re模块
1.re模块
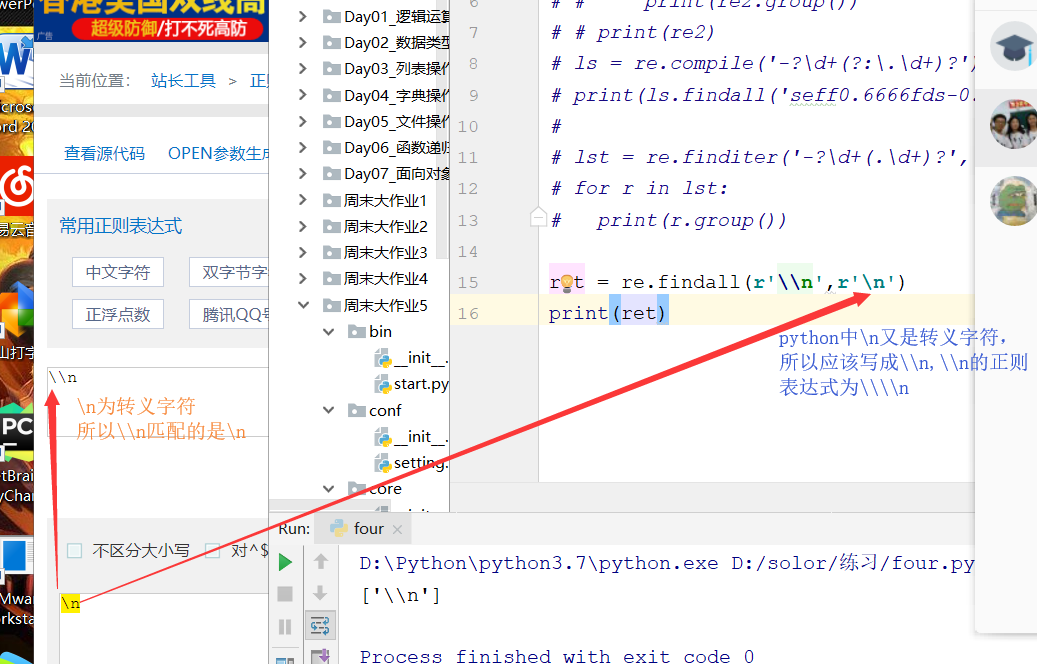
a:当正则进入程序中,会引发转义字符的问题
转义字符:程序中的反斜杠有特殊意义,\相当于转义,所以\\相当于翻转义;
b:关于中括号的[]一般量词进去都会现原形,[(),+,*,?,/,$,.]这些都会以本身意义表示;
而还有一个[-]如果不放在开头,就表示什么到什么,放在开头就是普通的减;
c:如果在一串字符串前加上r,表示强制转义,所有转义字符失效; 例:r'\n\t\d' 输出:\n\t\d
但转义字符r只在文本输入的输入的时候有用,不能对变量进行转义;
2.re模块的应用
1).findall:
a:参数:findall(pattern(正则表达式),string,flags=0)
b:返回值类型:list,而且是迭代输出,
c:返回值内容:匹配到的所有项,匹配不到,返回空列表;
2).search:
a:参数:search(pattern(正则表达式),string,flags=0)
b:返回值类型:正则匹配的对象;如果没找到,则返回None
c:返回值内容:内存地址,只匹配第一个符合规则的对象;
3).match:
a:参数:search(pattern(正则表达式),string,flags=0)
b:返回值类型:正则匹配的对象;如果没找到,则返回None
c:返回值内容:内存地址,只匹配开头是否符合规则,跟search一样,只是在search的正则表达式前加了^;
d:如果想要输出数值,需要group方法,
4)sub:
a:参数:sub(pattern, repl(要替换的值), string, count=0(替换次数), flags=0)
#几个有趣的事情 # \d? 的情况替换: ret = re.sub('\d?','M','56f',3) print(ret) #输出结果: MMfM ?代表0个或一个,所以它会一个一个找, 如果找不到,把原字符拿下来,但也算0次所以再加一个M # \d+的情况替换: ret = re.sub('\d+','M','56f',3) print(ret) #输出结果: Mf +代表一个或多个,根据贪婪法则,所以会将一组数字作为整体替换 # \d*的情况替换 ret = re.sub('\d*','M','56f') print(ret) #输出结果: MfM *代表0个或多个,即可以把56作为一组替换,又能不匹配值0个做添加M
#上面这三种情况如果执行subn()得到的次数依次是 (MMfM,3)(Mf,1)(MfM,2)
5)split
a:参数:split(pattern, string, maxsplit=0, flags=0)
b:关于split切割后的重复元素问题:
sst = 'ff66ff44ff88ff77ff11ff00' ret = re.split('\d+',sst) ret = [i for i in ret if i != ""] print(ret) #输出结果: ['ff', 'ff', 'ff', 'ff', 'ff', 'ff'] 这里如果用remove的话,只能删除一个; 所以用列表推导式比较好;
6)compile
a:参数:compile(pattern,flags=0)
b;作用节省时间;(只有在多次使用相同的一个正则表达式时节省时间,一次不节省)
7)finditer
a:finditer(pattern,flags=0)
b:相当于一个迭代器,惰性机制,节省内存;
c:配合group使用:
sst = 'ff66__+dd4+33' ret = re.finditer('\d',sst) for i in ret: print(i.group()) #输出结果: 6 6 4 3 3
这里相当于:假如一下给我50个人排座位,我排的就很慢,但是你50个人现在一个地方存着,我叫你了,你进来一个,我一个一个处理座位问题就从空间的角度上提高了效率;
3.正则的分组优先
1).re模块中加括号的有一个分组优先的坑,会优先显示括号里的匹配规则;
ret = re.findall('\d+(\.\d+)?','**2**2.**2.33**') print(ret) #输出结果: ['', '', '.33'] 会只保留符合分组的匹配规则; 2虽然符合规则,但是不被显示,所以为""
2)如果你想要让括号外的匹配上,在括号里加一个(?:)这种情况只在findall和split中有;
#所以你用split的时候,如果你想要保留你切去的数据,就把正则表达式括起来;
3)分组遇上search:
如果search有分组的话,通过group(n)就能拿到group中匹配的内容;
