
大数据应用期末总评Hadoop综合大作业
作业要求来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339
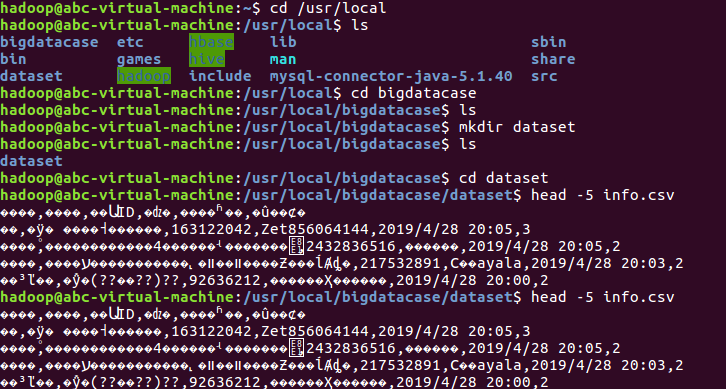
1.将爬虫大作业产生的csv文件上传到HDFS
此次作业选取的是爬虫《反贪风暴》短评数据生成的info.csv文件;爬取的数据总数为16141条。
cm.csv文件数据如下图所示:

将info.csv文件上存到HDFS
2.对CSV文件进行预处理生成无标题文本文件
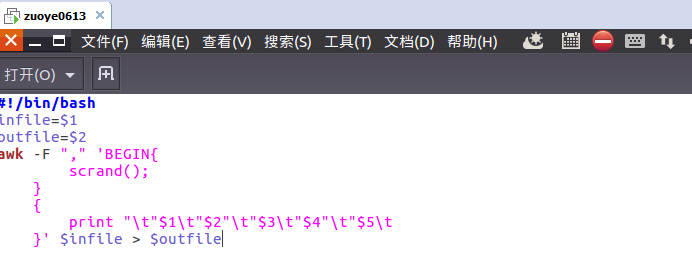
csv文件数据预处理,删除第一行字段名称

编辑pre_deal.sh文件进行数据的取舍处理
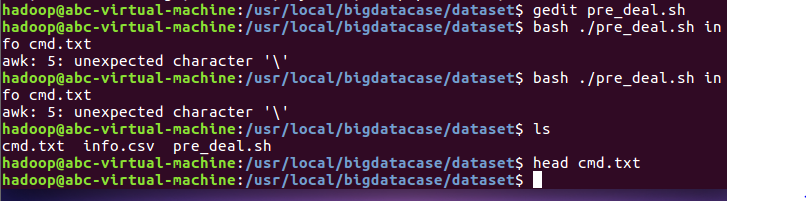
让pre_deal.sh文件生效,并显示前面几条数据


3.把hdfs中的文本文件最终导入到数据仓库Hive中
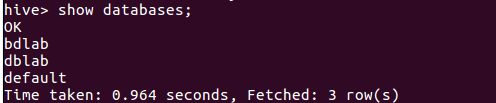
在hive中创建bdlab数据库,显示如下:

因为此次使用的是bdlab的数据库,所以在bdlab中创建相应的表为bigdata_cmd
3.把hdfs中的文本文件最终导入到数据仓库Hive中
在hive中创建bdlab数据库,显示如下:
4.在Hive中查看并分析数据
5.用Hive对爬虫大作业产生的进行数据分析
由于前期数据处理导致数据受损,最终完成不了期末Hadoop大作业,因此只能按PPT的步骤进行一次练习。没能够得出有效的数据。前面期中的时候已经爬取数据16141条,如果不是文件受损,导致无法进行此次·作业,此次作业将会很好的完成。望老师理解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号