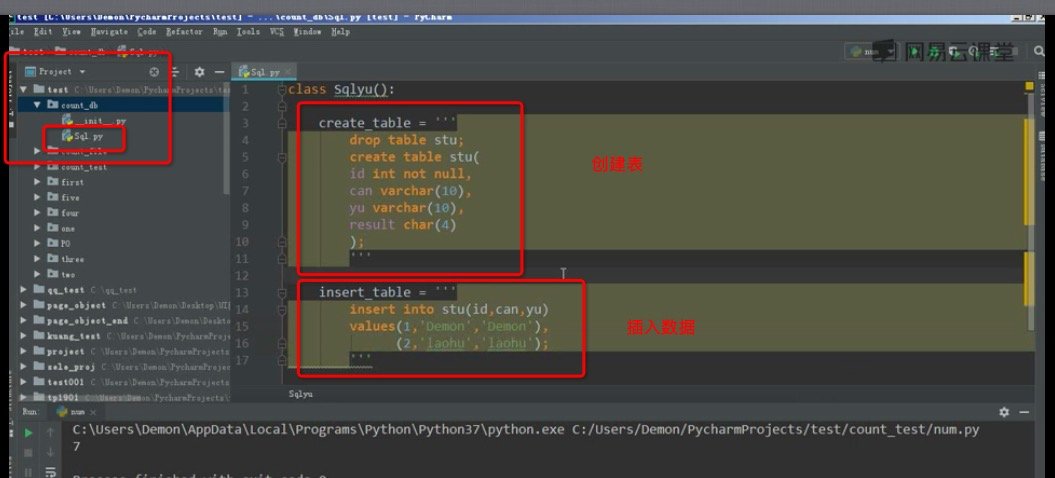
数据库创建和表数据插入
操作数据库
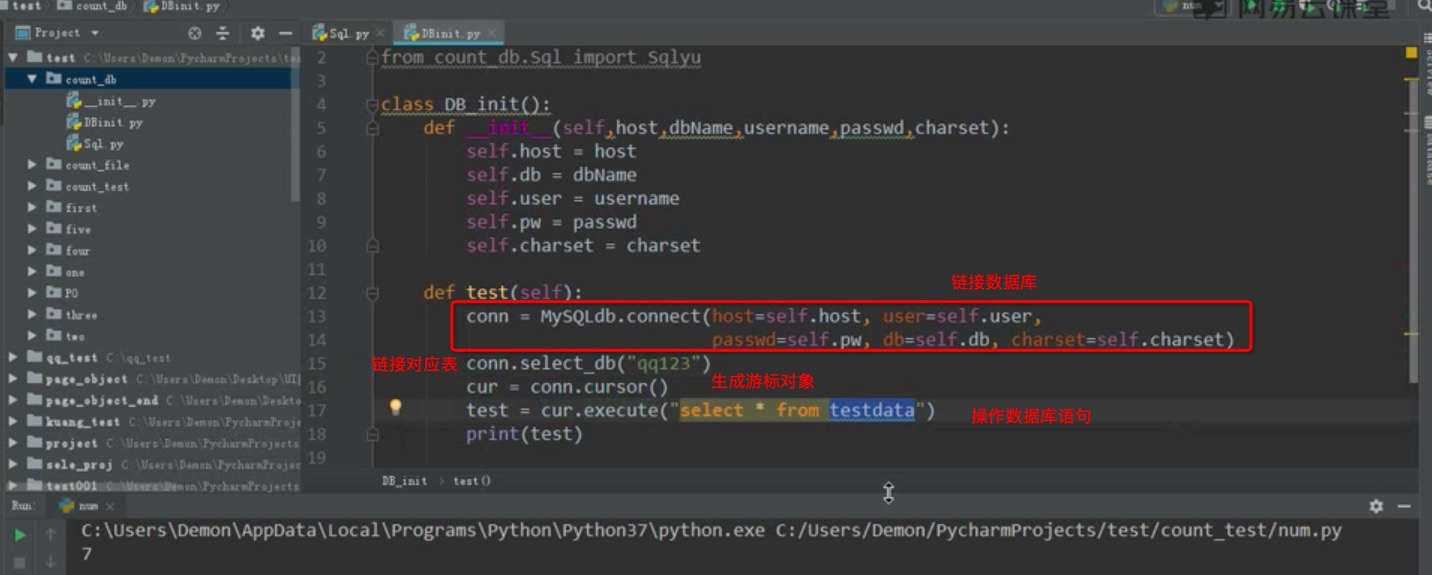
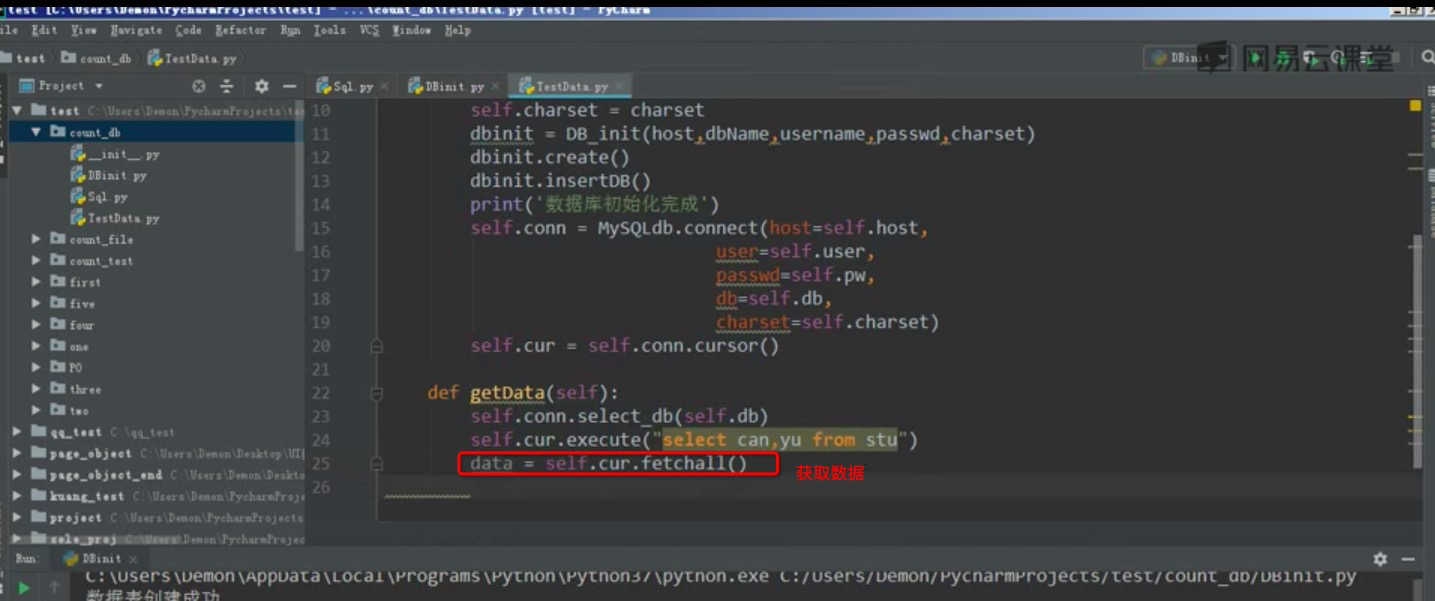
初始数据库变量,并启动对应方法

关联对应数据表
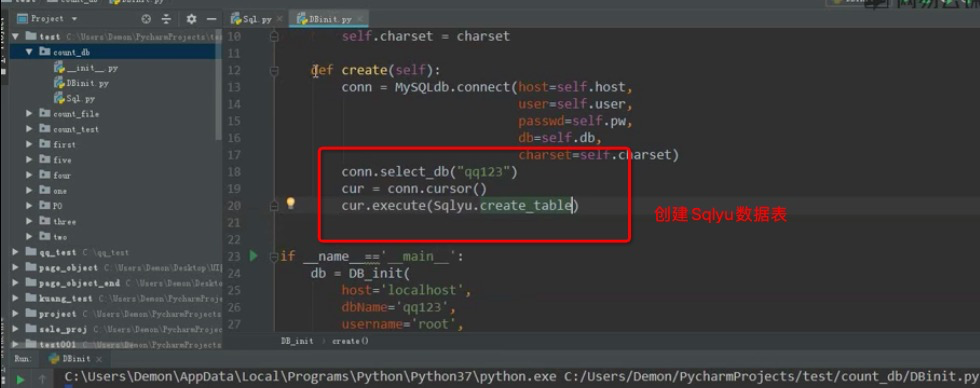
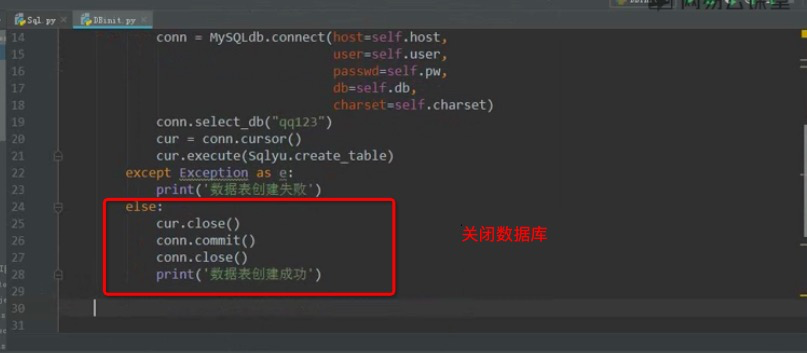

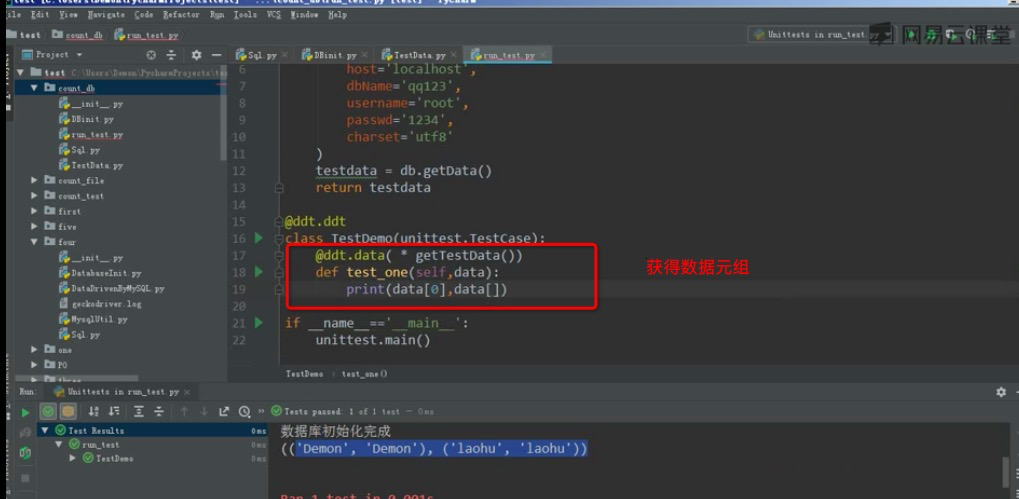
建立unittest框架驱动数据并处理
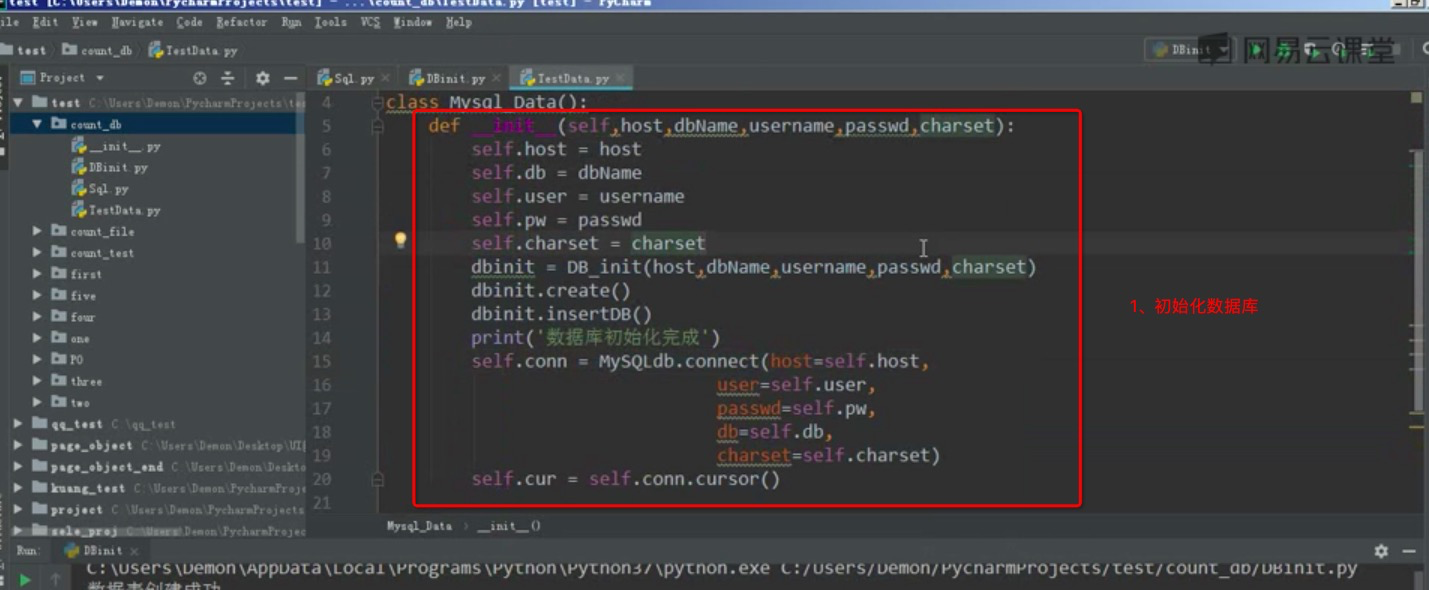
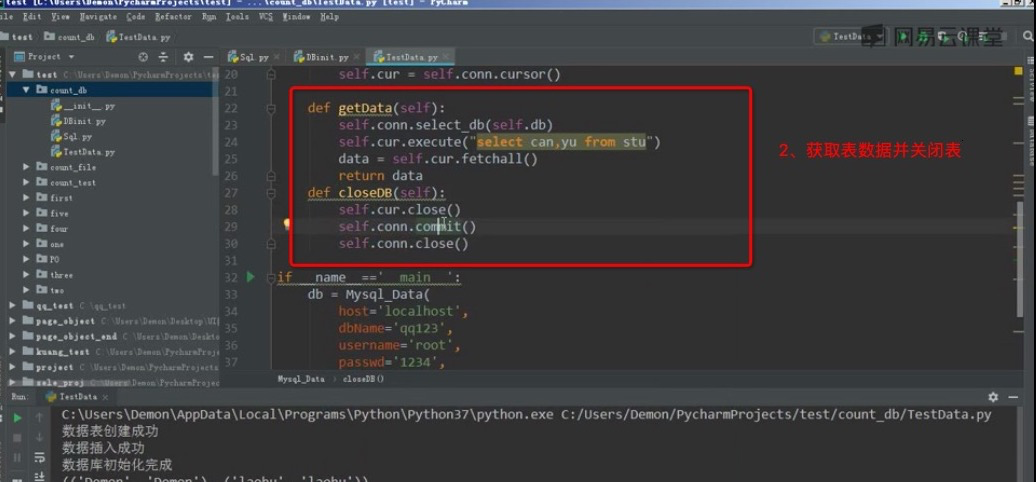
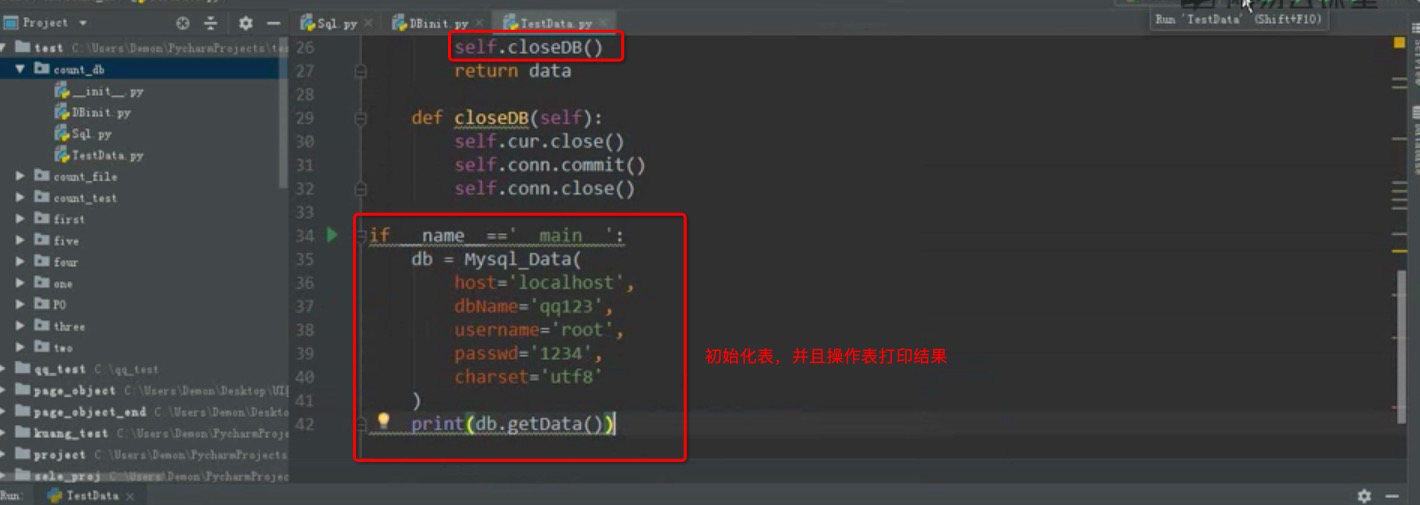

获取数据处理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号