

https://github.com/031902518/031902518
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 50 |
| · Estimate | · 估计这个任务需要多少时间 | 400 | 600 |
| Development | 开发 | 60 | 180 |
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 20 |
| · Design Spec | · 生成设计文档 | 10 | 10 |
| · Design Review | · 设计复审 | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 30 | 70 |
| · Coding | · 具体编码 | 240 | 360 |
| · Code Review | · 代码复审 | 40 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 20 | 30 |
| Reporting | 报告 | 30 | 50 |
| · Test Repor | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 20 | 25 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 100 |
| · 合计 | 990 | 1625 |
二、计算模块接口
- (3.1)计算模块接口的设计与实现过程。
因为本人比较笨,不是很会用什么高级的算法,只是用最简单的遍历一遍,没有用到类和函数(主要是我觉得我这个想法没什么技术含量,思想过于简单,用不上构造类和函数,也只能实现最基本的查询,但是main里的思想就是:首先把待检测文件读入,在读入一个一个的敏感词,然后每个字每个字一个一个的对比,如果是中文就判断中文的条件,如果是英文就按照英文的语句执行,最后用一个total来记录敏感词的个数,但并不能都检测出来(比如拆分和拼音首字母都不行)),主要思想就是遍历,把org文件一行一行读入然后和他们敏感词比较,如果找到就输出。并且又有中英文之分。如果是中文就判断中间是否有可能进行一些伪装,在敏感词中插入除字母、数字、换行的若干字符仍属于敏感词,会在判断出来。但是因为本人能力有限并不能实现:谐音替换、拼音替代、拼音首字母替代以及中文文本中还存在少部分较难检测变形如繁体、拆分偏旁部首(只考虑左右结构),不存在变形后再拆开偏旁部首的情况。 - (3.2)计算模块接口部分的性能改进。
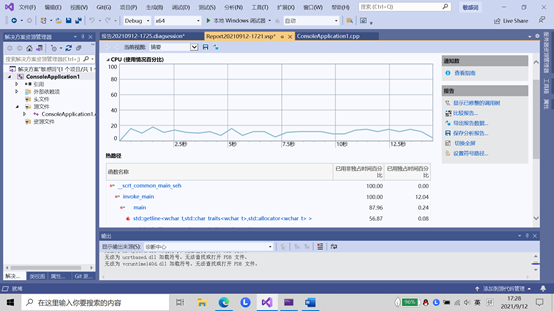
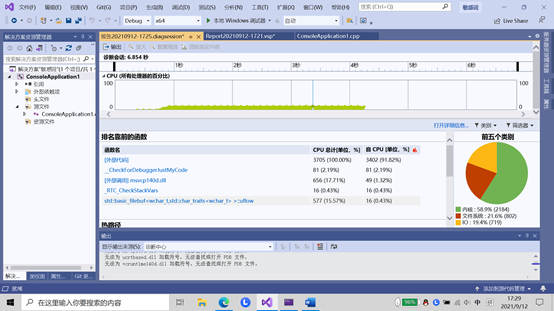
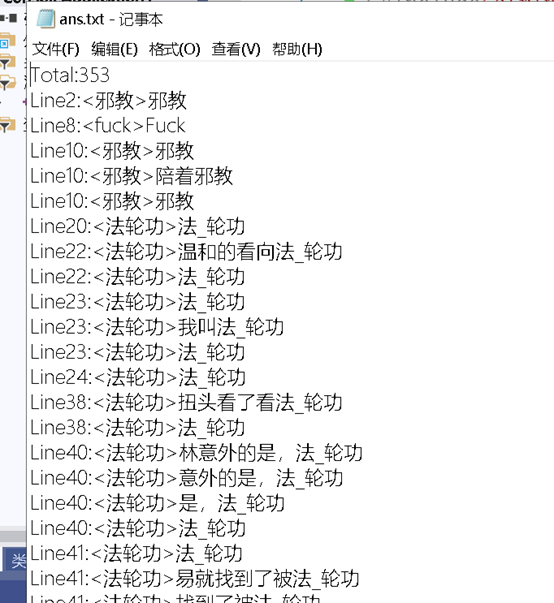
从以上图片可以看出,占据主要时间的是执行程序,然后是输入输出的IO时间,因为给定一个黑名单词汇文件和待检测文件,要求在答案文件中输出检测出敏感词汇的数量并按出现输出行号,敏感词词汇及对应检测出的文本。所以要反复读入作比较,还有就是文件系统因为要频繁的读入敏感词,搜索到后还要输出,所以也是在预计范围内。因为有很多循环的关系所以个人感觉会超时间,主要思想就是遍历,把org文件一行一行读入然后和他们敏感词比较,如果找到就输出,不是很会用什么高级的算法,只是用最简单的遍历一遍,反复的读取文件也花了很多时间,本来是想用些方法来改进一下自己的程序,但是后来上网一查发现以自己目前的能力没有办法实现
- (3.3)计算模块部分单元测试展示。
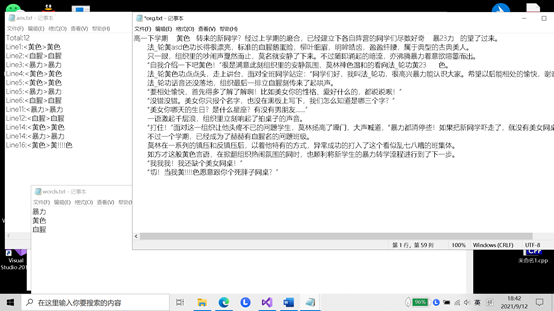
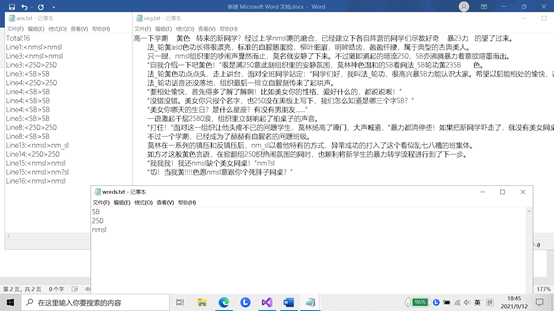
- (3.4)计算模块部分异常处理说明。
- infile2.open(ors);//用来打开文档
if (!infile2) { cout << "org fail!" << endl; }
如果待测试文档打开失败则输出org fail
infile1.open(wos);//用来打开敏感词
if (!infile1) { cout << "words fail!" << endl; }
如果待测试敏感词文档打开失败则输出words fail
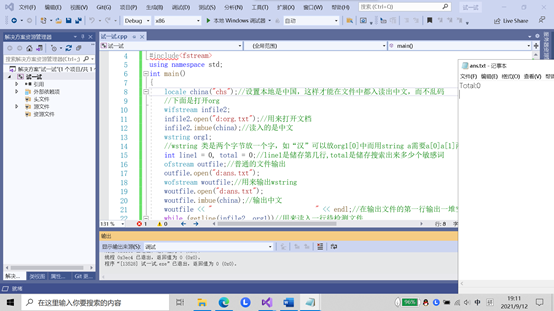
2.我的电脑笔记本默认是ANXI,所以设计的时候就用Visual Studio 2019 的ANXI写的,后来要求必须用UTF-8导致输出了大量错误,如下图,后来在测试组同学们的帮助下,在代码中加了一个locale china("zh_CN.UTF-8");才对的,同时,先学习了fstream等知识,掌握基本的读写文件流,这里也要先感谢一下测试组同学的大力帮助
3.老师说的很对很对:读清题目很重要、很重要、很重要(重要的事情说三遍),我就是因为没考虑到敏感词的出现先后问题,所以后来又小改了一下一开始想用string存放文件中的一行数据,后来发现string两个单位存储一个字,输出时比较困难,甚至输出的时候容易难以区分汉字和英文的区别,后来上网上看到了wstring,感觉很是好用,又学到了新的知识。wstring可以实现一个单元两个字节,这样子比较汉字的时候就方便多了
三、心得
1.因为本人比较菜,所以每天熬夜打代码,虽然没能实现全部要求,但是我已经把自己能够做到的都做了,已经不后悔了。
2.读清题目很重要,我就是因为没考虑到敏感词的出现先后问题,所以后来又小改了一下。
3.对github的应用更加明白
4.测试txt文件的读写功能时,发现中文的乱码现象,上网查后,发现txt文件默认用utf-8编码,而Windows控制台默认用ANSI编码,故控制台会出现中文的乱码
5.用c++写,先学习了fstream等知识,掌握基本的读写文件流
6..编写函数,输入为文章的一行和一个敏感词;遍历该行,找到敏感词即输出
7.将结果打印,在目标位置生成txt文件;
