MySQL学习之explain
from之后的查询得到的表叫做衍生表,是临时表数据,生成临时表之后的数据是无法使用索引的,如果数据量大查询效率就会比较低,这就是查询要尽量少使用子查询这些临时表。
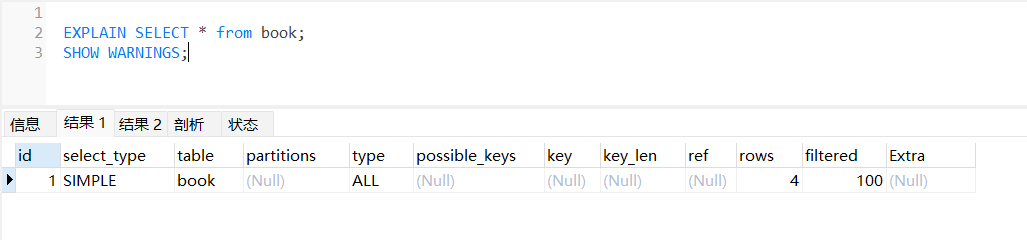

explain详解
id:
表示查询序号,也可以表示优先级;当值都不一样的时候,值越大表示优先级越高,越先执行;当值都一样的时候,按照从上到下的顺序去执行。
select_type:
表示查询的类型,是简单类型还是复杂类型。
- simple:简单查询。查询不包含子查询和union。
- primary:复杂查询中最外层的 select。
- subquery:包含在 select 中的子查询(不在 from 子句中)。
- derived:包含在 from 子句中的子查询。MySQL会将结果存放在一个临时表中,也称为派生表(derived的英文含义)。
table:
表示查询的表名,有些真实表有表名,临时表也会起一个表名,复杂查询可能没有表名。表示本行访问的表。当 from 子句中有子查询时,table列是 <derivenN> 格式,表示当前查询依赖 id=N 的查询,于是先执行 id=N 的查询。当有 union 时,UNION RESULT 的 table 列的值为<union1,2>,1和2表示参与 union 的 select 行id。
partitions:
表示分区信息,很少使用到。
type:
索引使用类型,很重要。表示查找范围。最常使用的是有system,const,eq_ref,ref,range,index,ALL。这些查询效率从左到右依次降低。一般来说我们要将查询优化到range级别,最好是到ref级别。
- null表示查询优化阶段就可以确认要查询的数据,不用再去查表了。类似扫描个别索引就能获取到值。
- system,是查询结果有且仅有一条数据,是const的特例。const是使用主键索引,或者唯一索引,查询结果最多只有一条数据,扫描次数很少,效率高。
- eq_ref,是equals,也就是说如果有连表查询,被连的表的查询条件是主键或者唯一键,能确认被连表只能查询一条数据。简单查询不会出现这样的结果。
- ref,表示没有使用唯一索引,或者使用了唯一索引的部分,查询到的数据不是唯一的,可能多个也可能一个。
- range,明确的是范围查询,常在int,between和and,>,<,>=等,是使用到了索引的查询,查询范围数据,数据量较多。
- index,表示扫描索引就能获取到全部数据,一般是查询二级索引,并且要查询的列都在二级索引上,可以避免回表操作。
- all,表示全表扫描,不会再使用索引了,效率最低。
注意:查询语句优先查询二级索引,因为二级索引更小,存储的数据量更多,如果不满足,才会去主键索引上去查询。
possible_keys:
表示可能会用到的索引值,可能有多个,也可能为空。
key:
表示真正使用到的索引,该值有可能没有在possible_keys中显式,也可能在其中显式;总的来说两个没有必然联系,这个是要看MySQL的查询优化器的优化。
注意:这里的key是针对的where后的查询条件,不包括group by和order by之类的分组排序等,这个要明确。
key_len:
表示使用到的索引的长度值。通过这个值可以算出具体使用了索引中的哪些列。
key_len计算规则如下:
ref:
这一列显示了在key列记录的索引中,表查找值所用到的列或常量,常见的有:const(常量),字段名(例:film.id)
rows:
表示本次查询预估的条目数,越少越好。但是这个值并不准确。
filtered 列:
Extra列:
索引最佳优化实践

 浙公网安备 33010602011771号
浙公网安备 33010602011771号