2020软工实践第二次结对作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/SE2020 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/SE2020/homework/11277 |
| 这个作业的目标 | 结对实现学术家族树的编程,学习前端内容和单元测试的知识 |
| 学号 | 031802223 刘东权 031802219 林璟 |
| Github地址 | https://github.com/DQbryant/031802223-031802219 |
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| Estimate | 估计这个任务需要多少时间 | 30 | 60 |
| Development | 开发 | ||
| Analysis | 需求分析 (包括学习新技术) | 120 | 120 |
| Design Spec | 生成设计文档 | 20 | 30 |
| Design Review | 设计复审 | 10 | 10 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 20 |
| Design | 具体设计 | 30 | 30 |
| Coding | 具体编码 | 300 | 320 |
| Code Review | 代码复审 | 60 | 60 |
| Test | 测试(自我测试,修改代码,提交修改) | 300 | 360 |
| Reporting | 报告 | ||
| Test Report | 测试报告 | 30 | 60 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 100 | 120 |
| 合计 | 1020 | 1200 |
二、具体分工
- 我负责的是html、css,并修改了部分js,准备测试数据,以及撰写博客。
- 我的队友负责js的部分,实现对输入字符串的解析和学术家族树的呈现,以及单元测试。
三、解题思路和设计实现
实现思路
项目使用了bootstrap+jquery+echarts,采用传统的html+css+js实现。作业要求解析固定格式的字符串并生成对应的学术家族树图,所以首先要解析字符串,通过三个换行符分隔每棵树的字符串,分别解析各个字符串的第一行(生成导师信息),第二行(块)获得学生信息,后面逐行获取各个学生的技能或经历信息,并将每个学生的信息存入map中,解析完每棵树的字符串后生成对应json如{name:"张三",children:[{name:"2018级研究生",children:[{name:"刘四",value:""},{name:"王五",value:""}]},{name:"2019级本科生",children:[{name:"赵四",value:"},{name:"李五",value:""}]}]},再使用echarts.js生成每个json的树图,点击时显示学生技能而不是展开学生节点,因为经测试,设置学生节点可展开,将每个技能或经历作为其子节点由于echarts的缘故不够美观,因此将学生技能和经历设置为点击学生节点后在左侧显示。
关键数据流图

核心代码片段
/**
* 将输入的文本转为需要的js对象
* @param {*} treeText 输入的文本
*/
function parse(treeText) {
let lines = treeText.split('\n');
let data = new Object();
let map = new Map();
data.name = lines[0];
if (lines[0].slice(0, 2) !== '导师') {
throw new Error('ERROR: 导师行不正确,请注意每组数据之间有两行空行');
}
data.children = new Array();
// 对每一行进行解析
for (let i = 1; i < lines.length; i++) {
if (lines[i] === '') continue;
// 当前行是学生列表
if (!isNaN(lines[i].slice(0, 4))) {
var children = new Object();
console.log(lines[i].search('级博士生|级硕士生|级本科生'))
if (lines[i].split(':').length <= 1 || (lines[i].search('级博士生|级硕士生|级本科生')) == -1) {
throw new Error('ERROR: 学生信息解析不正确');
}
children.name = lines[i].split(':')[0];
children.children = new Array();
// 对于每一个学生
lines[i].split(':')[1].split('、').forEach(item => {
var t = new Object();
t.name = item;
t.value = '暂无';
children.children.push(t);
// 将当前对象存入map方便后面修改技能信息
map.set(item, t);
})
data.children.push(children);
// 当前行是技能信息
} else {
let [name, skill] = lines[i].split(':')
// 如果技能文字为空
if (!skill) {
throw new Error('ERROR: 节点技能输入不正确');
}
if (!map.get(name)) {
throw new Error("学生 " + name + "不存在")
}
map.get(name).value = skill;
}
}
const domText = '<div class="graph" style="width: 100%;height:350px;"></div>';
$(".graph-wrapper").append(domText);
return data;
}
该函数的功能是将输入的文本转为需要的 js 对象。首先将文本按行分割。第一行默认是导师行,将导师的节点作为树的根节点,之后对每一行进行解析。若前4个均为数字,则为学生列表行,因为输入数据的分隔符比较明显,所以直接通过 ':' 和 ‘、’ 进行分割后解析。同时,为了避免后面读入技能信息时进行树的遍历,这里将每一个叶节点暂存到了 map 里,这样,后面就可以以 O(1) 的时间来更新对应节点的技能。
五、特点设计和展示
创意独到之处
- 支持文件上传,保存学术家族树图
设计的意义
- 文件上传:可以方便用户在本地编辑用例数据,组织更方便。
- 保存学术家族树图:用户可以快速下载需要的学术家族树图,而不用自己手动截图。
文件上传实现思路&代码片段
/**
* 文件上传辅助函数
*/
function upload() {
$('#fileinp').click();
}
/**
* 文件上传功能
*/
function fileUpload() {
let file = document.getElementById('fileinp').files[0];
let reader = new FileReader();
reader.readAsText(file, 'utf-8');
reader.onload = function () {
$(".input-area").val(reader.result);
analyse();
}
}
- 实现思路:因为上传文件的表单控件比较难看,而且样式不方便修改,所以将该控件隐藏,并且通过给按钮绑定事件,通过按钮的点击事件触发表单的点击事件来实现文件上传。上传之后,通过 FileReader 这个类读取文件,并将文本写入输入框,之后,直接调用解析函数绘图。
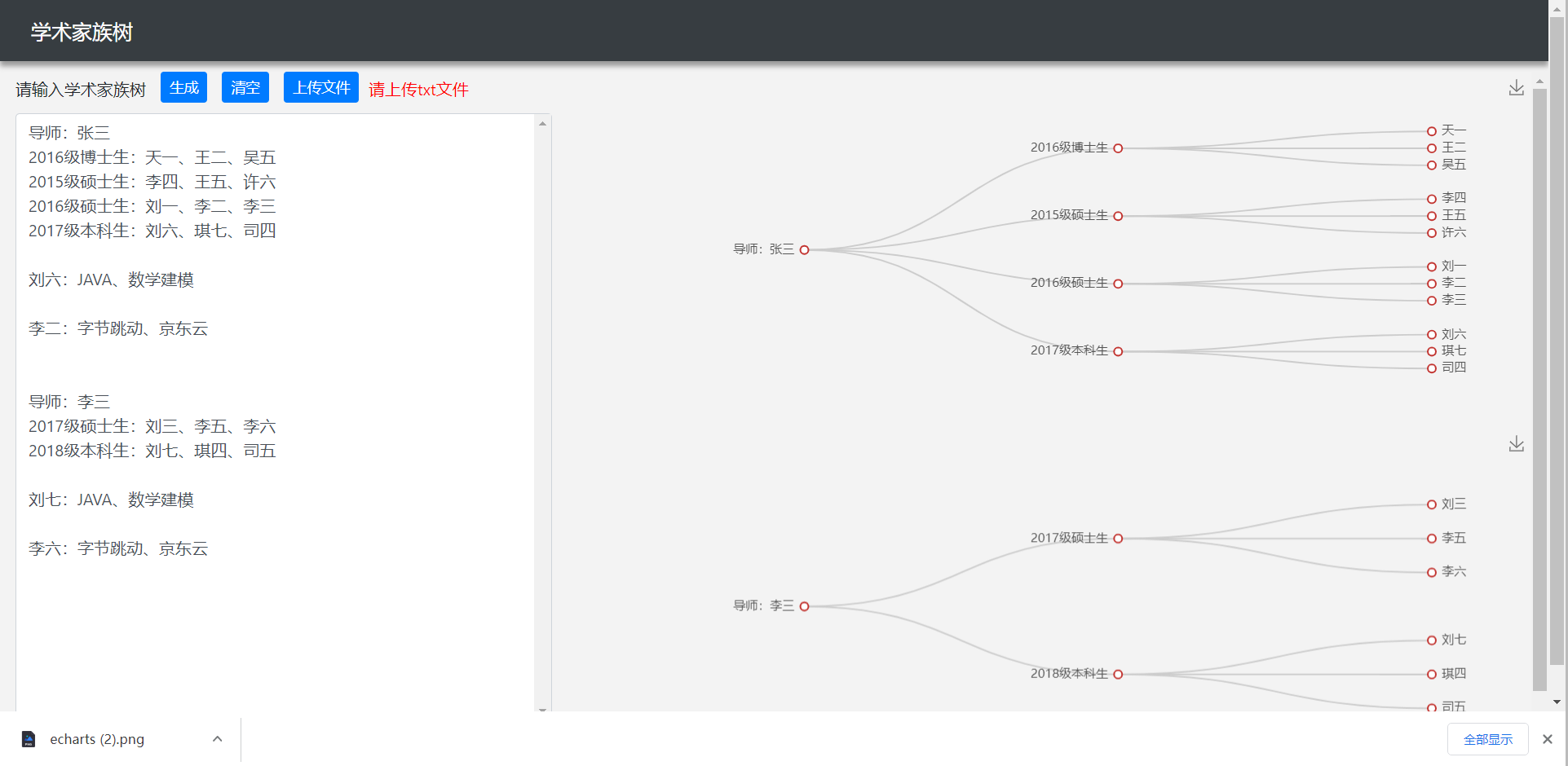
成果展示
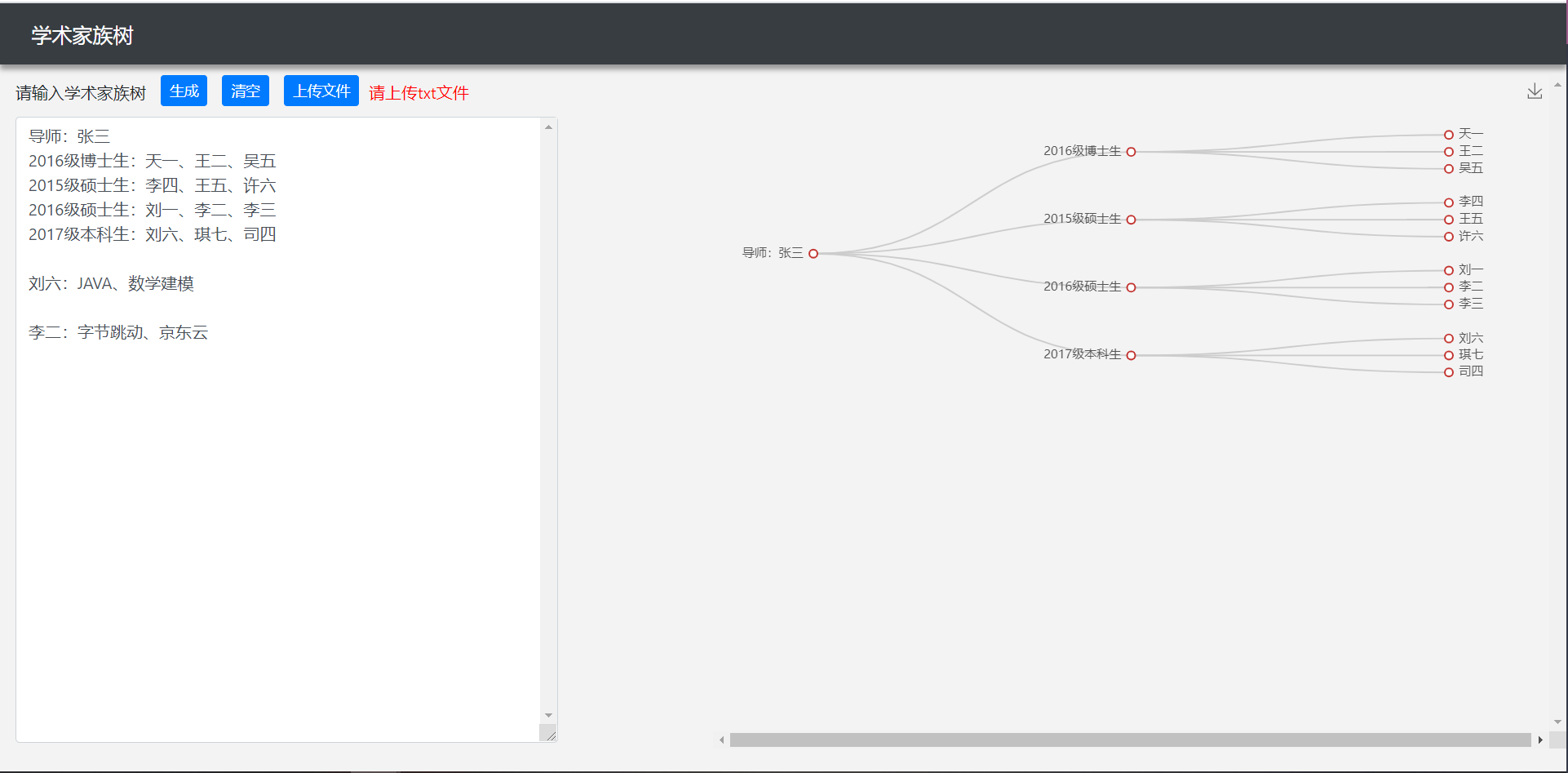
- 多棵树并存

- 点击节点可以显示技能或经历

- 文件上传

- 保存家族树图(每棵树对应一张图)
六、目录及使用说明
├── public index.html
├── css
│ ├── bootstrap.min.css
│ └── global.css
└── js
├── echarts.min.js
├── global.js
└── jquery-3.4.1.js
- css目录中放的是index页面使用到的样式,包括了bootstrap和自己编写的一些全局样式。
- js目录中放的是javascript文件,echarts.js帮助我们快速生成树状图,global.js负责字符串的解析和树状图的呈现,jquery-3.4.1.js让我们更方便的操作dom。
- test目录中放的是测试的代码
- 使用说明:index.html是主页面,用户直接双击文件夹中的index.html或右键选择浏览器打开就能运行我们的网页。
七、单元测试
- 选用框架: mocha
简易教程
- 安装并配置 node.js, 具体可参照 https://blog.csdn.net/zjh_746140129/article/details/80460965?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-6.add_param_isCf&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-6.add_param_isCf
- (可选) 国内npm源速度较慢,可以配置淘宝镜像,具体可参照https://developer.aliyun.com/mirror/NPM?from=tnpm
- 如果前端项目没有使用npm构建,那么需要单独创建测试项目
node init - 全局安装mocha
npm install --global mocha - 将要测试的js拷贝到测试项目根目录,并创建 test 文件夹
- 在要测试的js文件中导出要测试的函数(比如要测试parse函数)
- 编写测试文件,可参照https://www.liaoxuefeng.com/wiki/1022910821149312/1101756368943712
- 在根目录输入
mocha,运行测试
部分测试代码
describe('#global.js', () => {
describe('异常情况', () => {
it('导师信息异常', () => {
assert.throws(() => {
testJs.parse(`张三
2016级博士生:天一、王二、吴五、A
2015级硕士生:李四、王五、许六
2016级硕士生:刘一、李二、李三
2017级本科生:刘六、琪七
刘六:JAVA、数学建模
李二:字节跳动、京东云
王二: Python`)
}, Error);
});
利用 mocha 提供的describe 函数和 node.js 提供的 assert 进行单元测试,assert.throws代表期望抛出异常。运行mocha后,将会自动运行所有测试(由于使用了模板字符串,所以缩进有些混乱)
- 运行结果

测试思路
- 测试数据主要被分为了正常情况和异常情况,正常情况主要构造了单棵树和多棵数的测试数据,对于异常情况,因为这次的数据完全由用户输入,所以需要考虑的异常情况较多,因此针对各种格式错误构造了比较多的异常数据进行测试。例如输入不存在的数据,符号用了英文的符号,关键词不正确等异常。
- 应对测试的***难:得益于全局的异常处理,对于没考虑到的异常也会被捕获并打印在绘图区,只是提示信息不够友好,测试人员可以根据该异常信息判断问题。
八、github记录

九、遇到的问题和解决方法
- 问题一:css没写好没用好,页面布局没有达到想要的效果,不好看(虽然改完也不好看但是比一开始好),后来查文档,百度样式,搜索视频,参考其他页面的样式解决了这个问题。
- 问题二:测试的时候发现,通过" "拼接的字符串可以通过测试,但是同样的文字使用模板字符串就无法通过测试,经过询问同学以及大量的日志调试后,发现是原本以为是空行的地方被 VSCode 自动加上了空格符进行缩进,导致解析不正确。最后删去多余的缩进后问题解决。这个小坑让我更深入的理解了 ES6 的模板字符串的相关特性,毕竟平时前端写的少,js这块的知识也是东缺一块西缺一块的。
十、评价队友
- 值得学习的地方:我的队友就是大腿了,实力抱腿,他的代码熟练程度和学习能力是值得我学习的。
- 需要改进的地方:我的队友要注重代码细节,才不会总有小问题。我需要多接触一些现代前端开发的知识,如三大框架,前端工程化等
