安装关系型数据库MySQL和大数据处理框架Hadoop
 作业要求来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161
作业要求来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161
1.简述Hadoop平台的起源、发展历史与应用现状。
Hadoop系统最初的源头来自于Apache Lucene项目下的搜索引擎子项目Nutch,该项目的负责人是Doug Cutting。2003年,Google公司为了解决其搜索引擎中大规模Web网页数据的处理,研究发明了一套称为MapReduce的大规模数据并行处理技术,并于2004年在著名的OSDI国际会议上发表了一篇题为“MapReduce:Simplified Data Processing on Large Clusters”的论文,简要介绍MapReduce的基本设计思想。论文发表后,Doug Cutting受到了很大启发,他发现Google MapReduce所解决的大规模搜索引擎数据处理问题,正是他同样面临并急需解决的问题。因而,他尝试依据Google MapReduce的设计思想,模仿Google MapReduce框架的设计思路,用Java设计实现出了一套新的MapReduce并行处理软件系统,并将其与Nutch分布式文件系统NDFS结合,用以支持Nutch搜索引擎的数据处理。2006年,他们把NDFS和MapReduce从Nutch项目中分离出来,成为一套独立的大规模数据处理软件系统,并使用Doug Cutting小儿子当时呀呀学语称呼自己的玩具小象的名字“Hadoop”命名了这个系统。2008年他们把Hadoop贡献出来,成为Apache最大的一个开源项目,并逐步发展成熟,成为一个包含了HDFS、MapReduce、HBase、Hive、Zookeeper等一系列相关子项目的大数据处理平台和生态系统。
Hadoop开源项目自最初推出后,经历了数十个版本的演进。它从最初于2007年推出的Hadoop-0.14.X测试版,一直发展到2011年5月推出了经过4500台服务器产品级测试的最早的稳定版0.20.203.X。到2011年12月,Hadoop又在0.20.205版基础上发布了Hadoop1.0.0,该版本到2012年3月发展为Hadoop1.0.1稳定版。1.0版继续发展,到2013年8月发展为Hadoop1.2.1稳定版。
与此同时,由于Hadoop1.X以前版本在MapReduce基本构架的设计上存在作业主控节点(JobTracker)单点瓶颈、作业执行延迟过长、编程框架不灵活等较多的缺陷和不足,2011年10月,Hadoop推出了基于新一代构架的Hadoop0.23.0测试版,该版本系列最终演化为Hadoop2.0版本,即新一代的Hadoop系统YARN。2013年10月YARN已经发展出Hadoop2.2.0稳定版。
由于Hadoop优势突出,基于Hadoop的应用已经遍地开花,尤其是在互联网领域。TANJURD报告显示:Yahoo! 通过集群运行Hadoop,以支持广告系统和Web搜索的研究;Facebook借助集群运行Hadoop,以支持其数据分析和机器学习百度则使用Hadoop进行搜索日志的分析和网页数据的挖掘工作;淘宝的Hadoop系统用于存储并处理电子商务交易的相关数据;中国移动研究院基于Hadoop的“大云”(BigCloud)系统用于对数据进行分析和并对外提供服务。
2008年2月,Hadoop较大贡献者的Yahoo!构建了当时规模较大的Hadoop应用,它们在2000个节点上面执行了超过1万个Hadoop虚拟机器来处理超过5PB的网页内容,分析大约1兆个网络连接之间的网页索引资料。这些网页索引资料压缩后超过300TB。Yahoo!正是基于这些为用户提供了高质量的搜索服务。
Hadoop目前已经取得了非常突出的成绩。随着互联网的发展,新的业务模式还将不断涌现,Hadoop的应用也会从互联网领域向电信、电子商务、银行、生物制药等领域拓展。相信在未来,Hadoop将会在更多的领域中扮演幕后英雄,为我们提供更加快捷优质的服务。
2.安装MySql与安装Hadoop
安装vim

静态节点的设置

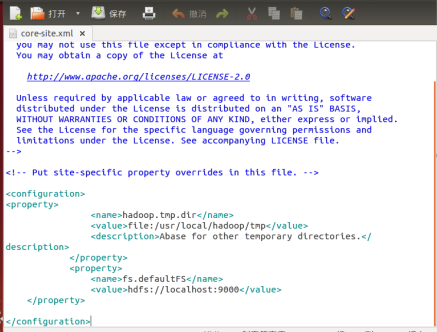
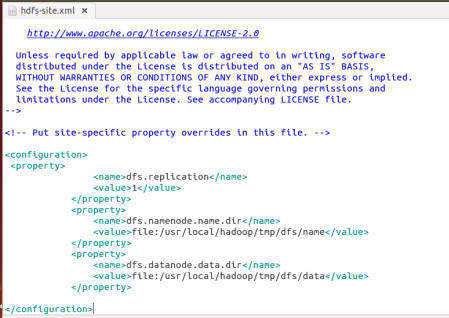
修改core-site.xml和hdfs-site.xml的configuration:
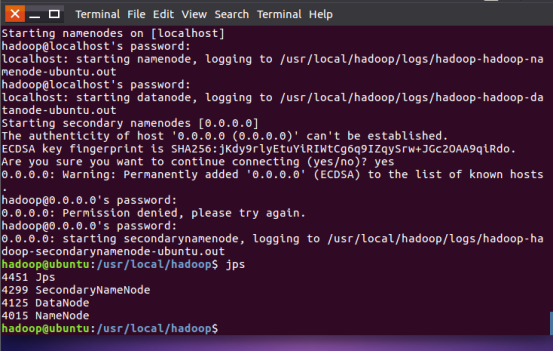
查看守护进程是否开启成功: