2020软工实践第一次个人编程作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/SE2020 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/SE2020/homework/11167 |
| 这个作业的目标 | 总结软工的第一次个人编程作业 |
| 学号 | 031802223 |
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| Estimate | 估计这个任务需要多少时间 | 30 | 25 |
| Development | 开发 | ||
| Analysis | 需求分析 (包括学习新技术) | 60 | 120 |
| Design Spec | 生成设计文档 | 60 | 90 |
| Design Review | 设计复审 | 30 | 40 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 60 | 30 |
| Design | 具体设计 | 30 | 30 |
| Coding | 具体编码 | 360 | 400 |
| Code Review | 代码复审 | 30 | 60 |
| Test | 测试(自我测试,修改代码,提交修改) | 120 | 300 |
| Reporting | 报告 | ||
| Test Report | 测试报告 | 20 | 15 |
| Size Measurement | 计算工作量 | 30 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 100 | 150 |
| 合计 | 930 | 1290 |
二、解题思路
题目要求我们从GitHub用户行为数据中统计出每个人的、每个项目的、以及每个人的每个项目的四种事件的数量,并且需要存储结果,因此我打算将统计结果存入json文件中,需要查询时直接解析。
- 任务要求与技术选择
任务首先得有文件读取,其次是解析json串,将提取出的数据保存起来,最后还得解析main函数传入的参数,了解了项目需要的依赖就可以导包了,文件读取与写入我选择了commons-io有丰富的封装好的io操作,json的序列化和反序列化以及参数解析我分别选择了fastjson和common-cli有文档的直接查了文档就可以开始用了,没文档的上百度查例子学着用。 - 具体思路
先通过commons-cli解析命令行参数,进而决定需要执行什么操作。如果是初始化操作,就使用commons-io读取文件夹中的json文件并将文件存入HashMap中,统计完毕后,将所有HashMap序列化后存入各自的json文件中。如果是查询操作,只需要读取对应的json文件输出结果即可。
三、设计实现过程
项目初始为单线程版本,后迭代为多线程版本。
1.单线程版本
只有Main和Result两个类,所有业务写在Main中,逻辑简单,没有进行单元测试,效率也很一般
2.多线程版本
为了提高初始化统计数据的效率,我使用了多线程来初始化。于是多了类FileHandlerThread,用于解析json文件
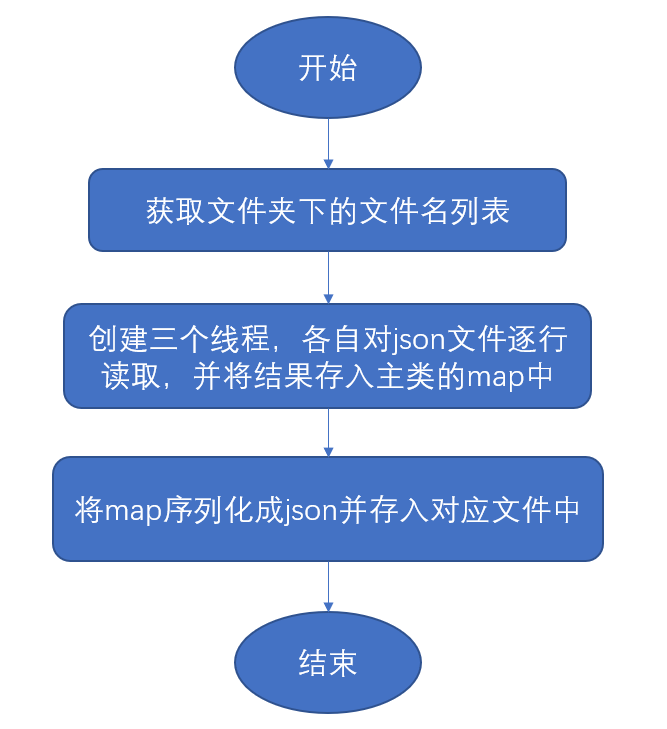
- 初始化过程
主类会获取文件夹中的文件名的列表,创建三个线程,分别分配下标0,1,2,每次执行完后下标自动+3,当下标超过列表大小后,停止解析。每个线程对应一个json文件,统计结果会存入主类的concurrentHashMap中,三个线程的hashMap是同步的。最后由主类将hashMap序列化存入json文件中 - 关键流程(init()方法)
- 不足之处:且每个线程只能解析属于自己下标类的文件,比如线程1只能解析下标为0、3、6...的文件,如果这些下标的文件相比其他文件大小区别较大的话,就会出现两个线程空闲着而不帮另一个线程解析文件,此时效率相比单线程几乎没有提升。
- 我考虑过使用AtomicInteger作为公共的文件下标,每个线程使用一次后自动+1,但是这样会出现同一个下标的文件被解析两次的情况,如果锁住该变量,又会出现后一个线程必须等待前一个线程执行完毕才能执行的情况,此时效率难以得到保证,于是我舍弃了这个想法,维持了一开始的做法。
四、代码说明
1.main()方法
public static void main(String[] args) {
//解析参数
Options options = new Options();
options.addOption("i","init",true,"pathToData")
.addOption("u","user",true,"username")
.addOption("e","event",true,"eventType")
.addOption("r","repo",true,"repoName");
CommandLineParser parser = new DefaultParser();
try {
CommandLine cmd = parser.parse( options, args);
//如果参数中存在-i说明是初始化操作
if(cmd.hasOption('i')){
String path = cmd.getOptionValue('i');
init(path);
}else {//参数中未存在i说明是查询操作
String eventType = cmd.getOptionValue('e');
if(eventType!=null) {
//如果有-u参数
if (cmd.hasOption('u')) {
String username = cmd.getOptionValue('u');
//如果有-u参数还有-r参数说明要查询某个用户某个项目的事件数量
if (cmd.hasOption('r')) {
String repoName = cmd.getOptionValue('r');
System.out.println(getPersonalAndRepoThings(username,repoName,eventType));
} else {//如果没有-r参数说明只查询了某个用户的事件数量
System.out.println(getPersonalThings(username,eventType));
}
} else {//如果没有-u参数说明只查询了某个项目的事件数量
String repoName = cmd.getOptionValue('r');
System.out.println(getRepoThings(repoName,eventType));
}
}
}
} catch (ParseException | IOException e) {
e.printStackTrace();
}
}
- 通过commons-cli的DefaultParser类和Option类解析参数,并根据不同的传参情况调用不同的方法。
2.init()方法
static void init(String path){
try {
File file = new File(path);
//获得文件夹中的文件名的集合
List<String> fileNames = Arrays.asList(Objects.requireNonNull(file.list()));
///创建三个线程共同解析文件夹中的json文件
FileHandleThread fileHandleThread1 = new FileHandleThread(userToResult,repoToResult,userAndRepoToResult,fileNames,path,0);
FileHandleThread fileHandleThread2 = new FileHandleThread(userToResult,repoToResult,userAndRepoToResult,fileNames,path,1);
FileHandleThread fileHandleThread3 = new FileHandleThread(userToResult,repoToResult,userAndRepoToResult,fileNames,path,2);
Thread thread = new Thread(fileHandleThread1);
Thread thread1 = new Thread(fileHandleThread2);
Thread thread2 = new Thread(fileHandleThread3);
thread.start();
thread1.start();
thread2.start();
thread.join();
thread1.join();
thread2.join();
//将三个map中的数据存入各自的json文件中,实现持久化
FileUtils.writeStringToFile(new File("userToResult.json"), JSON.toJSONString(userToResult),"UTF-8",false);
FileUtils.writeStringToFile(new File("repoToResult.json"), JSON.toJSONString(repoToResult),"UTF-8",false);
FileUtils.writeStringToFile(new File("userAndRepoToResult.json"), JSON.toJSONString(userAndRepoToResult),"UTF-8",false);
} catch (InterruptedException | IOException e) {
e.printStackTrace();
}
- init()方法直接显式创建并运行三个线程,各自解析彼此不同的下标下的json文件,main的主线程需要在子线程解析完毕后再对map序列化,因此得join()三个线程,保证线程间的同步。
- fastjson序列化对象成json串时,需要对象的类实现了getter()和setter(),我之前使用了lombok注解自动生成了这些方法,后来发现不起作用了(应该是插件的问题),后来我老实写了这些方法,就把序列化失败的问题解决了。
3.FileHandlerThread的run()方法
public void run() {
while(num<fileNum){
try {
//获得本次解析的文件名
String fileName = fileNames.get(num);
//得是json文件才能被解析
if(fileName.endsWith(".json")) {
//获得文件的行迭代器,可以逐行读取文件
LineIterator it = FileUtils.lineIterator(new File(path + "/" + fileName), "UTF-8");
//如果行迭代器还未到文件结尾
while (it.hasNext()) {
//解析当前迭代器的一行,迭代器自动往下移动一行
JSONObject jsonObject = JSONObject.parseObject(it.nextLine());
//获得json的type属性
String type = jsonObject.getString("type");
//事件类型应该是四种事件中的一种
if (typeCorrect(type)) {
//获得actor的login属性
String username = jsonObject.getJSONObject("actor").getString("login");
Result userResult = userToResult.get(username);
//先要判断集合中该用户的结果对象是否有被创建
if (userResult == null) {
//没有创建需要创建
userResult = new Result();
//增加该结果对象的对应事件的数量
userResult.inc(type);
//将新创建的对象放回map中
userToResult.put(username, userResult);
} else {
//如果集合中已经存在了该用户的对象,直接增加该结果对象的对应事件的数量即可
userResult.inc(type);
}
//同上,只是map的键变成了项目名repoName
String repoName = jsonObject.getJSONObject("repo").getString("name");
Result repoResult = repoToResult.get(repoName);
if (repoResult == null) {
repoResult = new Result();
repoResult.inc(type);
repoToResult.put(repoName, repoResult);
} else {
repoResult.inc(type);
}
//同上,只是map的键变成了用户名+项目名
String name = username + "_" + repoName;
Result result = userAndRepoToResult.get(name);
if (result == null) {
result = new Result();
result.inc(type);
userAndRepoToResult.put(name, result);
} else {
result.inc(type);
}
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
//执行完毕后(无论有无报错)下标自动加3,保证三个线程互不干扰,各自解析属于自己下标的json文件
num+=3;
}
}
线程类继承了Runnable接口,每个线程对象中保存了当前解析的文件的下标,当下标等于或超过文件列表大小,就结束解析。LineIterator可以对文件逐行读取,每次读取一行的json数据,使用fastjson中JsonObject类的静态方法解析json,对题目要求的数据进行统计,最后存入主类的concurrentHashMap中。
五、单元测试
1.单元测试截图和描述
单元测试对初始化和三个查询的方法进行了测试,还测试了传入参数不合法的情况
- 测试截图
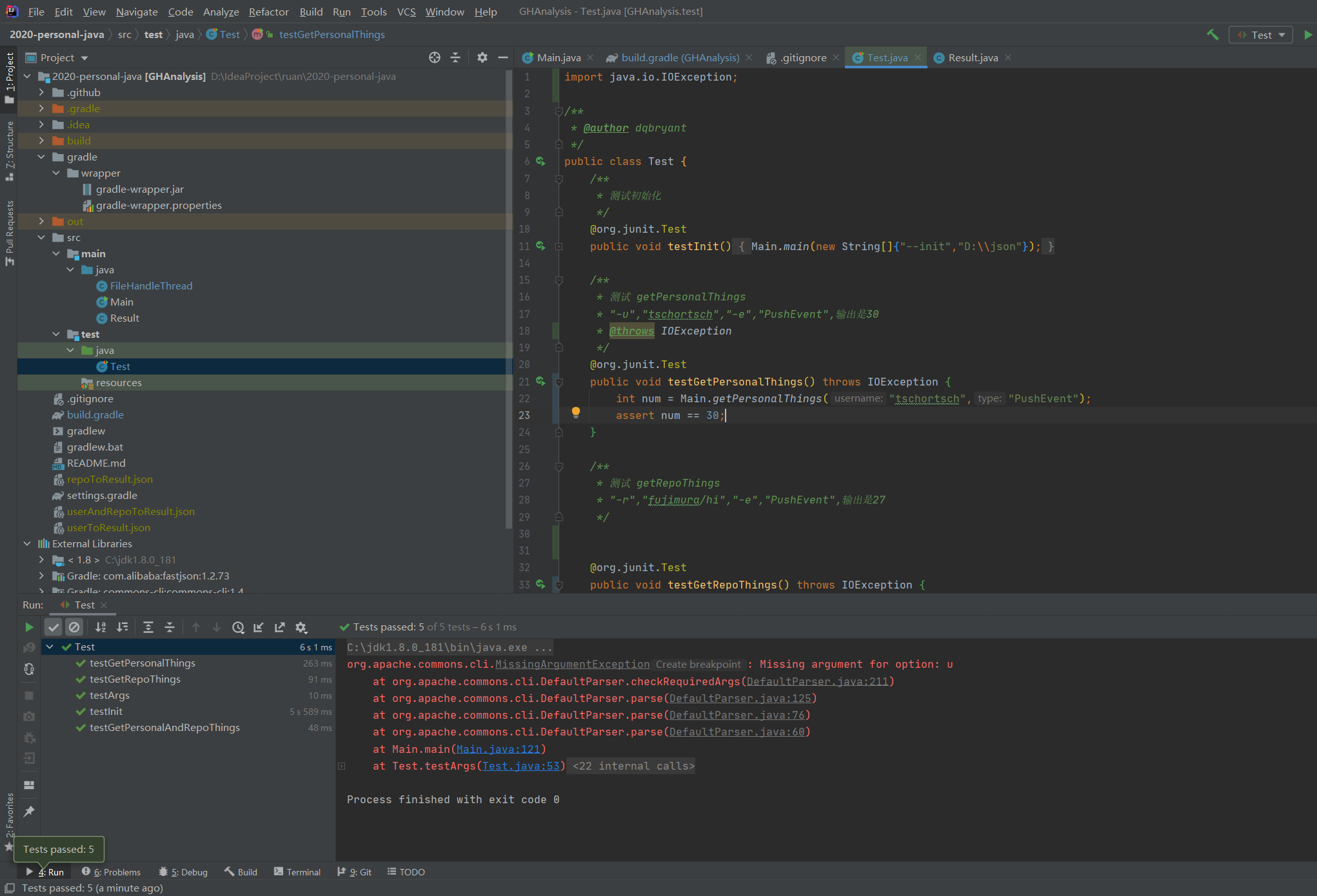
打印了异常属于意料之内的结果,所以测试均符合预期。
2.单元测试覆盖率
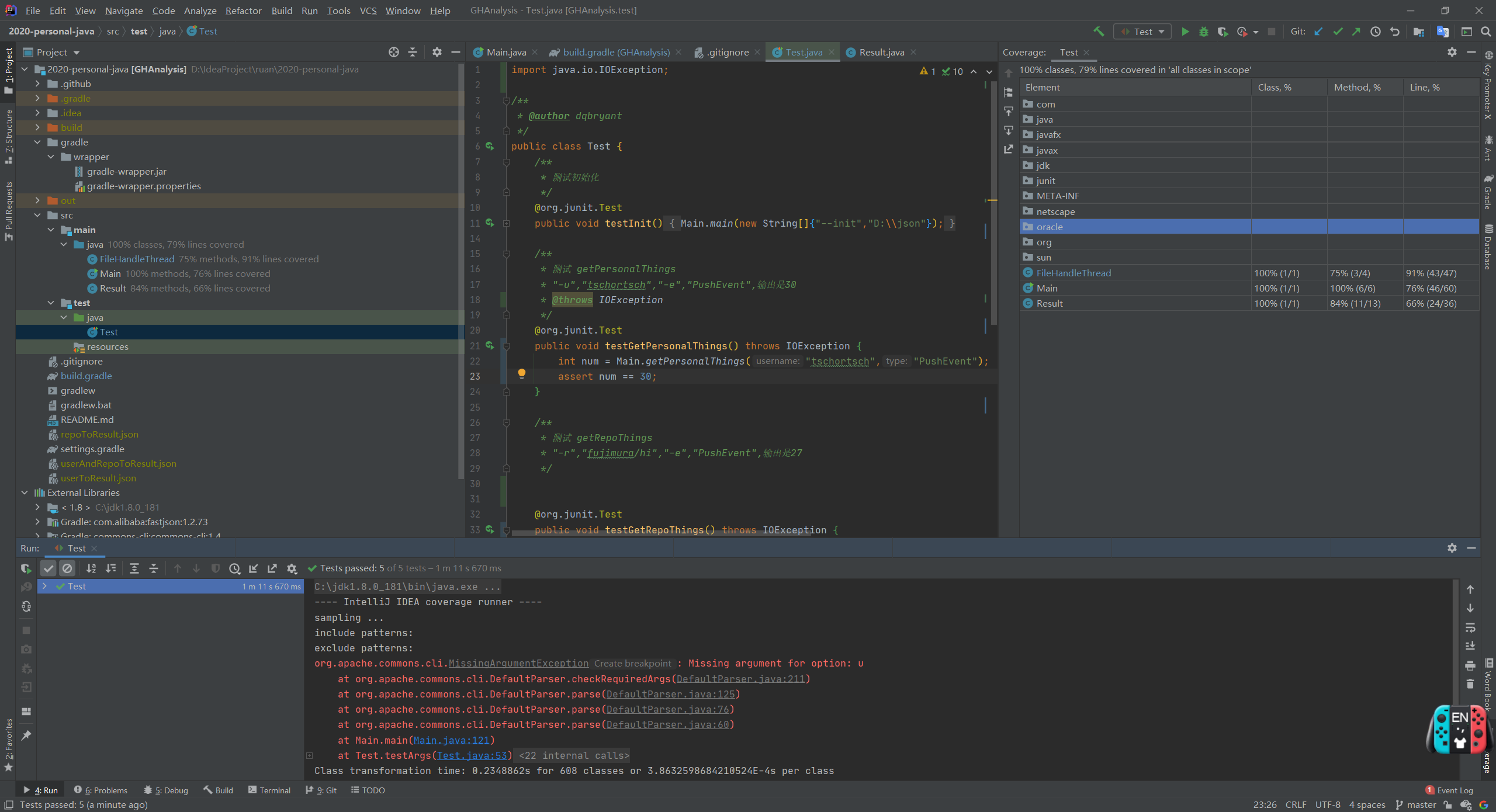
- 单元测试覆盖率达到了79%(不知道为啥这么低)
3.性能优化截图和描述
- 使用的测试数据为3个相同的json文件,每个大小都约为500MB,总共1500MB,初始化init()占据了主要时间,也只有init()能被优化
- 单线程执行时间

单线程情况下大约花费10500ms ~ 11000ms - 多线程执行时间
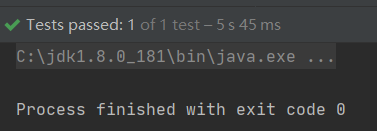
多线程情况下花费了5000ms~5700ms,明显对比得到多线程情况下初始化时间能减少近50% - 多线程可能出现的问题
- 使用多线程就不可避免的会出现线程不同步的问题,比如不同线程同时对同一个主类的map进行put操作时,就会有并发问题,对此我使用了ConcurrentHashMap代替了普通的HashMap,从而保证了put方法的原子性。
- 当不同线程同时修改同一个结果对象的属性时,同样会因为并发导致有的值未修改成功,最后导致统计的数量较真实的数量少,我使用了synchronized修饰了Result类的inc方法, 杜绝了不同线程同时获得result对象控制权的情况。
六、代码规范链接
https://github.com/DQbryant/2020-personal-java/blob/master/codestyle.md
七、作业总结
- 如果之前有一些Java和Python基础的话,这次编程作业应该没有太大问题,只要会调第三方库很容易就能搞定基本内容,使用第三方库意味着我需要学会如何查看文档,这次编程作业锻炼了我查文档看文档的能力。
- 这次作业要求我们提交到gitHub,并用gradle代替maven,所以我在b站上自学了这两部分的内容。
- 多线程部分由于我许久未用,且了解不深,使用不熟练,花费了我不少时间,而且没用上线程池,对多线程的使用很不到位,这次作业后我会自学java juc的内容,希望在今后项目上能派上用场。
- 有一段时间没写过普通的Java程序了,这次作业让我必须回顾以前学过的内容,也锻炼了我解决问题的能力,相信之后再写Java程序就不会那么生疏。

