
MapReduce第一个项目
参考自林子雨大数据教学:http://dblab.xmu.edu.cn/blog/hadoop-build-project-using-eclipse/
整个过程按照实验要求
第一步创建文件夹;放入文本文件,填入一下数据。
1000481 2010-04-04 16:54:31 1001597 2010-04-07 15:07:52 1001560 2010-04-07 15:08:27 1001368 2010-04-08 08:20:30 1002061 2010-04-08 16:45:33 1003289 2010-04-12 10:50:55 1003290 2010-04-12 11:57:35 1003292 2010-04-12 12:05:29 1002420 2010-04-14 15:24:12 1001679 2010-04-14 19:46:04 1010675 2010-04-14 15:23:53 1002429 2010-04-14 17:52:45 1002427 2010-04-14 19:35:39 1003326 2010-04-20 12:54:44 1002420 2010-04-15 11:24:49 1002422 2010-04-15 11:35:54 1003066 2010-04-15 11:43:01 1003055 2010-04-15 11:43:06 1010183 2010-04-15 11:45:24 1002422 2010-04-15 11:45:49 1003100 2010-04-15 11:45:54 1003094 2010-04-15 11:45:57 1003064 2010-04-15 11:46:04 1010178 2010-04-15 16:15:20 1003101 2010-04-15 16:37:27 1003103 2010-04-15 16:37:05 1003100 2010-04-15 16:37:18 1003066 2010-04-15 16:37:31 1003103 2010-04-15 16:40:14 1003100 2010-04-15 16:40:16
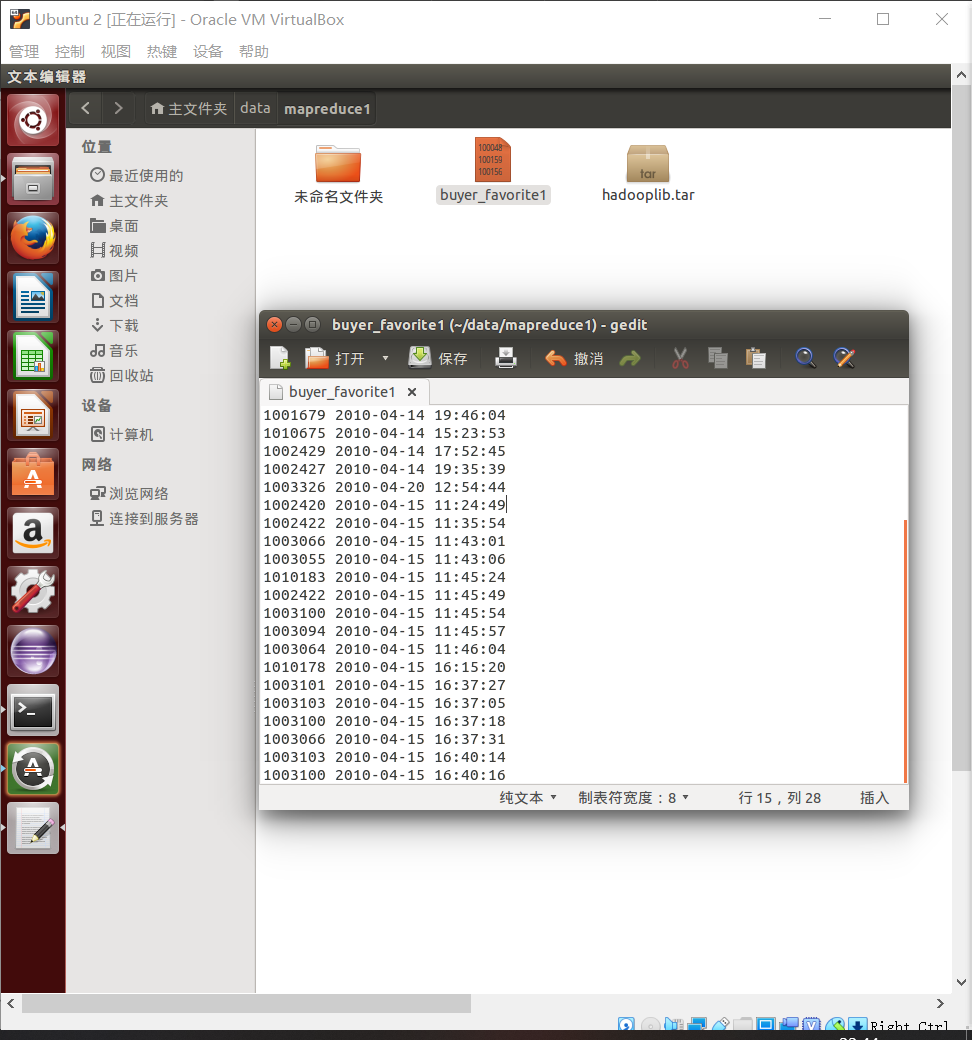
将Linux的文件上传到HDFS/mapreduce1/in的目录下


将 release 中的 hadoop-eclipse-kepler-plugin-2.6.0.jar 复制到 Eclipse 安装目录的 plugins 文件夹中运行 eclipse -clean

启动 Eclipse 后就可以在左侧的Project Explorer中看到 DFS Locations
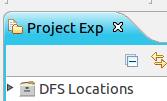
第一步:选择 Window 菜单下的 Preference。
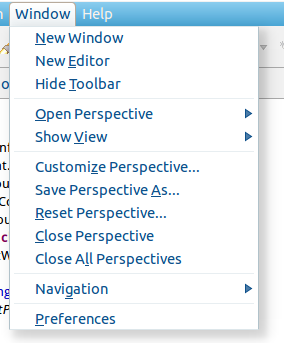
窗体的左侧会多出 Hadoop Map/Reduce 选项,点击此选项,选择 Hadoop 的安装目录
第二步:切换 Map/Reduce 开发视图,选择 Window 菜单下选择 Open Perspective -> Other(CentOS 是 Window -> Perspective -> Open Perspective -> Other),弹出一个窗体,从中选择 Map/Reduce 选项即可进行切换。
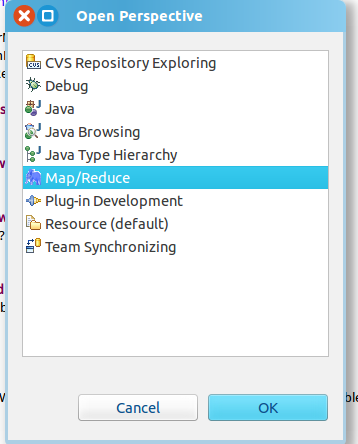
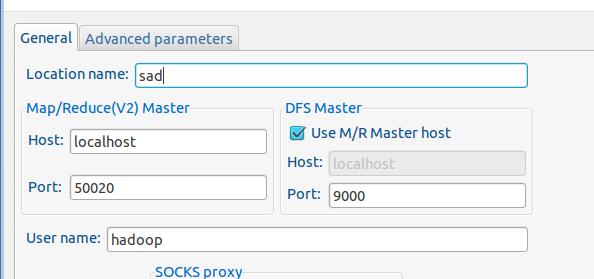
第三步:建立与 Hadoop 集群的连接,点击 Eclipse软件右下角的 Map/Reduce Locations 面板,在面板中单击右键,选择 New Hadoop Location。
Location name 随便起一个名字
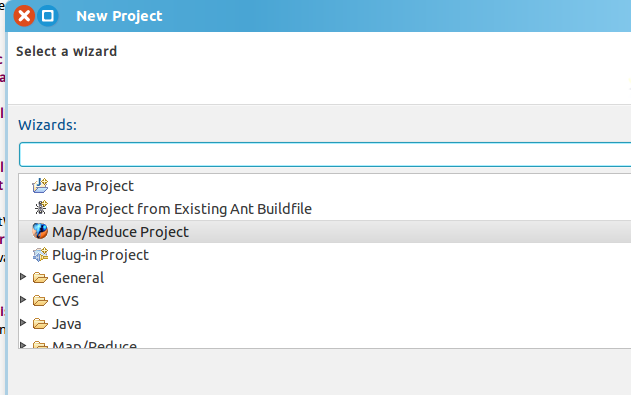
- 运行测试代码WordCount
新建项目
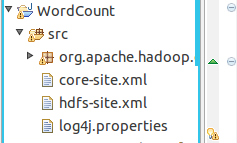
在src文件夹下将hadoop安装目录中的配置文件复制过来
core-site.xml hdfs-site.xml log4j.properties
右击项目刷新(refresh)出现以下文件
创建Demo类
package org.apache.hadoop.examples; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class Demo { public static void main(String[] args) throws IOException,ClassNotFoundException,InterruptedException { Job job = Job.getInstance(); job.setJobName("WordCount"); job.setJarByClass(WordCount.class); job.setMapperClass(doMapper.class); job.setReducerClass(doReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); Path in = new Path("hdfs://localhost:9000/mymapreduce1/in/buyer_favorite1"); Path out = new Path("hdfs://localhost:9000/mymapreduce1/out"); FileInputFormat.addInputPath(job,in); FileOutputFormat.setOutputPath(job,out); System.exit(job.waitForCompletion(true)?0:1); } public static class doMapper extends Mapper<Object,Text,Text,IntWritable>{ public static final IntWritable one = new IntWritable(1); public static Text word = new Text(); @Override protected void map(Object key, Text value, Context context) throws IOException,InterruptedException { StringTokenizer tokenizer = new StringTokenizer(value.toString()," "); word.set(tokenizer.nextToken()); context.write(word,one); } } public static class doReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); @Override protected void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException,InterruptedException { int sum = 0; for (IntWritable value : values) { sum += value.get(); } result.set(sum); context.write(key,result); } } }
运行截图:



