
HDFS分布式文件系统(大数据)
- 本章首先介绍了基本的文件系统组成,并以Linux为例阐述了文件系统的相关概念。
- 其次对HDFS的概念及应用场景进行了介绍,分析了HDFS的基本架构原理、数据流及关键特性。
- 最后介绍了为HDFS集群的高可用提供分布式协调服务的ZooKeeper组件,并介绍了其关键特性及在其他组件中的应用场景。
文件系统概述
- 文件系统是一种存储和组织计算机数据的方法,它使得对数据的访问和查找变得容易。
- 文件系统是对计算机资源的一种抽象,它使用文件和树形目录的抽象逻辑来替代硬盘等物理设备的数据块概念。
- 文件系统并不依赖于本地数据存储设备。
文件系统概述
- 文件名
文件名是用来唯─标识和定位文件存储位置的名称。
- 目录
文件系统一般都有目录(也称为文件夹),目录允许用户将文件分割成单独的集合,其内部可以保存文件,也可以包含一些其他的目录。
- 元数据
元数据是保存文件属性的数据,即描述数据的数据。
- 权限控制
一套针对不同的用户或者用户组的管理访问权限的方法。
HDFS架构
特点
存储和处理数据较大
支持流式数据访问口
支持多硬件平台
数据一致性高
有效预防硬件异常
支持移动计算
局限性
不适合低延迟的数据访问
无法高效地存储大量小文件
不支持多用户写入和任意修改文件
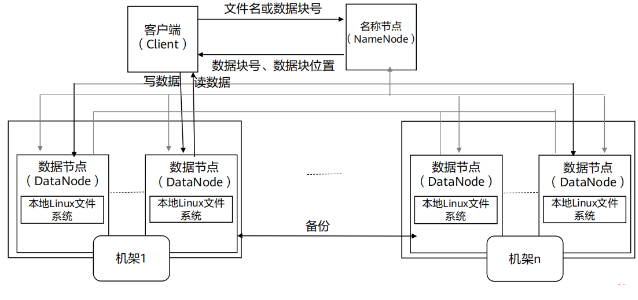
HDFS体系结构(1)
HDFS的存储策略是把大数据文件分块并存储在不同的计算机节点(Node )中,通过NameNode管理文件分块存储信息(即文件的元信息)。
HDFS体系结构(2)
- HDFS采用了典型的主从( Master/Slave )架构,一个HDFS集群通常包含一个NameNode和若干个DataNode。一个文件被分成了一个或者多个数据块,并存储在一组DataNode上,DataNode可分布在不同的机架上。
- NameNode执行文件系统的全名空间打开或关闭、重命名文件或目录等操作,同时负责管理数据块到具体DataNode的映射。
- 在NameNode的统一调度下,DataNode负责处理文件系统客户端的读/写请求,完成数据块的创建、删除和复制。
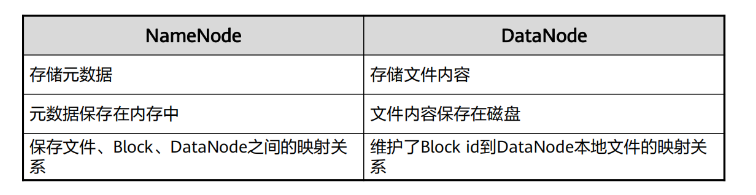
NameNode和DataNode
- DataNode是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端( Client)或者是NameNode的调度来进行数据的存储和检索,并且向NameNode定期发送自己所存储的块的列表。
- 每个DataNode中的数据会被保存在各自节点的本地Linux文件系统中。
数据块
- 数据块(Block)是磁盘进行数据读写操作的最小单元。文件以块的形式存储在磁盘中,文件系统每次都能操作磁盘数据块大小整数倍的数据。
- HDFS默认一个块128 MB,一个文件被分成多个块,以块作为存储单位。
- 块的大小远远大于普通文件系统,可以最小化寻址开销。
- 使用抽象的数据块具有以下优势:
- 通过集群扩展能力可以存储大于网络中任意一个磁盘容量的任意大小的文件;
- 使用抽象块而非整个文件作为存储单元,可简化存储子系统,固定的块大小可方便元数据和文件数据块内容的分开存储;
- 便于数据备份和数据容错,提高系统可用性。
安全模式
安全模式是HDFS所处的一种特殊状态,在这种状态下,未见系统只接收读数据请求,而不接收删除、修改等变更请求。
文件安全性
- 为了保证文件的安全性,HDFS提供备份NameNode元数据和增加SecondaryNameNode两种基本方案。
- 备份NameNode上持久化存储的元数据,然后同步的将其转存到其他文件系统中。一种通常的实现方式是将NameNode中的元数据转存到远程的网络文件系统中。
- 在系统中同步运行一个SecondaryNameNode,作为二级NameNode去周期性的合并编辑日志中的命名空间镜像。
文件权限
- HDFS的文件权限模型基本上和POXSIX模型的文件和目录实现权限模型相同。每个文件和目录都与一个所有者和一个组相关联。该文件或目录对作为所有者的用户、作为该组成员的其他用户以及所有其他用户具有单独的权限。
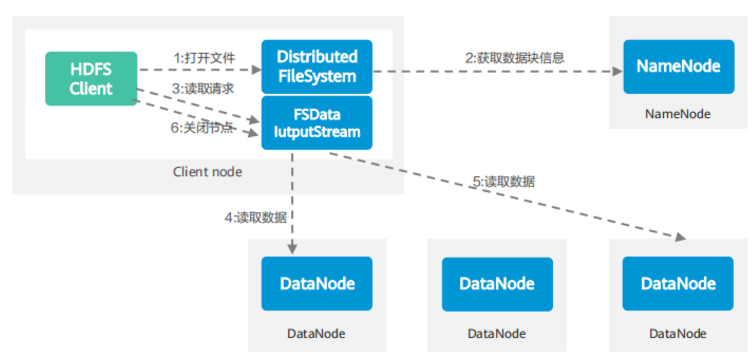
HDFS中的数据写入流程

HDFS中的数据读取流程
HDFS关键特性
- HDFS高可用性
- HDFS元数据持久化
- HDFS联邦
- HDFS试图文件系统
- HDFS机架感知策略
- HDFS集中式缓存管理
- 配置HDFS数据存储策略
- HDFS同分布
HDFS高可用性
- 在这个架构中,HDFS的可靠性主要体现在使用zookeeper来实现主/备NameNode。
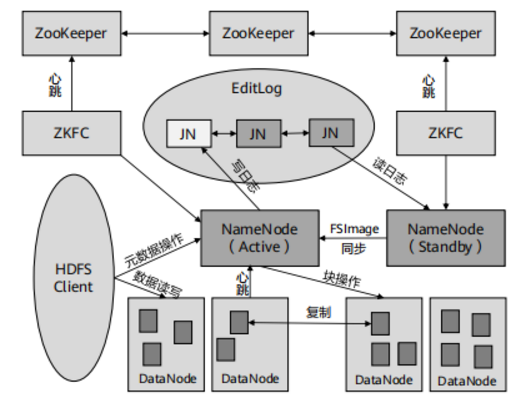
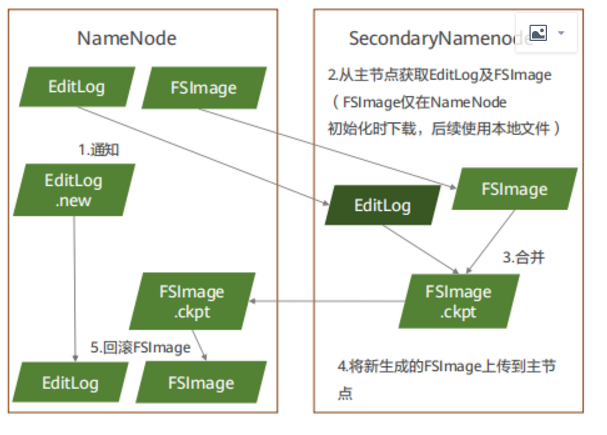
HDFS元数据持久化
- HDFS元数据(描述文件)持久化由FSImage和Editlog两个文件组成,随者HDFS运行进行持续更新。
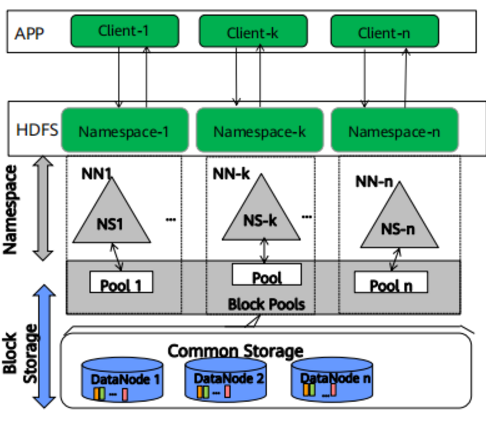
HDFS联邦
- 在HDFS联邦中,有多个联合却相互独立的NameNode,这使得HDFS的命名空间可以进行水平拓展。
HDFS视图文件系统
- 视图文件系统提供了一种管理多个Hadoop文件系统命名空间(或名命空间卷)的方法。
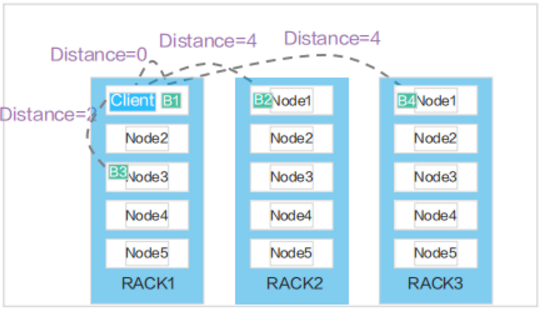
HDFS机架感知策略
- 大规模Hadoop集群节点分布在不同的机架上,同一机架上的节点往往通过同一网络交换机连接,在网络带宽方面比跨机架通信更具有优势。
- 但若某一文件数据块同时存储在同一机架上,则可能由于电力或网络故障。导致文件不可用。
- HDFS采用感知策略来改进数据的可靠性、可用性和网络带宽的利用率。
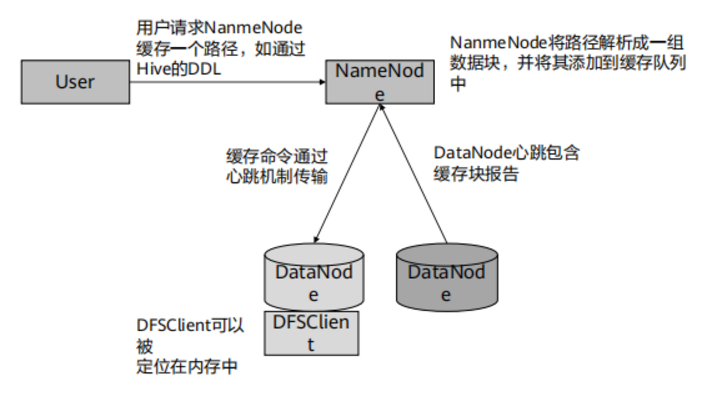
HDFS集中式缓存管理
- 当工作集的大小超过了HDFS主内存大小,会有部分工作集的数据从内存中被清除。为了防止这种情况发生,可以显式的进行锁定,避免频繁使用的数据从内存中被清除。
- 缓存可以减少CPU通过I/O去读取磁盘的次数,提高I/O的效率。
- 当块已经由DataNode缓存后,客户端可以使用一个新的,更高效的,零拷贝的读取API。
- 在每个DataNode依赖操作系统缓存区缓存时,重复读取块将导致块的所有n个副本被放入缓存区缓存。而使用集中化缓存管理,显式的锁定n个副本中的m个副本进行缓存,可以减少n-m个副本块,提高内存利用率。
HDFS集中式缓存架构
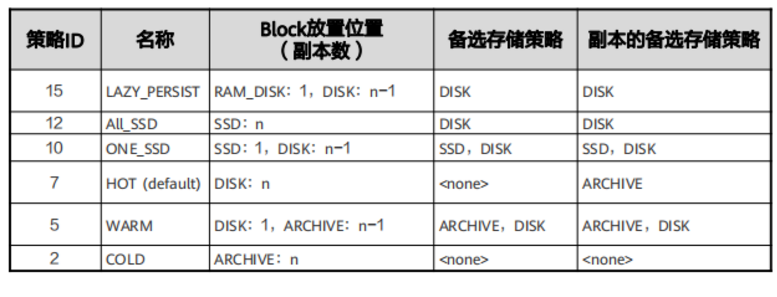
配置HDFS数据存储策略(1)
- 分级存储
HDFS的异构分级存储框架提供了RAM_DISK,SSD,DISK,ARCHIVE这四种存储类型的存储设备,以对应DataNode上可能存在不同的存储介质。
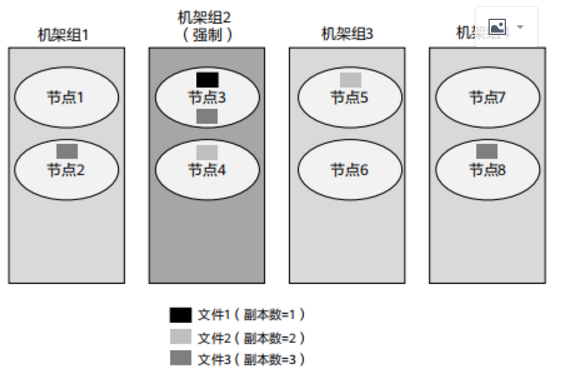
配置HDFS数据存储策略(2)
- 机架组存储
HDFS同分布
- 同分布(colocation)是将存在关联的数据或可能要进行关联操作的数据存储在相同的节点上。
- HDFS同分布的特性是将那些需进行关联的操作的文件存储在相同的数据节点,在进行关联操作时可以避免到别的数据节点上获取数据,大大减少网络带宽的占用。
HDFS操作
- 试用命令行访问HDFS
- 使用java api访问HDFS
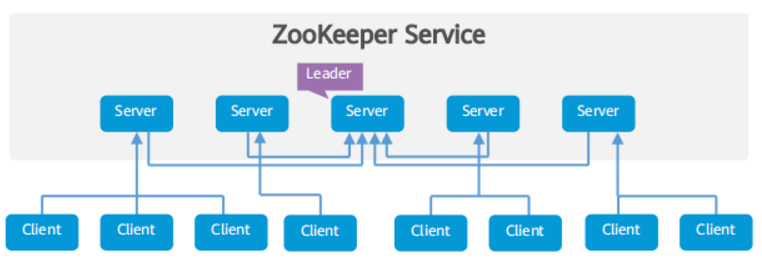
ZooKeeper体系结构
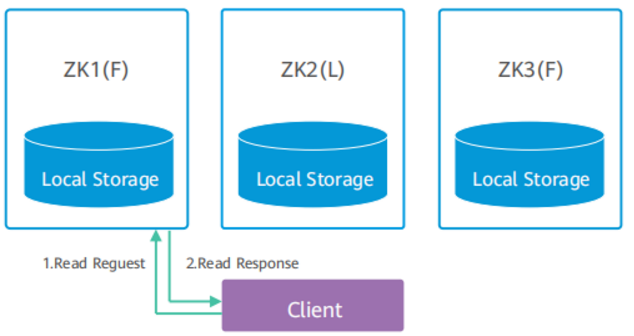
ZooKeeper读机制
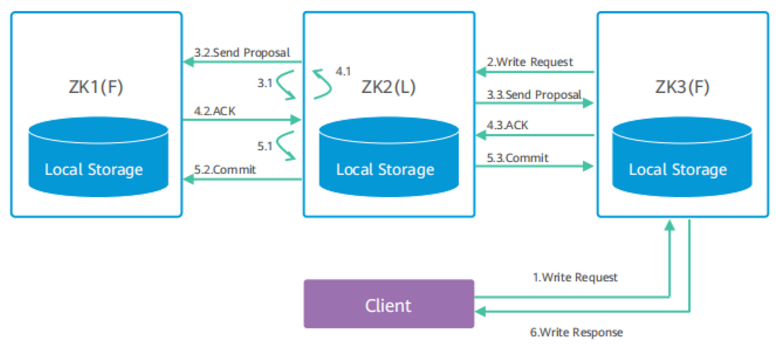
ZooKeeper写机制
ZooKeeper关键特性
- 最终一致性:客户端不论连接到哪个服务器,展示给他的都是同一个视图。
- 可靠性:具有简单,健壮,良好的特性。如果一条消息被某一台服务器接受,那么它将会被所有服务器接收。
- 实时性:zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。
- 等待无关(wait-free):慢的或者失效的客户端不得干预快速的客户端的请求,使得每个客户端都能有效的等待。
- 顺序性:包括全局有序和偏序两种。全局有序是指如果在一台服务器上消息a在消息b前发布,则在所有服务器上消息a都将在b前发布,偏序是指如果一个消息b在消息a后被同一个发送者发布,则消息a必将排在消息b前面。
- 原子性:更新只能成功或者失败,没有中间状态。
ZooKeeper命令行操作
具体常用zookeeper命令行操作如下:
- 创建节点:create /node
- 列出节点子节点:ls /node
- 创建节点数据:set /node data
- 获取节点数据:get /node
- 删除节点:delete/ node
- 删除节点及所有子节点:deleteall /node
希望和悲伤,都是一缕光。总有一天,我们会再相遇。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号