
Linux块设备驱动程序的引入
1、块设备驱动引入
前面学习了字符设备驱动程序的编写,在字符设备驱动程序中,open、read等系统调用最终访问到驱动程序中注册的file_operations结构体提供的xxx_open、xxx_read成员函数,从而实现了对硬件的访问。字符设备这种访问机制在对设备发出读/写请求时,实际的硬件I/O一般就紧接着发生了,且一般是以字节为单位进行的,只能被顺序的读写。虽然读写过程简单、方便,但并不适用于所有的设备,比如像磁盘这类存储设备。
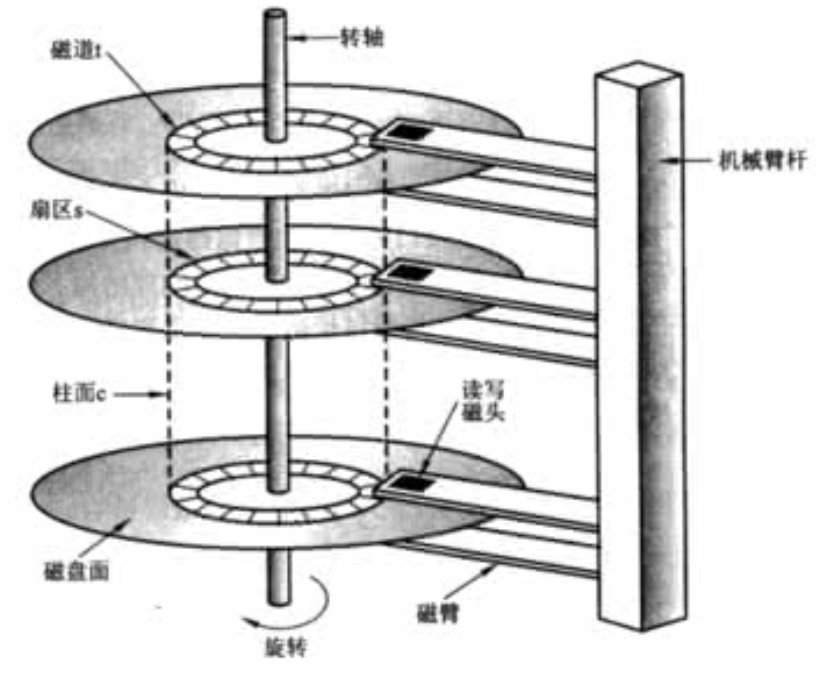
如上图所示是一个磁盘的机械结构,它有多个盘片,用于存储数据。盘片多采用铝合金材料;中间有一个主轴,所有的盘片都绕着这个主轴转动。一个组合臂上面有多个磁头臂,每个磁头臂上面都有一个磁头,负责读写数据。
现在假设有这种读写操作:先从0盘面的1磁道的0扇区读取数据,再写数据到2盘面的1磁道的3扇区,最后再从0盘面的1磁道的0扇区读取数据。如果按照字符设备的访问方式,先等磁头0定位0盘面的1磁道的0扇区时进行第一次读取数据,再等下一圈磁头2定位到盘面2的1磁盘的3扇区时完成第二次写入数据操作,最后再等待磁头0重新定位到0盘面1磁道到0扇区完成扇区0数据的读取。我们知道磁盘读取数据的时间大多花在了来回的定位磁道扇区过程,如果按照字符设备这种读取方式,需要进行2次跳转才能完成数据读取操作。
对于上述读写我们在读取时可以进行一些优化操作,比如将第一步和第三步读取数据合成在一起,在磁头0定位到0盘面1磁道的扇区0时的完成前后两次数据读取,最后等待写盘面2的1磁道的3扇区位置。于是就引入了我们今天的主题——块设备驱动程序,在块设备驱动的的I/O调度层实现了以上的优化,大大提高了设备读写效率,这也是块设备驱动引入的原因。
2、块设备驱动特点
块设备只能以块为单位接收输入和返回输出,能够随机的进行读写。块设备对应I/O请求有对应的缓冲区,因此它们可以选择以什么顺序进行响应。对于存储设备而言,调整读写的顺序作用巨大,顺序地组织块设备的访问可以提升性能。
3、块设备框架
Linux中,通常通过磁盘文件系统ext、ubifs等访问磁盘,但磁盘也有一种原始设备的访问方式,如直接访问/dev/sdb1等。所有的ext、ubifs、原始块设备又工作于VFS之下,而ext、ubfs、原始块设备之下又包含块I/O调度层以进行排序和组合。I/O调度层的作用就是将请求按照它们对应在块设备上的扇区号进行排序,以减少磁头的移动,提高数据读取效率。框架如下图所示:
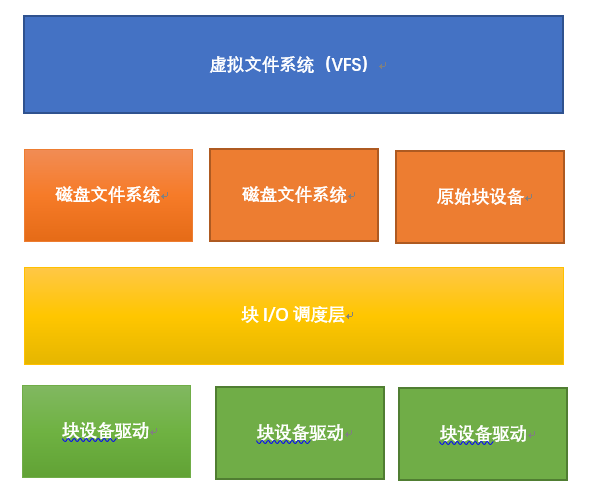
应用程序对文件的读写,经过文件系统转换成对扇区的读写,再经过块I/O调度层组合和排序优化后,通过块设备驱动程序作用于硬件。文件系统层通过统一入口函数ll_rw_block函数访问到块设备层,下面我们从ll_rw_block开始,对块设备机制进行分析
ll_rw_block(fs/buffer.c)
void ll_rw_block(int rw, int nr, struct buffer_head *bhs[]) { int i; for (i = 0; i < nr; i++) { //取出所有的buf_head struct buffer_head *bh = bhs[i]; ... if (rw == WRITE || rw == SWRITE) { if (test_clear_buffer_dirty(bh)) { ... submit_bh(WRITE, bh); //提交写标志的buf_head continue; } } else { if (!buffer_uptodate(bh)) { ... submit_bh(rw, bh); //提交读标志的buf_head continue; } } unlock_buffer(bh); }
rw: 读写标志,nr:指针数组大小, bhs:指针数组,指向多个buffer_head缓冲区
其中buffer_head结构体,就是我们的缓冲区描述符,存放缓存区的各种信息。接着继续看submit_bh,看他将buf_head信息提交给谁
submit_bh函数如下
int submit_bh(int rw, struct buffer_head * bh) { struct bio *bio; ... bio = bio_alloc(GFP_NOIO, 1); /*根据buffer_head(bh)构造bio */ bio->bi_sector = bh->b_blocknr * (bh->b_size >> 9); //存放逻辑块号 bio->bi_bdev = bh->b_bdev; //存放对应的块设备 bio->bi_io_vec[0].bv_page = bh->b_page; bio->bi_io_vec[0].bv_len = bh->b_size; //存放扇区的大小 bio->bi_io_vec[0].bv_offset = bh_offset(bh); //存放扇区中以字节为单位的偏移量 bio->bi_vcnt = 1; bio->bi_idx = 0; bio->bi_size = bh->b_size; //存放扇区的大小 bio->bi_end_io = end_bio_bh_io_sync; //设置I/O回调函数 bio->bi_private = bh; ... submit_bio(rw, bio); //提交bio ... }
submit_bh函数中分配bio结构体,并根据传入的buf_head信息构造了bio结构体,最后调用submit_bio函数提交构造的bio信息。
接着继续分析submit_bio,看他如何处理bio信息
submit_bio函数
void submit_bio(int rw, struct bio *bio) { ... generic_make_request(bio); }
submit_bio最终调用generic_make_request函数,使用上面递交的bio来构造请求(request)。
generic_make_request函数
void generic_make_request(struct bio *bio) { if (current->bio_tail) { // current->bio_tail不为空,表示有bio正在提交 /* make_request is active */ //将当前的bio放到之前的bio->bi_next里面 *(current->bio_tail) = bio; bio->bi_next = NULL; current->bio_tail = &bio->bi_next; //然后将当前的bio->bi_next放到current->bio_tail里,使下次的bio就会放到当前bio->bi_next里面了 return; } ... do { current->bio_list = bio->bi_next; if (bio->bi_next == NULL) current->bio_tail = ¤t->bio_list; else bio->bi_next = NULL; __generic_make_request(bio); //调用__generic_make_request()提交bio bio = current->bio_list; } while (bio); current->bio_tail = NULL; /* deactivate */ }
从上面的注释和代码分析到,调用generic_make_request函数,如果当前有bio请求正在处理时,将传入的bio请求挂到当前请求队列中。只有current->bio_tail为NULL,才能调用__generic_make_request(),__generic_make_request函数继续对提交的bio请求进行处理。
__generic_make_request()函数
static inline void __generic_make_request(struct bio *bio) { request_queue_t *q; int ret, nr_sectors = bio_sectors(bio); dev_t old_dev; ... do { ... q = bdev_get_queue(bio->bi_bdev); //通过bio->bi_bdev获取申请队列q ... ret = q->make_request_fn(q, bio); } while (ret); }
首先取出提交的bio中的block_device请求队列q,然后要检查对应的设备是不是分区,如果是分区的话要将扇区地址进行重新计算,最后调用请求队列q的成员函数make_request_fn完成bio的递交处理。
这个q->make_request_fn()又是什么函数?到底完成了什么工作,我们在内核中继续搜索,看它在哪里被初始化的
在内核路径中搜索make_request_fn,在blk_queue_make_request()函数中被初始化mfn这个参数,而blk_queue_make_request又在blk_init_queue_node中被调用,make_request_fn被初始化为默认的 __make_request
我们继续进行分析,看看__make_request函数中做了什么
__make_request函数
static int __make_request(request_queue_t *q, struct bio *bio) { struct request *req; ... el_ret = elv_merge(q, &req, bio); //试图将传入的bio和之前的请求合并 ...
req = get_request_wait(q, rw_flags, bio); //不能合并的情况,申请新的request结构,放入到队列中去 init_request_from_bio(req, bio); ... add_request(q, req); /*将请求加入到队列*/ ... __generic_unplug_device(q); //执行申请队列的处理函数 ... }
__make_request中尽可能的将传入的bio和之前的请求合并,如果不能进行合并,将申请新的request结构,放入到队列中,最后调用__generic_unplug_device函数
__generic_unplug_device函数
void __generic_unplug_device(request_queue_t *q) { if (unlikely(blk_queue_stopped(q))) return; if (!blk_remove_plug(q)) return; q->request_fn(q); }
__generic_unplug_device最终调用到了请求队列中的request_fn指向函数
以上函数调用顺序可如下图所示:
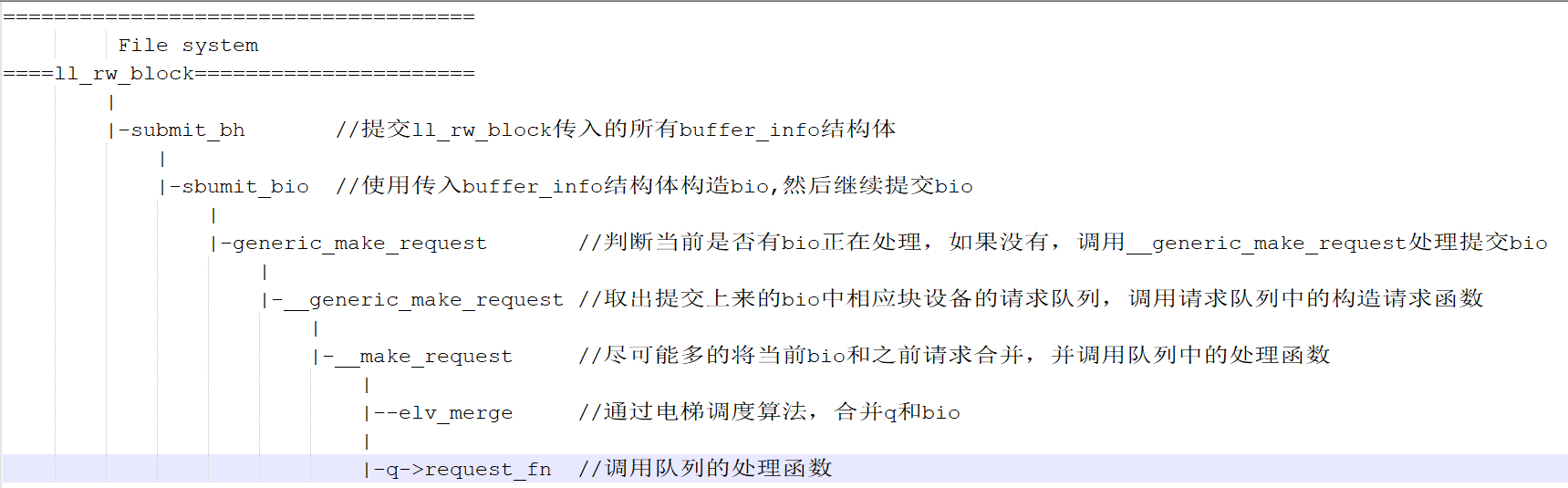
通过上面分析,我们知道了ll_rw_block作为设备块读写入口,对文件系统中传入的数据读写buf转换成bio请求,并使用电梯调度算法尽可能的对bio读写请求进行合并优化,将优化后的bio请求挂入到队列中,最后调用到队列的处理函数。
那么队列是在何处定义的呢?从上面块设备框图中可以看出,I/O调度层下面一层是块设备驱动程序,bio请求被优化后最终肯定会作用于硬件的读写,因此我们可以猜测队列是在驱动程序中定义的。在内核中搜索初始化结构体成员request_fn函数,经过查找发现请求队列中的request_fn在blk_init_queue_node中设置,blk_init_queue_node函数又被blk_init_queue调用
那么blk_init_queue函数的作用是什么呢?继续在内核中搜索,可以发现blk_init_queue函数果然是在块设备的驱动程序中的入口函数调用,印证了我们之前的猜想。
以drivers\block\acsi.c入口函数进行分析
int acsi_init( void ) { .. if (register_blkdev(ACSI_MAJOR, "ad")) { //创建一个块设备,保存在/proc/devices中 err = -EBUSY; goto out1; } ... acsi_queue = blk_init_queue(do_acsi_request, &acsi_lock); //分配一个申请队列,后面会赋给gendisk结构体的queue成员 ... for( i = 0; i < NDevices; ++i ) { acsi_gendisk[i] = alloc_disk(16); //分配一个gendisk结构体, 16:次设备号个数,也称为分区个数 if (!acsi_gendisk[i]) goto out4; } for( i = 0; i < NDevices; ++i ) { struct gendisk *disk = acsi_gendisk[i]; sprintf(disk->disk_name, "ad%c", 'a'+i); aip = &acsi_info[NDevices]; disk->major = ACSI_MAJOR; //设置主设备号 disk->first_minor = i << 4; //设置次设备号 if (acsi_info[i].type != HARDDISK) disk->minors = 1; disk->fops = &acsi_fops; //设置块设备驱动的操作函数 disk->private_data = &acsi_info[i]; set_capacity(disk, acsi_info[i].size); disk->queue = acsi_queue; //设置queue申请队列,用于管理该设备IO申请队列 add_disk(disk); //注册gendisk结构体 } ... }
blk_init_queue函数,分配并初始化了request_queue_t队列,设置队列处理函数为do_acsi_request,即上述的q->request_fn函数
register_blkdev函数,注册块设备驱动
alloc_disk/add_disk分配、设置并注册了gendisk结构体
所以看出注册一个块设备驱动,需要以下步骤:
- 创建一个块设备
- 分配一个申请队列
- 分配一个gendisk结构体
- 设置gendisk结构体的成员
- 注册gendisk结构体
