

二进制部署K8S报错集记录最新报错(七个报错,总有一个适合你,是不是很感动)
一、报错现象
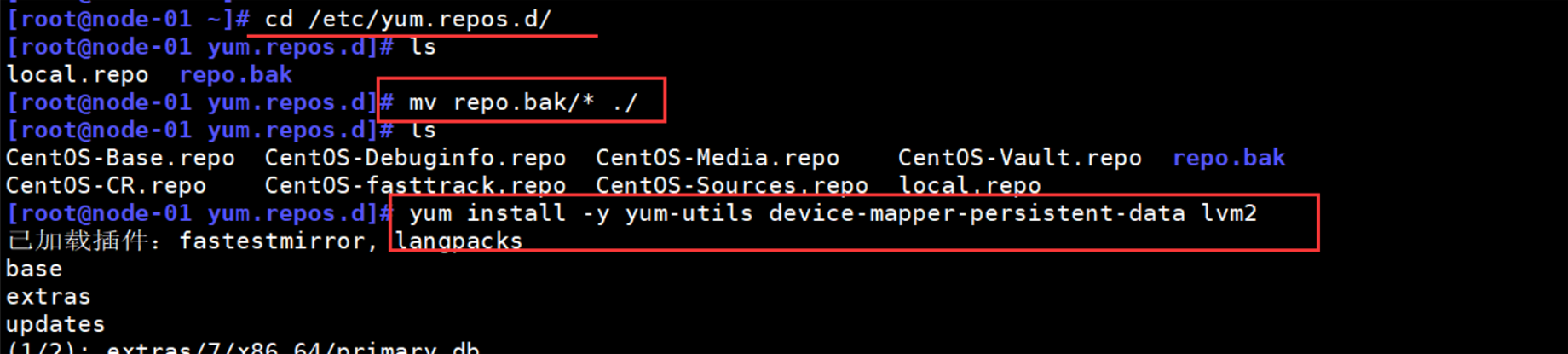

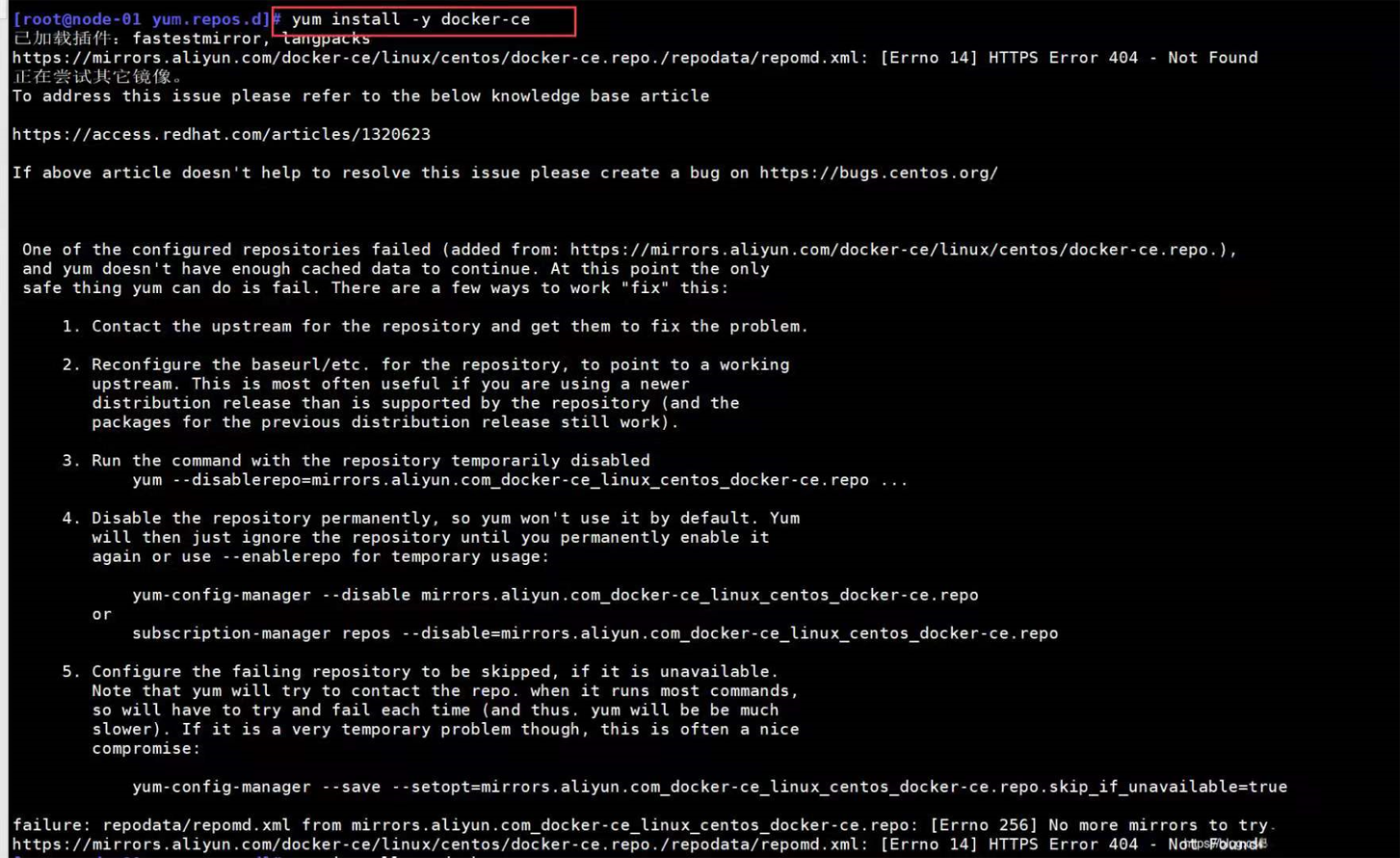



二、报错现象
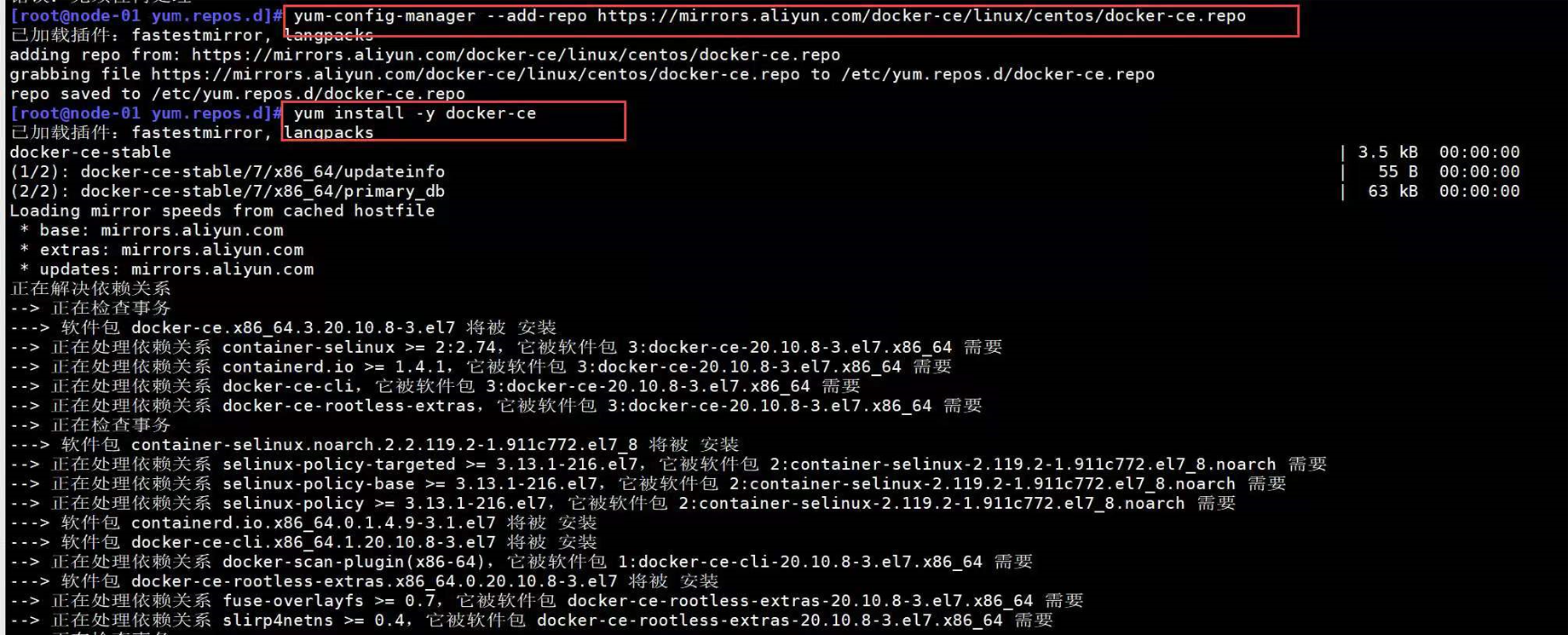
2. 解决办法
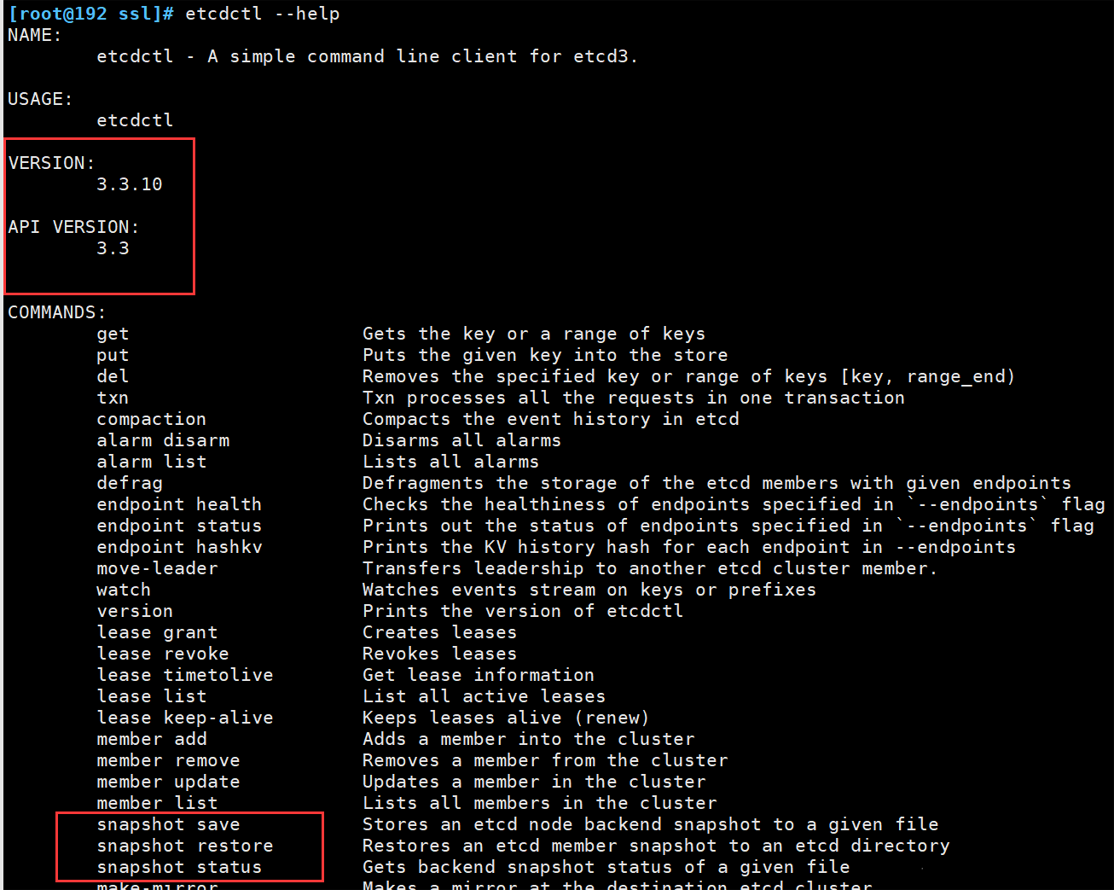
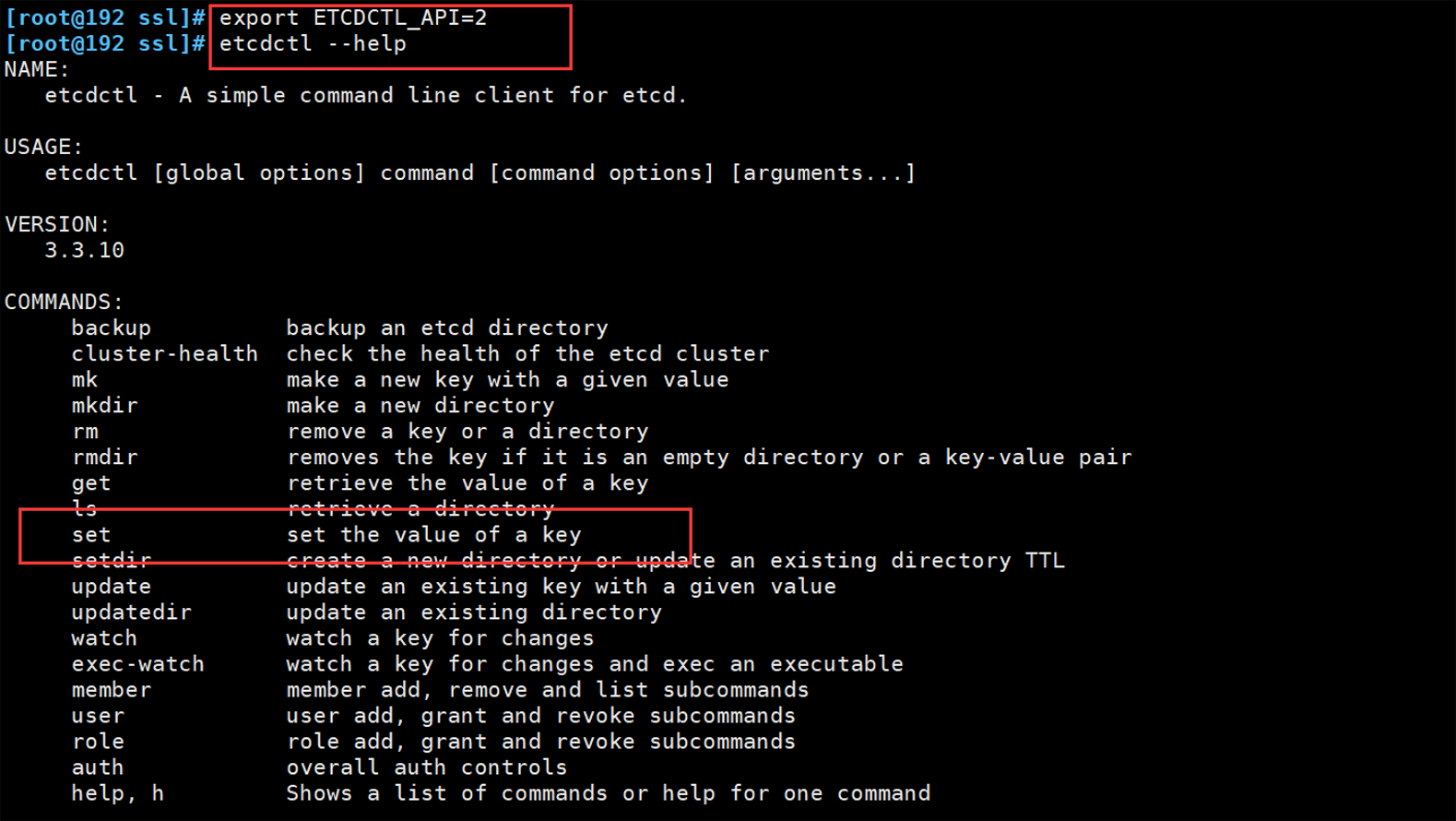

三.执行自带脚本报错
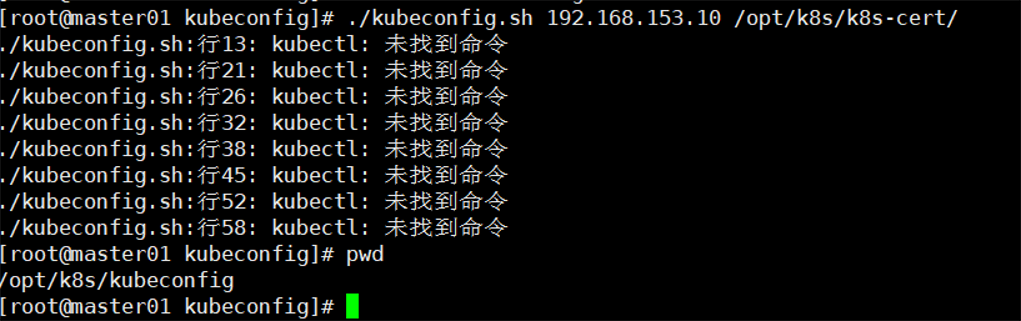
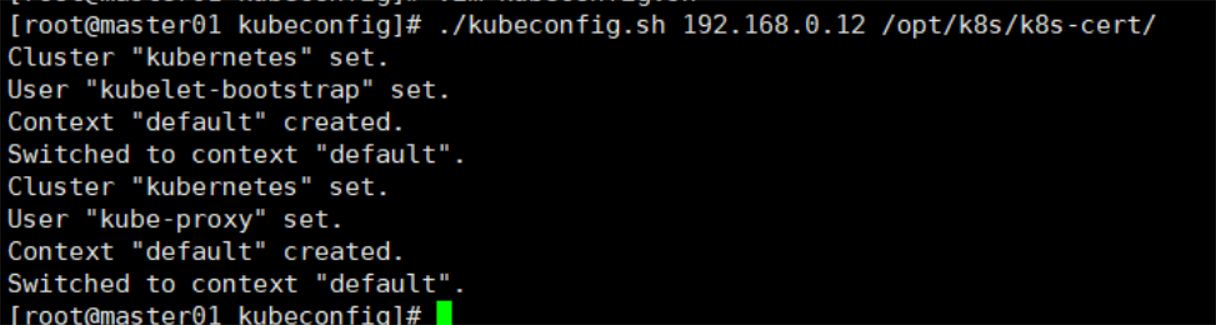

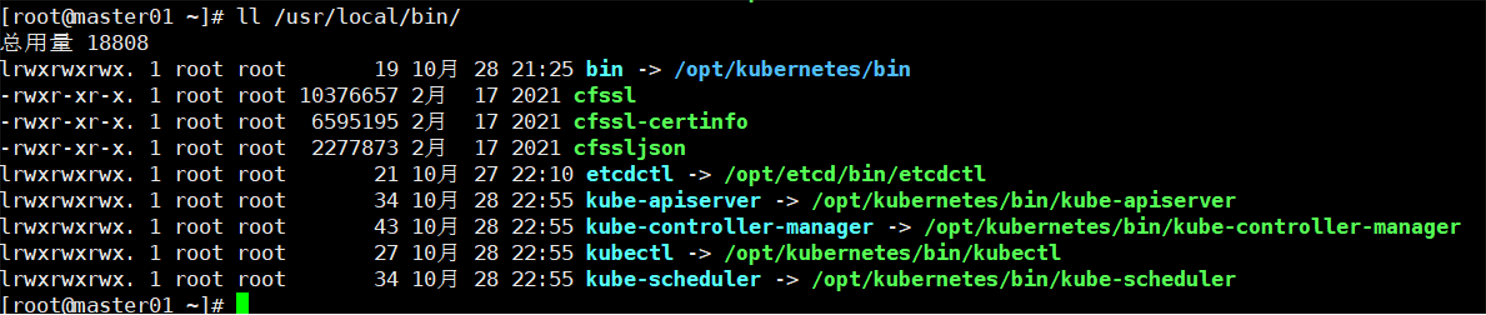
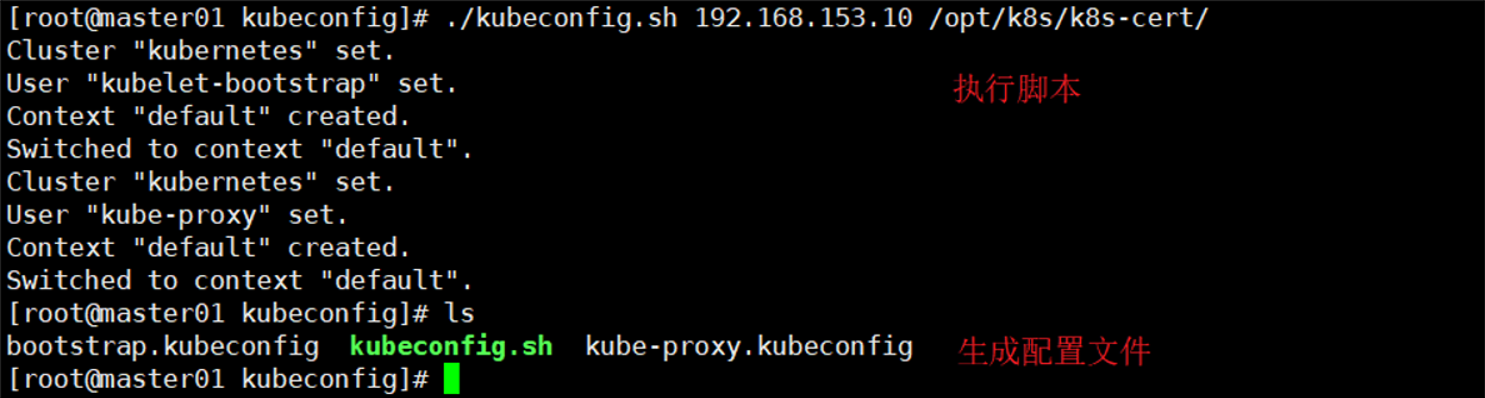
四.报错现象

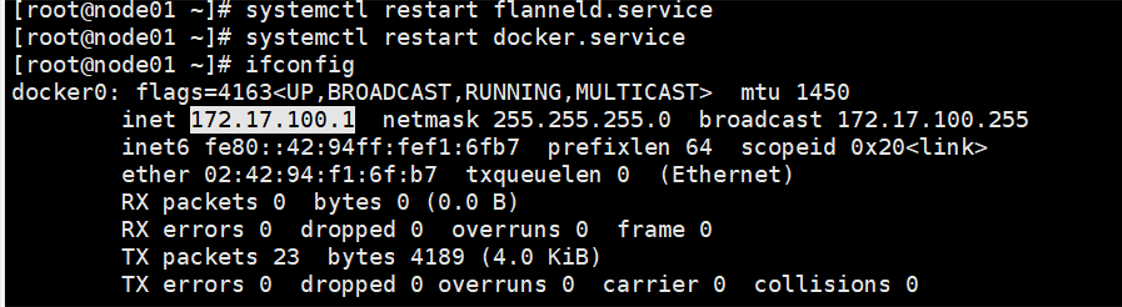
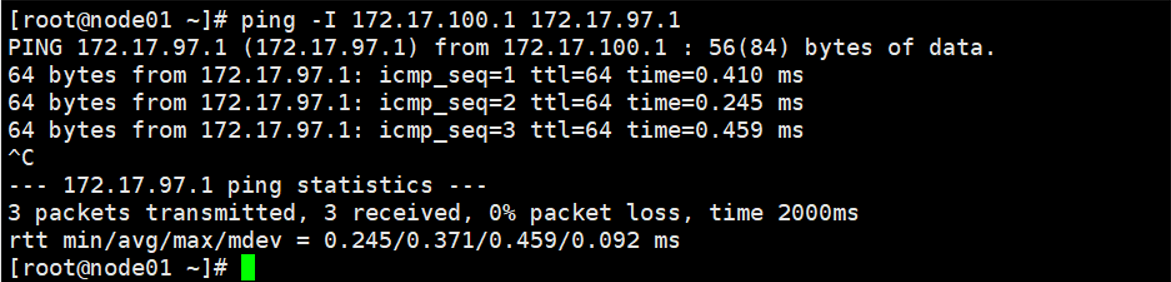
五.报错现象

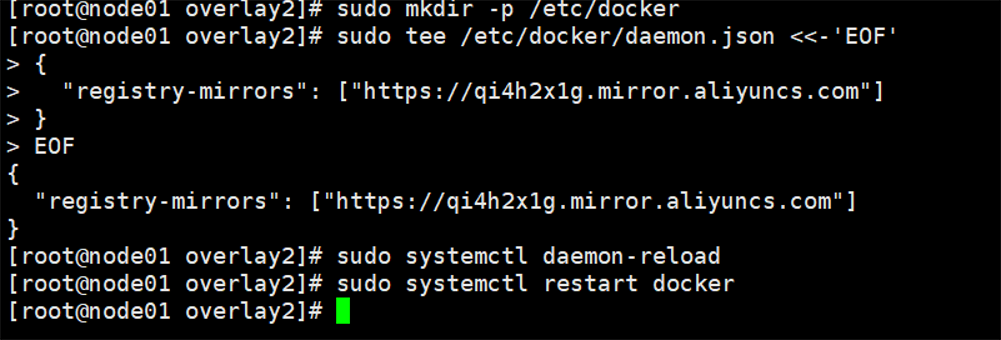
六.报错现象
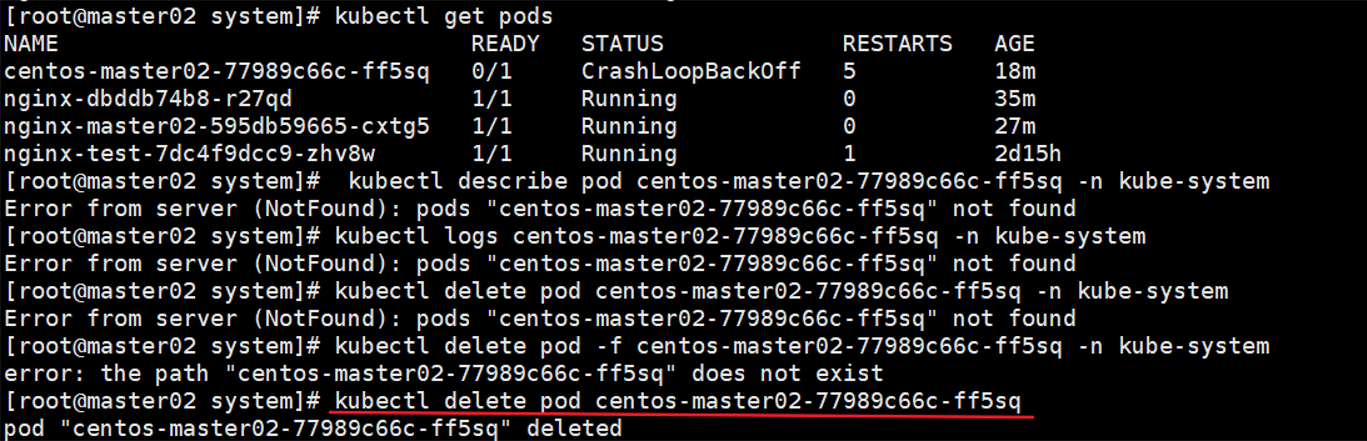
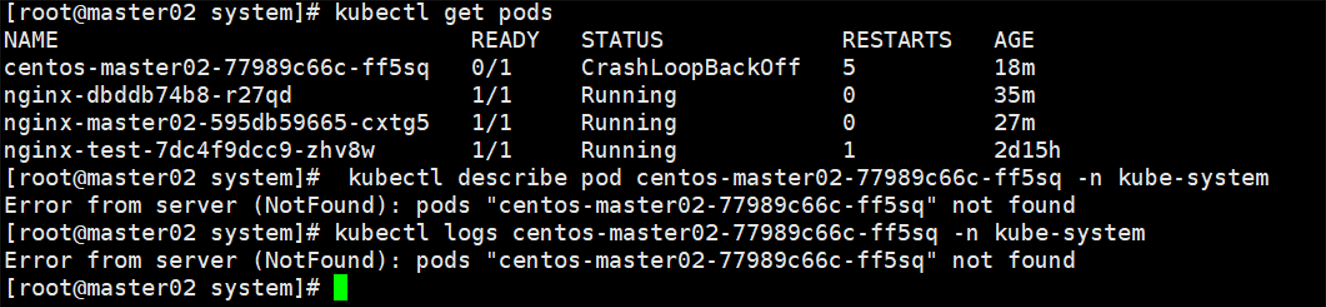
七.k8s 部署问题解决(节点状态为 NotReady)
使用kubectl get nodes查看已加入的节点时,出现了Status为NotReady的情况。
root@master1:~# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 NotReady master 152m v1.18.1
worker1 NotReady <none> 94m v1.18.1
这种情况是因为有某些关键的 pod 没有运行起来,首先使用如下命令来看一下kube-system的 pod 状态:
kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-bccdc95cf-792px 1/1 Pending 0 3h11m
coredns-bccdc95cf-bc76j 1/1 Pending 0 3h11m
etcd-master1 1/1 Running 2 3h10m
kube-apiserver-master1 1/1 Running 2 3h11m
kube-controller-manager-master1 1/1 Running 2 3h10m
kube-flannel-ds-amd64-9trbq 0/1 ImagePullBackoff 0 133m
kube-flannel-ds-amd64-btt74 0/1 ImagePullBackoff 0 174m
kube-proxy-27zfk 1/1 Pending 2 3h11m
kube-proxy-lx4gk 1/1 Pending 0 133m
kube-scheduler-master1 1/1 Running 2 3h11m
如上,可以看到 pod kube-flannel 的状态是ImagePullBackoff,意思是镜像拉取失败了,所以我们需要手动去拉取这个镜像。这里可以看到某些 pod 运行了两个副本是因为我有两个节点存在了。
你也可以通过kubectl describe pod -n kube-system <服务名>来查看某个服务的详细情况,如果 pod 存在问题的话,你在使用该命令后在输出内容的最下面看到一个[Event]条目,如下:
root@master1:~# kubectl describe pod kube-flannel-ds-amd64-9trbq -n kube-system
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Killing 29m kubelet, worker1 Stopping container kube-flannel
Warning FailedCreatePodSandBox 27m (x12 over 29m) kubelet, worker1 Failed create pod sandbox: rpc error: code = Unknown desc = failed to create a sandbox for pod "kube-flannel-ds-amd64-9trbq": Error response from daemon: cgroup-parent for systemd cgroup should be a valid slice named as "xxx.slice"
Normal SandboxChanged 19m (x48 over 29m) kubelet, worker1 Pod sandbox changed, it will be killed and re-created.
Normal Pulling 42s kubelet, worker1 Pulling image "quay.io/coreos/flannel:v0.11.0-amd64"
手动拉取镜像
flannel的镜像可以使用如下命令拉到,如果你是其他镜像没拉到的话,百度一下就可以找到国内的镜像源地址了,这里记得把最后面的版本号修改成你自己的版本,具体的版本号可以用上面说的kubectl describe命令看到:
拉去镜像:
docker pull quay-mirror.qiniu.com/coreos/flannel:v0.11.0-amd64
等镜像拉取完了之后需要把镜像名改一下,改成 k8s 没有拉到的那个镜像名称,我这里贴的镜像名和版本和你的不一定一样,注意修改:
docker tag quay-mirror.qiniu.com/coreos/flannel:v0.11.0-amd64 quay.io/coreos/flannel:v0.11.0-amd64
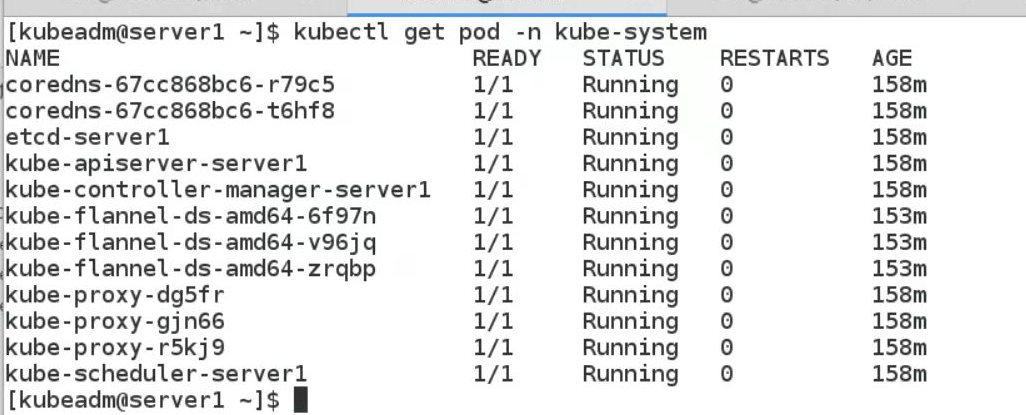
修改完了之后过几分钟 k8s 会自动重试,等一下就可以发现不仅flannel正常了,其他的 pod 状态也都变成了Running,这时再看 node 状态就可以发现问题解决了:
[kubeadm@server1 ~]$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
server1 Ready master 150m v1.18.1
server2 Ready <none> 150m v1.18.1
server3 Ready <none> 150m v1.18.1
[kubeadm@server1 ~]$


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· winform 绘制太阳,地球,月球 运作规律
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 写一个简单的SQL生成工具
· AI 智能体引爆开源社区「GitHub 热点速览」