
老男孩全栈PYTHON -DAY6-正则表达式
1、 将 a2 当作参数 放到a3 这个函数中,执行a3这个函数,最后返回C2 这个参数
2、 参数这个参数又被当作函数进行执行,执行中打印33
3、 B2()这个函数执行的是a1 这个装饰器
4、 此时向下走,将a2 当作参数,放到a1这个函数,执行a1这个函数,最后返回c1这个参数
5、 c1参数这个参数又被当作函数进行执行,执行中打印123
6、 b1()这个函数其实是原来的a2函数,执行原来的a2函数,打印zhangsan
7、 最后返回了123
8、 r=b2() 这个b2()函数执行返回值应该是c1,但是有c1是函数,c1 返回123,所以print(r) 就是555
所以打印值应该是33 123 zhangsan 555
一层装饰器

1、将a2 替换成b2
2、执行a3() 这个函数,返回 C2, C2 又是一个函数 c2()被执行
3、执行中先打印 hao ,然后又 执行函数B2() b2=a2 所以执行 a2(),打印 jxm
4、r= b2() a()返回的是good,所以r 等于good,返回的也是good

正则表达式:
findall (从左到右一次进行匹配,匹配出的结果是一个字典)
1. . 匹配任意除换行符“\n” 外的字符 a.c abc


* 表示匹配前一个字符0或多次

+ 匹配前一个字符1次后无限次

? 表示匹配一个字符0次或者1次

^ 匹配字符串开头,在多行模式中匹配每一行的开头


$ 匹配字符串的结尾,在多行模式中匹配每一行的末尾

| 或。 匹配| 左右表达式的任意一个,从左到右匹配,如果|没有包括在()中,他的范围是整个正则表达式

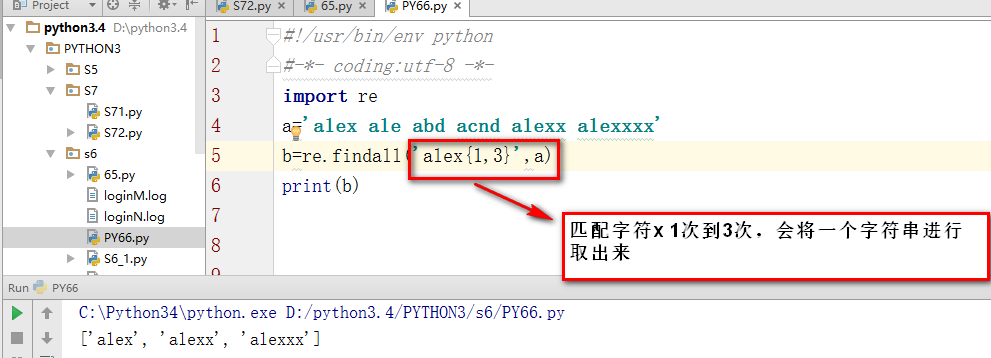
{m}匹配前一个字符串m次,{m,n}匹配前一个字符串m到n次,若省略n,则匹配m至无限次
[]字符集,对应的位置可以是紫府中的任意字符。字符集中的字符可以逐个列出,也可以给出范围,如[abc]或[a-c].[^abc]表示取反,即非abc。
所有特殊字符在字符集中都有失去其原有的特殊含义,有反斜杠转义恢复特殊字符的特殊含义


()被括起来的表达式将作为分组,从表达式左边开始没遇到一个分组的左口号‘(’,编号+1 分组表达式作为一个整体,可以后接数量词,表达式中的| 仅在改组中有效


反斜扛后边跟元字符去除特殊功能:(即将特殊字符转义成普通字符)
反斜杠货跟普通字符实现特殊功能:(即预定义字符)
引用序号对应的字组所匹配的字符串
2、预定义字符集(可以写在字符集)
\d 数字(0-9) [0-9]

\D 非数字[^\d]

\s匹配任何空白字符[空格 \t\r\n\f\v]

\S 非空白字符[^\s]

\w 匹配下划线在内的任何字符:[A-Z a-z 0-9_]

\W 匹配特殊字符的

\A 仅匹配字符串开头,同^
\Z 仅匹配字符串结尾,同$
\b 匹配 \w 和\W之间的,即匹配单词边界匹配一个单词边界,也就是指单词和空格件的位置,例如 ’er\b'可以匹配“never”中的re,但不能匹配"verb中的er


特殊用法:
(?P<name>) 分组,除了原有的编号外在制定一个额外的别名

complie()
编译正则表达式模式,返回一个对象模式。(可以把那些常用的正则表达式编译成正则表达式对象,这样可以提高一点效率
re.S 使用.匹配包括换行在内的所有字符
re.I 不匹配大小写不敏感
re.l 做本地话识别匹配,法语等
re.M多行匹配,影响^和$
re.U 根据unicode字符集解析字符,这个标志影响 \w,\W,\b,\B
complie 有点类似变量
match()
从开头开始进行匹配 注意:这个方法并不是完全匹配,当pattern结束 string 还有剩余字符,仍然是为成功,想要完全匹配,可以在表表达式末尾加上边界匹配符‘$'



search()
re.search( 表达式,字符串,模式)
re.search 函数会在字符串内查找模式匹配,只要找到第一个匹配然后返回,如果字符串没有匹配,则返回NONE
match和search 一旦匹配成功,就是一个match object 对象,而match object 对象有以下的方法:
.group() 返回被re匹配的字符串
start() 返回匹配结束的位置
end()返回匹配结束的位置
span() 返回一个元祖包含匹配(开始,结束)的位置
group() 返回re整体匹配的字符串,可以一次输入多个组号,对应组号匹配的字符串
a.group() 返回re整体匹配的字符串
b.group(n,m)返回组号n,m 所匹配的字符串,如果组号不存在,返回异常
c.groups() 方法返回一个包含正则表达式中所有小组字符串的元祖,从1到所含的小组号,通常groups 不需要参数,返回一个元祖,元祖中的元就是正则表达式中的组

findall 遍历匹配,可以获取字符串中的所有匹配的字符串,返回一个列表
re(表达式,字符串,flags)
finditer()
搜索string,返回一个顺序访问额每一个匹配结果(match对象)的迭代器,找到re匹配所有的字符串,并把他们作为一个迭代器返回
格式:
re.finditer (表达式,字符串、flags)
split()
按照能匹配的字符串将string分割后返回列表
可 以使用re.split来分割字符串 re.splie(表达式,字符串,最大分割次数)
以使用re.split来分割字符串 re.splie(表达式,字符串,最大分割次数)

sub()
使用re替换string中每一个匹配自负床返回替换后的字符串
re.sub (表达式,替换的内容,字符串,替换的个数)

subn() 返回替代的次数
subn(表达式,替换的内容,字符串 数量 模式)


注意点:
re.match 与re.seatch 与re.findall 的区别:
re.match 只匹配字符串的开始,如果字符串不符合正则表达式,则匹配失败,函数返回None:而re.search 匹配整个字符串,直到找到下一个匹配。
贪婪匹配和非贪婪匹配
*?,+?,??,{m,n} 前面的*,+,等都是贪婪匹配,也是尽可能匹配,后面加? 号使其变成惰性匹配


3、用flags时遇到的小坑
print(re.split('a','1A1a2A3',re.I))#输出结果并未能区分大小写
这是因为re.split(pattern,string,maxsplit,flags)默认是四个参数,当我们传入的三个参数的时候,系统会默认re.I是第三个参数,所以就没起作用。如果想让这里的re.I起作用,写成flags=re.I即可。
1、匹配电话号码
p = re.compile(r'\d{3}-\d{6}')
print(p.findall('010-628888'))
2、匹配IP
re.search(r"(([01]?\d?\d|2[0-4]\d|25[0-5])\.){3}([01]?\d?\d|2[0-4]\d|25[0-5]\.)","192.168.1.1")


 浙公网安备 33010602011771号
浙公网安备 33010602011771号