

MySQL数据库中的高级(进阶)语句:VIEW视图、联集和常见计算(长大之后,发现满世界对你承诺,而你不敢承诺,只能忍让,偏偏忍无可忍。所有的食物都不卫生,所有的爱情都不正直,于是你依旧是个毫无依赖的小孩。)
一、VIEW(视图)
1.1 概念
可以被当作是虚拟表或存储查询
视图跟表格的不同是,表格中有实际储存资料,而视图是建立在表格之上的一个架构,它本身并不实际储存资料。
临时表在用户退出或同数据库的连接断开后就自动消失了,而视图不会消失。
视图不含有数据,只存储它的定义,它的用途一般可以简化复杂的查询。比如你要对几个表进行连接查询,而且还要进行统计排序等操作,写SQL语句会很麻烦的,用视图将几个表联结起来,然后对这个视图进行查询操作,就和对一个表查询一样,很方便。
1.2 创建、查看和删除视图
建立两张表,字段数据如下,后面测试用:
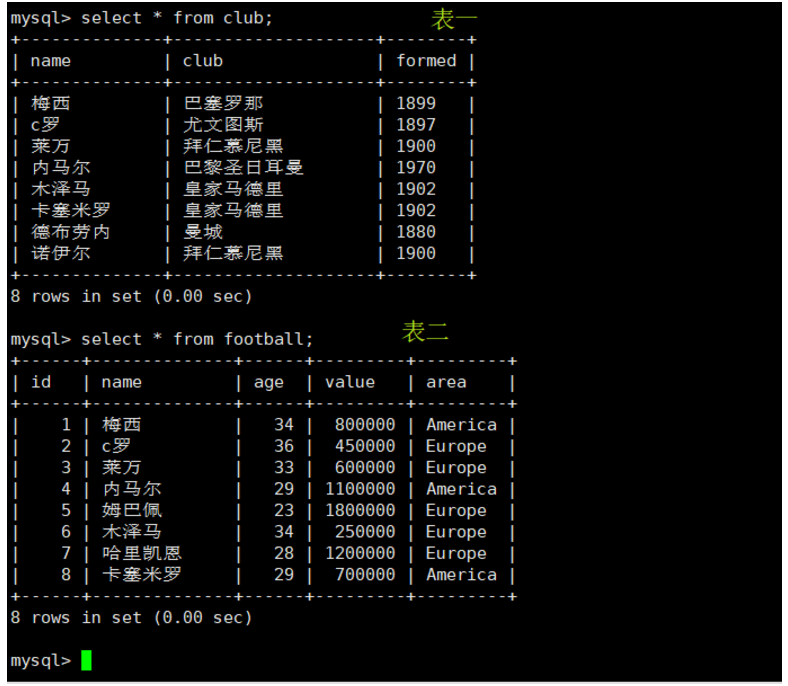
CREATE VIEW "视图表名" AS "SELECT 语句"; #创建视图表
SELECT * FROM 'V_NAME_VALUE'; #查看视图表
DROP VIEW V_NAME_VALUE; #删除视图表
实例:
CREATE VIEW V_NAME_VALUE AS SELECT A.name NAME,SUM(B.value) VALUE FROM club A INNER JOIN football B ON A.name = B.name GROUP BY NAME;
二、联集
将两个SQL语句的结果合并起来,两个SQL语句所产生的栏位需要是同样的资料种类
2.1 UNION
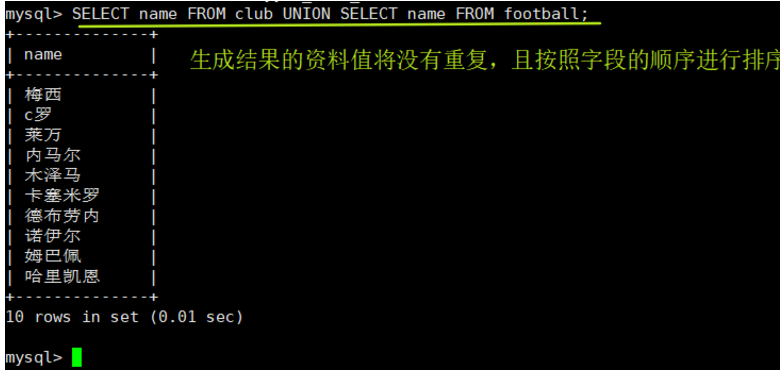
生成结果的资料值将没有重复,且按照字段的顺序进行排序
语法:[SELECT 语句 1] UNION [SELECT 语句 2];
示例:
SELECT name FROM club UNION SELECT name FROM football;
2.1 UNION ALL
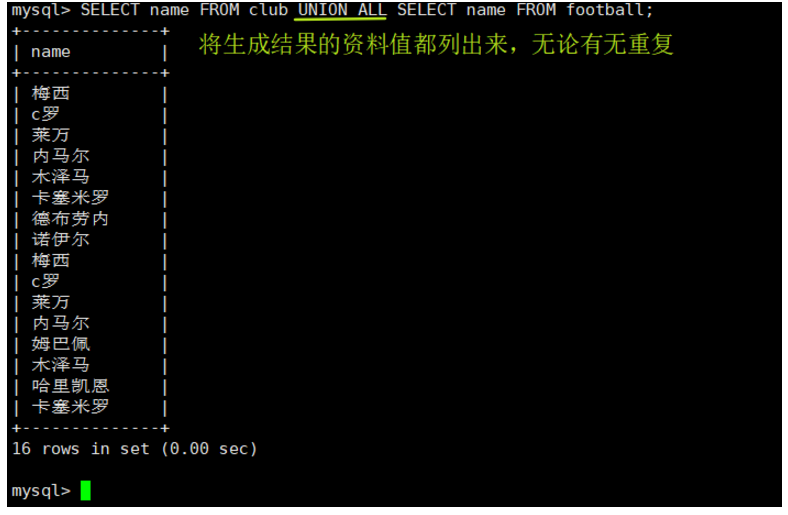
将生成结果的资料值都列出来,无论有无重复
语法:[SELECT 语句 1] UNION ALL [SELECT 语句 2];
示例:
SELECT name FROM club UNION ALL SELECT name FROM football;
三、交集值
取两个SQL语句结果的交集
SELECT A.name FROM club A INNER JOIN football B ON A.name = B.name;
SELECT A.name FROM club A INNER JOIN football B USING(name);
示例:
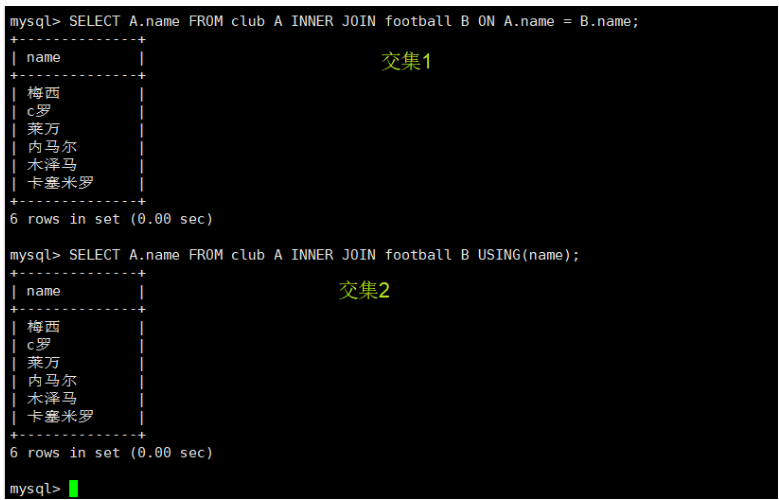
3.1 两表没有单独重复的行,并且确实有交集的时候用
SELECT A.name FROM (SELECT name FROM club UNION ALL SELECT name FROM football ) A GROUP BY A.name HAVING COUNT(*) > 1;
这里的A表示派生表
示例:
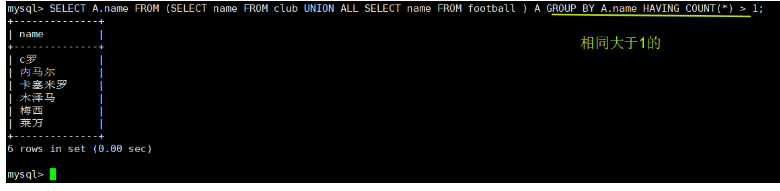
3.2 取两个SQL语句结果的交集,且没有重复
SELECT A.name FROM (SELECT B.name FROM club B INNER JOIN football C ON B.name = C.name ) A GROUP BY A.name;
SELECT DISTINCT A.name FROM club A INNER JOIN football B USING(name);
SELECT DISTINCT name FROM club WHERE (name) IN (SELECT name FROM football);
SELECT DISTINCT A.name FROM club A LEFT JOIN football B USING(name) WHERE B.name IS NOT NULL;
示例:

三、无交集值
显示第一个SQL语句的结果,且与第二个SQL语句没有交集的结果,且没有重复
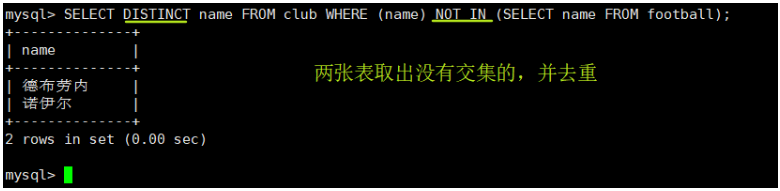
SELECT DISTINCT name FROM club WHERE (name) NOT IN (SELECT name FROM football);
实例:
四、CASE的用法
是SQL用来作为IF-THEN-ELSE之类逻辑的关键字
语法格式:
SELECT CASE (字段名)
WHEN "条件1" THEN "结果1"
WHEN "条件2" THEN "结果2"
……
ELSE "结果N"
END
FROM "表名"
#条件可以是一个数值或是公式。ELSE子句不是必须的。
示例:
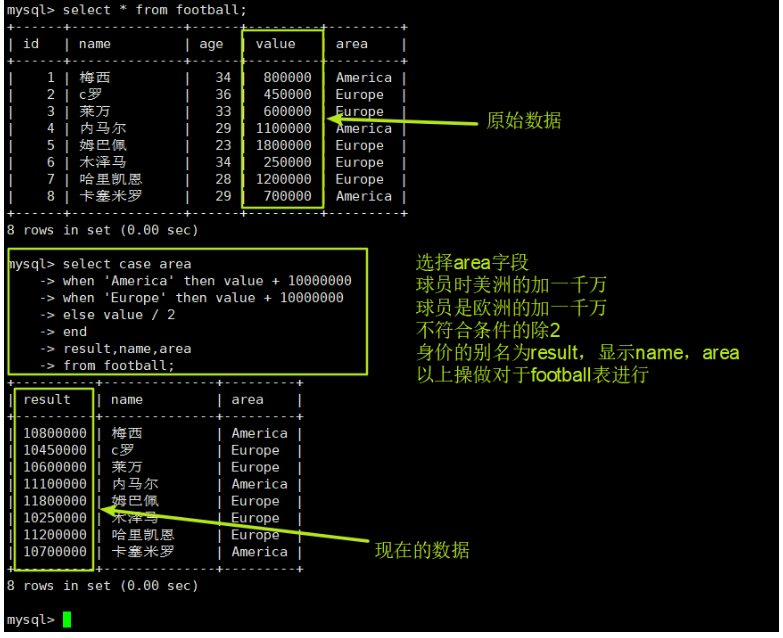
select case area #选择area字段
when 'America' then value + 10000000 #如果球员是America的就加一千万
when 'Europe' then value + 10000000 #如果球员是Europe的就减一千万
else value / 2 #其他情况除2
end #结束此case
result,name,area #别名为result,显示name和area字段
from football; #以上操作对于football表进行
五、排名的计算
表格自我连接(self join),然后将结果依序列出,算出每一行之前(包括那一行本身)有多少行数
示例:
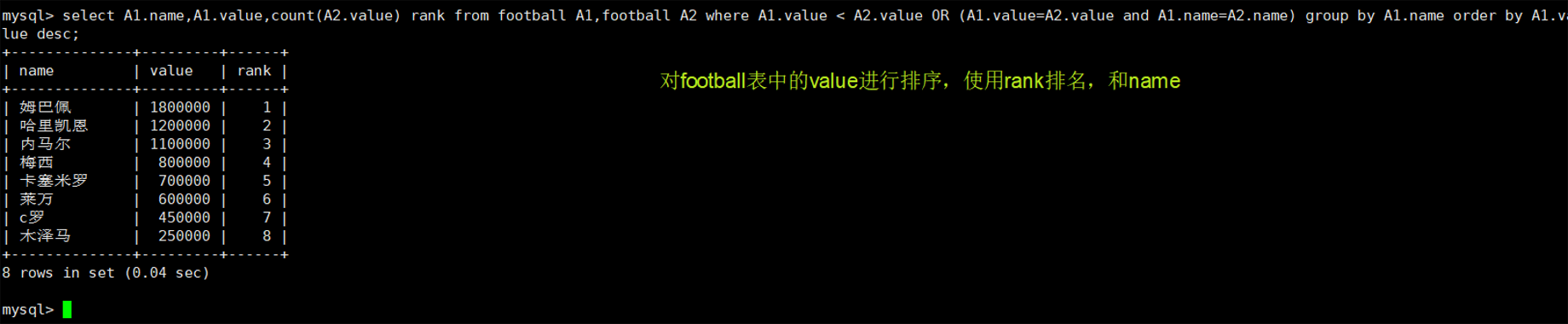
select A1.name,A1.value,count(A2.value) rank from football A1,football A2 where A1.value < A2.value OR (A1.value=A2.value and A1.name=A2.name) group by A1.name order by A1.value desc;
原理解释:
字段中的每个值跟所有的值进行比较,最大的值跟所有值比较后,大于或等于的只有一个,排名第二的值跟所有的值比较后,大于或等于的有两个,以此类推。
六、中位数的计算
## 求出中位数,显示姓名,value和排名
select * from (select A1.name,A1.value,count(A2.value) rank from football A1,football A2 where A1.value < A2.value OR (A1.value=A2.value and A1.name=A2.name) group by A1.name order by A1.value desc) A3 where A3.rank = (select (count(*)+1) DIV 2 from football);
## 求出中位数,仅显示value值
select value mid from (select A1.name,A1.value,count(A2.value) rank from football A1,football A2 where A1.value < A2.value OR (A1.value=A2.value and A1.name=A2.name) group by A1.name order by A1.value desc) A3 where A3.rank = (select (count(*)+1) DIV 2 from football);
示例:

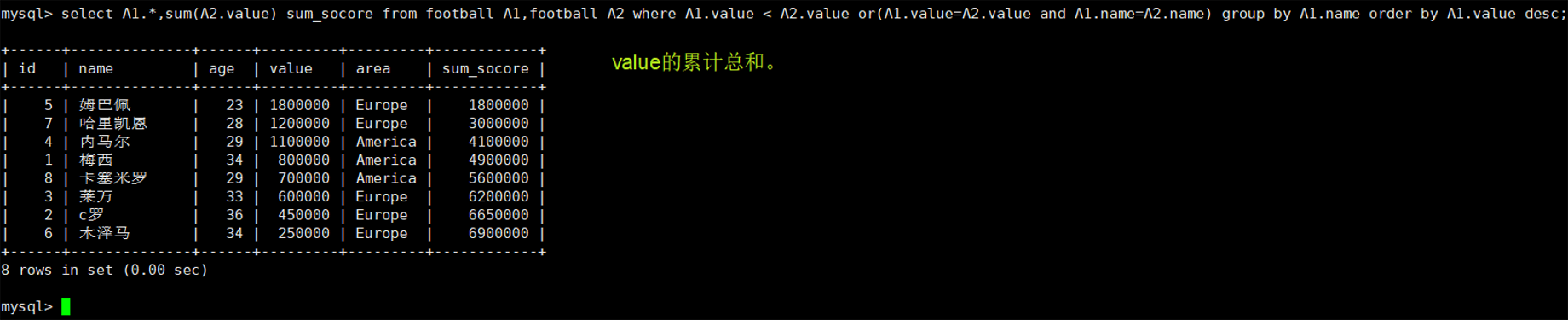
七、累积总计的计算
同字段后面中的值都是前面所有值累计而成的
例:
## 计算value的累积总计
select A1.*,sum(A2.value) sum_socore from football A1,football A2 where A1.value < A2.value or(A1.value=A2.value and A1.name=A2.name) group by A1.name order by A1.value desc;
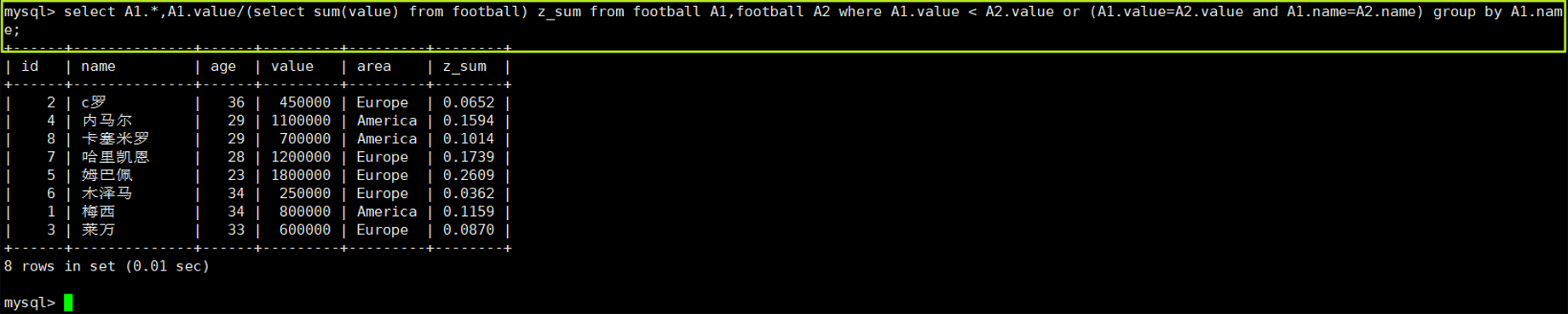
八、总合百分比的计算
每个值占总和的比例
例:
## 计算每位球员value值占整个value值的比例
select A1.*,A1.value/(select sum(value) from football) z_sum from football A1,football A2 where A1.value < A2.value or (A1.value=A2.value and A1.name=A2.name) group by A1.name;
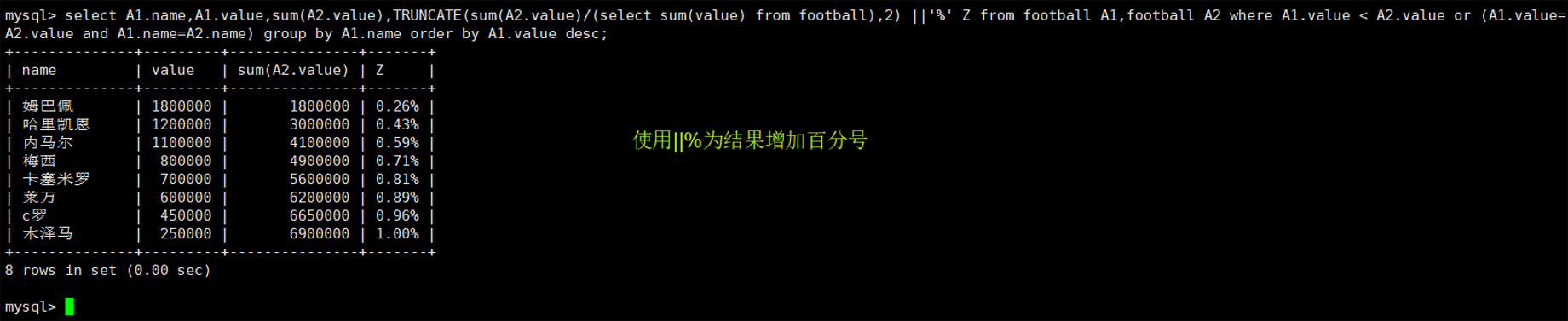
九、累积总合百分比的计算
同字段后面中的值对应的百分比都是前面所有值的百分比累计而成的
示例:
##计算value的累积总计百分比
select A1.name,A1.value,sum(A2.value),sum(A2.value)/(select sum(value) from football) Z from football A1,football A2 where A1.value < A2.value or (A1.value=A2.value and A1.name=A2.name) group by A1.name order by A1.value desc;

##计算value的累积总计百分比并用%表示出来
select A1.name,A1.value,sum(A2.value),TRUNCATE(sum(A2.value)/(select sum(value) from football),2) ||'%' Z from football A1,football A2 where A1.value < A2.value or (A1.value=A2.value and A1.name=A2.name) group by A1.name order by A1.value desc;
十、空值(NULL)和无值(“”)的区别
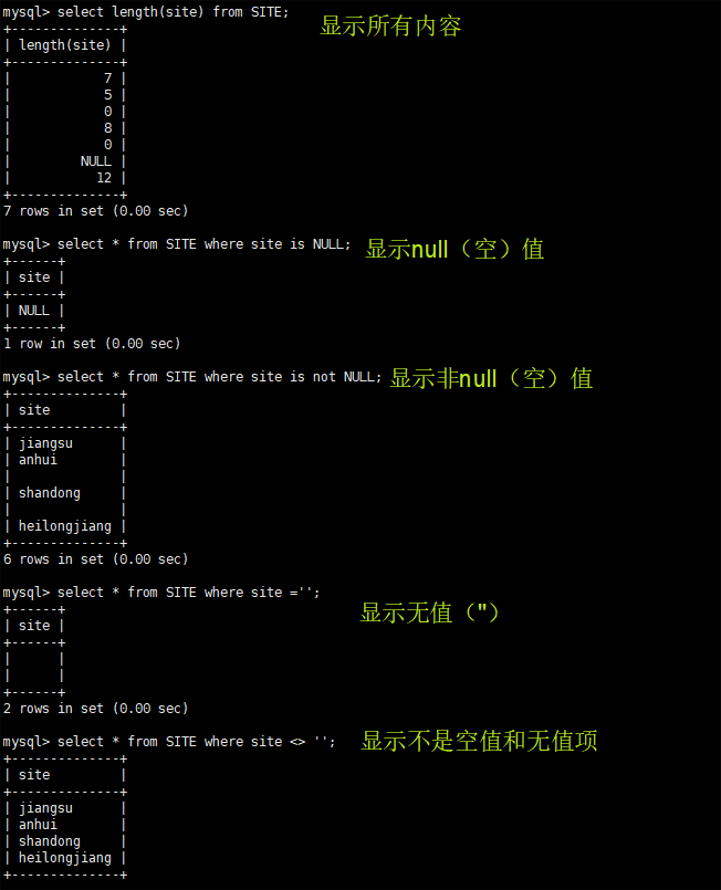
无值的长度为0,不占用空间;而空值null 的长度是null,是占用空间的;
IS NULL或者IS NOT NULL,是用来判断字段是不是NULL或者不是NULL,是不能查出是不是无值的;
无值的判断使用=’‘或者<>’'来处理。<>代表不等于;
在通过count()指定字段统计又多少行数时,如果遇到NULL值会自动忽略掉,遇到空值会自动加入记录中进行计算。
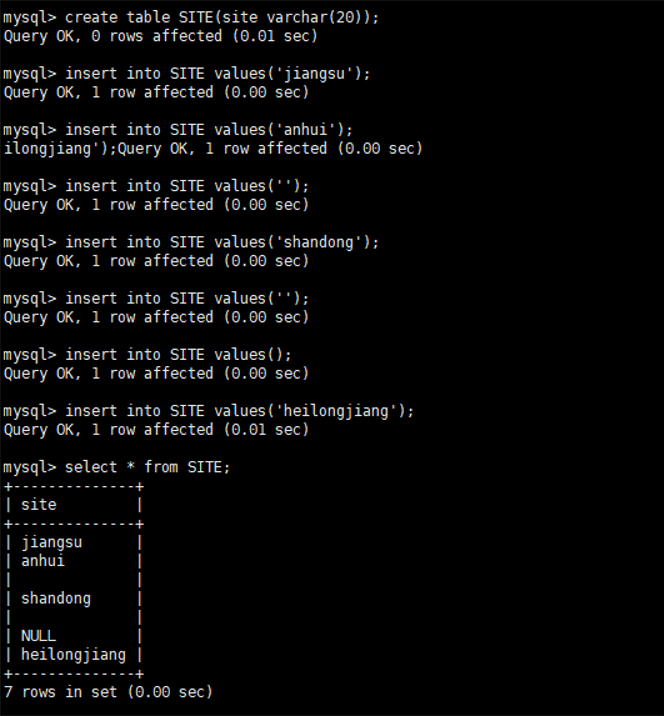
## 创建表
create table SITE(site varchar(20));
insert into SITE values('jiangsu');
insert into SITE values('anhui');
insert into SITE values('');
insert into SITE values('shandong');
insert into SITE values('');
insert into SITE values();
insert into SITE values('heilongjiang');
## 测试
select length(site) from SITE;
select * from SITE where site is NULL;
select * from SITE where site is not NULL;
select * from SITE where site ='';
select * from SITE where site <> '';
1)新建SITE表
2)测试
希望和悲伤,都是一缕光。总有一天,我们会再相遇。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 写一个简单的SQL生成工具
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)